 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookahead Sample Reward Guidance for Test-Time Scaling of Diffusion Models
Feb 03, 2026Diffusion models have demonstrated strong generative performance; however, generated samples often fail to fully align with human intent. This paper studies a test-time scaling method that enables sampling from regions with higher human-aligned reward values. Existing gradient guidance methods approximate the expected future reward (EFR) at an intermediate particle $\mathbf{x}_t$ using a Taylor approximation, but this approximation at each time step incurs high computational cost due to sequential neural backpropagation. We show that the EFR at any $\mathbf{x}_t$ can be computed using only marginal samples from a pre-trained diffusion model. The proposed EFR formulation detaches the neural dependency between $\mathbf{x}_t$ and the EFR, enabling closed-form guidance computation without neural backpropagation. To further improve efficiency, we introduce lookahead sampling to collect marginal samples. For final sample generation, we use an accurate solver that guides particles toward high-reward lookahead samples. We refer to this sampling scheme as LiDAR sampling. LiDAR achieves substantial performance improvements using only three samples with a 3-step lookahead solver, exhibiting steep performance gains as lookahead accuracy and sample count increase; notably, it reaches the same GenEval performance as the latest gradient guidance method for SDXL with a 9.5x speedup.
Semantic-aware Wasserstein Policy Regularization for Large Language Model Alignment
Feb 02, 2026Large language models (LLMs) are commonly aligned with human preferences using reinforcement learning from human feedback (RLHF). In this method, LLM policies are generally optimized through reward maximization with Kullback-Leibler (KL) divergence regularization of the reference policy. However, KL and its $f$-divergence variants only compare token probabilities at identical indices, failing to capture semantic similarity. We propose Wasserstein Policy Regularization (WPR), a semantic-aware regularization for the RLHF framework based on the entropy-regularized Wasserstein distance, which incorporates the geometry of the token space. The dual formulation of the distance expresses the regularization as penalty terms applied to the reward via optimal dual variables, which yield a tractable objective compatible with standard RL algorithms. Empirically, our method outperforms KL- and $f$-divergence-based baselines, demonstrating the benefits of semantic-aware policy distances for alignment. Our code is available at https://github.com/aailab-kaist/WPR.
Preference Optimization by Estimating the Ratio of the Data Distribution
May 26, 2025Direct preference optimization (DPO) is widely used as a simple and stable method for aligning large language models (LLMs) with human preferences. This paper investigates a generalized DPO loss that enables a policy model to match the target policy from a likelihood ratio estimation perspective. The ratio of the target policy provides a unique identification of the policy distribution without relying on reward models or partition functions. This allows the generalized loss to retain both simplicity and theoretical guarantees, which prior work such as $f$-PO fails to achieve simultaneously. We propose Bregman preference optimization (BPO), a generalized framework for ratio matching that provides a family of objective functions achieving target policy optimality. BPO subsumes DPO as a special case and offers tractable forms for all instances, allowing implementation with a few lines of code. We further develop scaled Basu's power divergence (SBA), a gradient scaling method that can be used for BPO instances. The BPO framework complements other DPO variants and is applicable to target policies defined by these variants. In experiments, unlike other probabilistic loss extensions such as $f$-DPO or $f$-PO, which exhibit a trade-off between generation fidelity and diversity, instances of BPO improve both win rate and entropy compared with DPO. When applied to Llama-3-Instruct-8B, BPO achieves state-of-the-art performance among Llama-3-8B backbones, with a 55.9\% length-controlled win rate on AlpacaEval2.
Autoregressive Distillation of Diffusion Transformers
Apr 15, 2025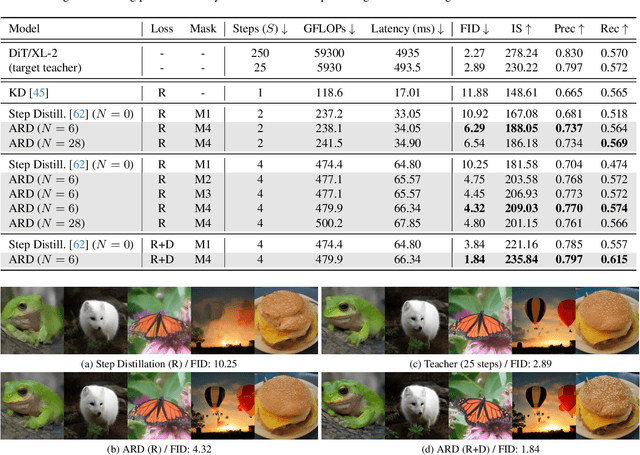
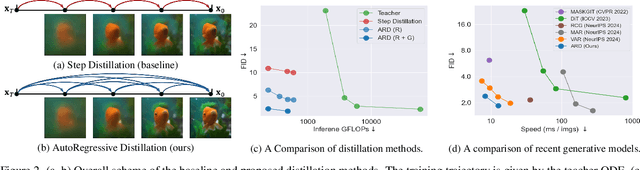
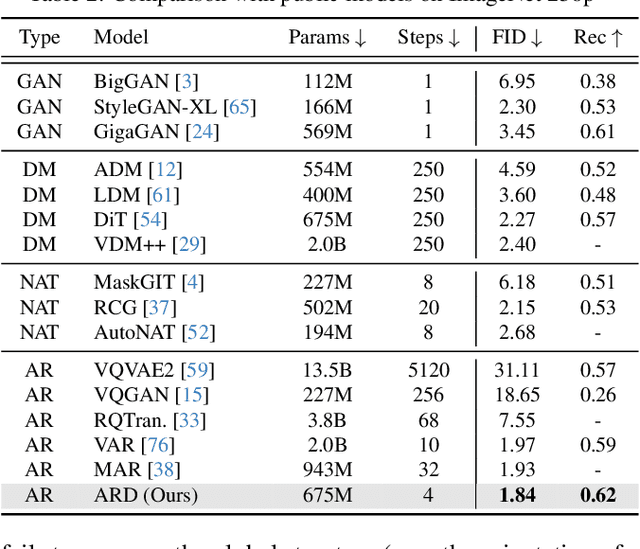
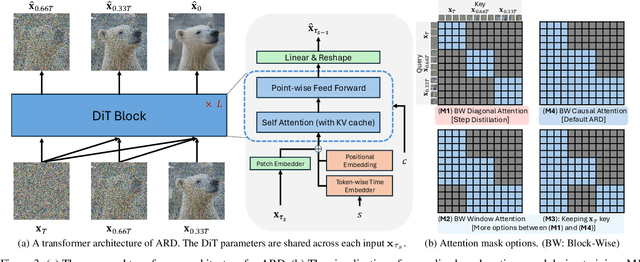
Diffusion models with transformer architectures have demonstrated promising capabilities in generating high-fidelity images and scalability for high resolution. However, iterative sampling process required for synthesis is very resource-intensive. A line of work has focused on distilling solutions to probability flow ODEs into few-step student models. Nevertheless, existing methods have been limited by their reliance on the most recent denoised samples as input, rendering them susceptible to exposure bias. To address this limitation, we propose AutoRegressive Distillation (ARD), a novel approach that leverages the historical trajectory of the ODE to predict future steps. ARD offers two key benefits: 1) it mitigates exposure bias by utilizing a predicted historical trajectory that is less susceptible to accumulated errors, and 2) it leverages the previous history of the ODE trajectory as a more effective source of coarse-grained information. ARD modifies the teacher transformer architecture by adding token-wise time embedding to mark each input from the trajectory history and employs a block-wise causal attention mask for training. Furthermore, incorporating historical inputs only in lower transformer layers enhances performance and efficiency. We validate the effectiveness of ARD in a class-conditioned generation on ImageNet and T2I synthesis. Our model achieves a $5\times$ reduction in FID degradation compared to the baseline methods while requiring only 1.1\% extra FLOPs on ImageNet-256. Moreover, ARD reaches FID of 1.84 on ImageNet-256 in merely 4 steps and outperforms the publicly available 1024p text-to-image distilled models in prompt adherence score with a minimal drop in FID compared to the teacher. Project page: https://github.com/alsdudrla10/ARD.
FlexiDiT: Your Diffusion Transformer Can Easily Generate High-Quality Samples with Less Compute
Feb 27, 2025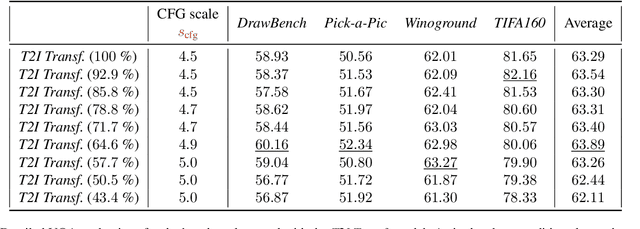

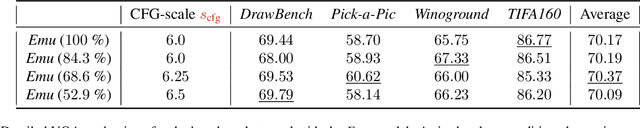

Despite their remarkable performance, modern Diffusion Transformers are hindered by substantial resource requirements during inference, stemming from the fixed and large amount of compute needed for each denoising step. In this work, we revisit the conventional static paradigm that allocates a fixed compute budget per denoising iteration and propose a dynamic strategy instead. Our simple and sample-efficient framework enables pre-trained DiT models to be converted into \emph{flexible} ones -- dubbed FlexiDiT -- allowing them to process inputs at varying compute budgets. We demonstrate how a single \emph{flexible} model can generate images without any drop in quality, while reducing the required FLOPs by more than $40$\% compared to their static counterparts, for both class-conditioned and text-conditioned image generation. Our method is general and agnostic to input and conditioning modalities. We show how our approach can be readily extended for video generation, where FlexiDiT models generate samples with up to $75$\% less compute without compromising performance.
Reward-based Input Construction for Cross-document Relation Extraction
May 31, 2024Relation extraction (RE) is a fundamental task in natural language processing, aiming to identify relations between target entities in text. While many RE methods are designed for a single sentence or document, cross-document RE has emerged to address relations across multiple long documents. Given the nature of long documents in cross-document RE, extracting document embeddings is challenging due to the length constraints of pre-trained language models. Therefore, we propose REward-based Input Construction (REIC), the first learning-based sentence selector for cross-document RE. REIC extracts sentences based on relational evidence, enabling the RE module to effectively infer relations. Since supervision of evidence sentences is generally unavailable, we train REIC using reinforcement learning with RE prediction scores as rewards. Experimental results demonstrate the superiority of our method over heuristic methods for different RE structures and backbones in cross-document RE. Our code is publicly available at https://github.com/aailabkaist/REIC.
Diffusion Rejection Sampling
May 28, 2024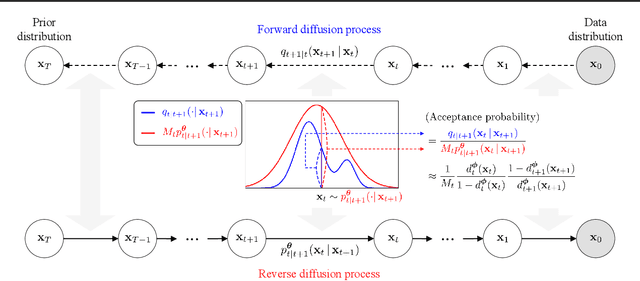
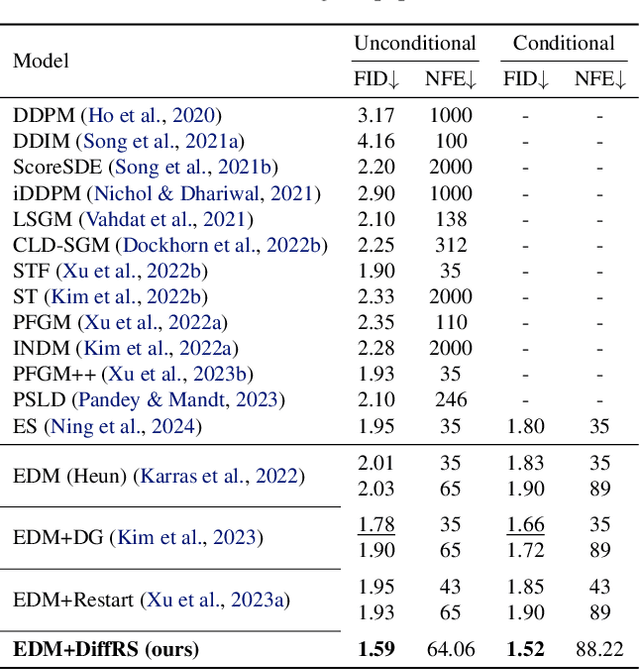
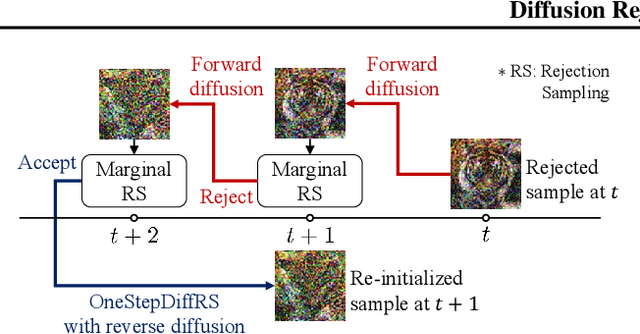
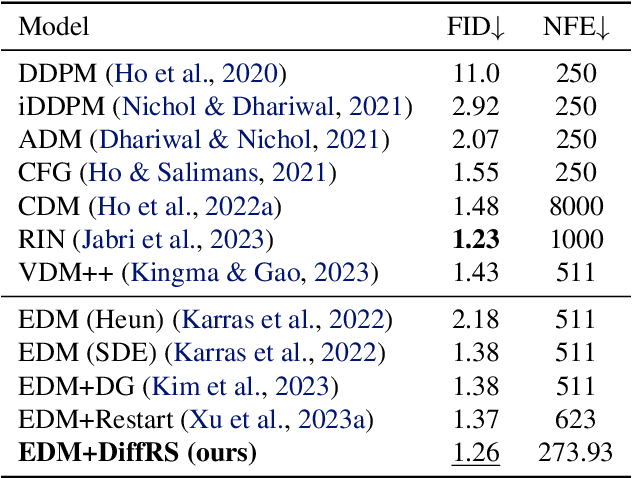
Recent advances in powerful pre-trained diffusion models encourage the development of methods to improve the sampling performance under well-trained diffusion models. This paper introduces Diffusion Rejection Sampling (DiffRS), which uses a rejection sampling scheme that aligns the sampling transition kernels with the true ones at each timestep. The proposed method can be viewed as a mechanism that evaluates the quality of samples at each intermediate timestep and refines them with varying effort depending on the sample. Theoretical analysis shows that DiffRS can achieve a tighter bound on sampling error compared to pre-trained models. Empirical results demonstrate the state-of-the-art performance of DiffRS on the benchmark datasets and the effectiveness of DiffRS for fast diffusion samplers and large-scale text-to-image diffusion models. Our code is available at https://github.com/aailabkaist/DiffRS.
Diffusion Bridge AutoEncoders for Unsupervised Representation Learning
May 27, 2024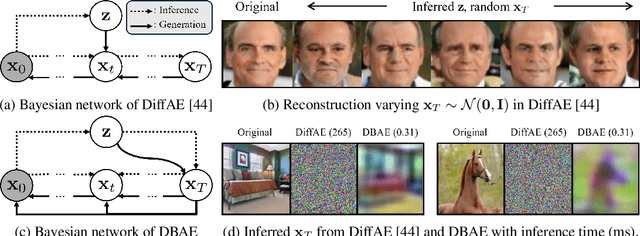
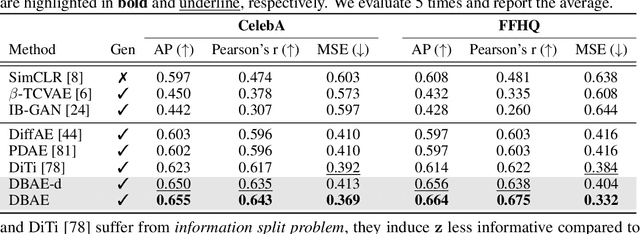
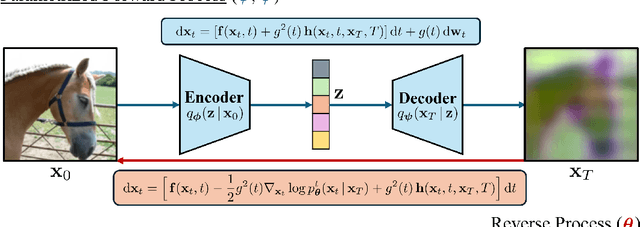
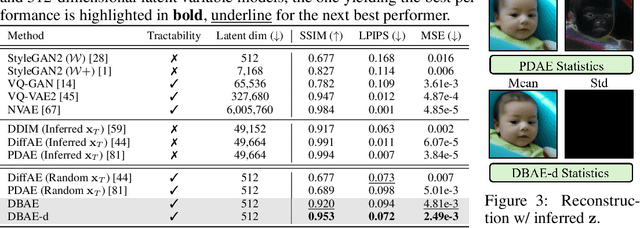
Diffusion-based representation learning has achieved substantial attention due to its promising capabilities in latent representation and sample generation. Recent studies have employed an auxiliary encoder to identify a corresponding representation from a sample and to adjust the dimensionality of a latent variable z. Meanwhile, this auxiliary structure invokes information split problem because the diffusion and the auxiliary encoder would divide the information from the sample into two representations for each model. Particularly, the information modeled by the diffusion becomes over-regularized because of the static prior distribution on xT. To address this problem, we introduce Diffusion Bridge AuteEncoders (DBAE), which enable z-dependent endpoint xT inference through a feed-forward architecture. This structure creates an information bottleneck at z, so xT becomes dependent on z in its generation. This results in two consequences: 1) z holds the full information of samples, and 2) xT becomes a learnable distribution, not static any further. We propose an objective function for DBAE to enable both reconstruction and generative modeling, with their theoretical justification. Empirical evidence supports the effectiveness of the intended design in DBAE, which notably enhances downstream inference quality, reconstruction, and disentanglement. Additionally, DBAE generates high-fidelity samples in the unconditional generation.
Training Unbiased Diffusion Models From Biased Dataset
Mar 02, 2024With significant advancements in diffusion models, addressing the potential risks of dataset bias becomes increasingly important. Since generated outputs directly suffer from dataset bias, mitigating latent bias becomes a key factor in improving sample quality and proportion. This paper proposes time-dependent importance reweighting to mitigate the bias for the diffusion models. We demonstrate that the time-dependent density ratio becomes more precise than previous approaches, thereby minimizing error propagation in generative learning. While directly applying it to score-matching is intractable, we discover that using the time-dependent density ratio both for reweighting and score correction can lead to a tractable form of the objective function to regenerate the unbiased data density. Furthermore, we theoretically establish a connection with traditional score-matching, and we demonstrate its convergence to an unbiased distribution. The experimental evidence supports the usefulness of the proposed method, which outperforms baselines including time-independent importance reweighting on CIFAR-10, CIFAR-100, FFHQ, and CelebA with various bias settings. Our code is available at https://github.com/alsdudrla10/TIW-DSM.
Label-Noise Robust Diffusion Models
Feb 27, 2024Conditional diffusion models have shown remarkable performance in various generative tasks, but training them requires large-scale datasets that often contain noise in conditional inputs, a.k.a. noisy labels. This noise leads to condition mismatch and quality degradation of generated data. This paper proposes Transition-aware weighted Denoising Score Matching (TDSM) for training conditional diffusion models with noisy labels, which is the first study in the line of diffusion models. The TDSM objective contains a weighted sum of score networks, incorporating instance-wise and time-dependent label transition probabilities. We introduce a transition-aware weight estimator, which leverages a time-dependent noisy-label classifier distinctively customized to the diffusion process. Through experiments across various datasets and noisy label settings, TDSM improves the quality of generated samples aligned with given conditions. Furthermore, our method improves generation performance even on prevalent benchmark datasets, which implies the potential noisy labels and their risk of generative model learning. Finally, we show the improved performance of TDSM on top of conventional noisy label corrections, which empirically proving its contribution as a part of label-noise robust generative models. Our code is available at: https://github.com/byeonghu-na/tdsm.