 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory-Class-Aware Multi-Agent Reinforcement Learning
Mar 03, 2025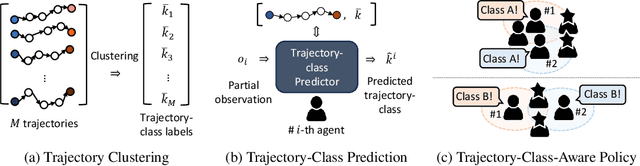


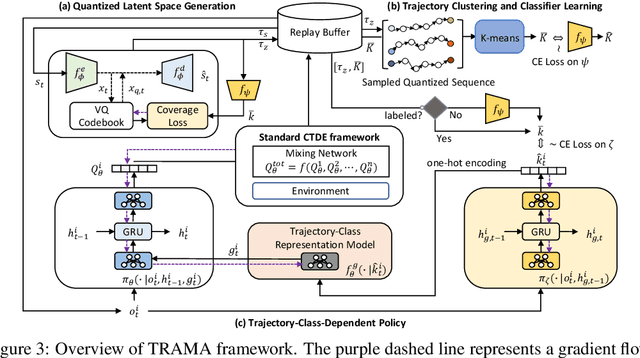
In the context of multi-agent reinforcement learning, generalization is a challenge to solve various tasks that may require different joint policies or coordination without relying on policies specialized for each task. We refer to this type of problem as a multi-task, and we train agents to be versatile in this multi-task setting through a single training process. To address this challenge, we introduce TRajectory-class-Aware Multi-Agent reinforcement learning (TRAMA). In TRAMA, agents recognize a task type by identifying the class of trajectories they are experiencing through partial observations, and the agents use this trajectory awareness or prediction as additional information for action policy. To this end, we introduce three primary objectives in TRAMA: (a) constructing a quantized latent space to generate trajectory embeddings that reflect key similarities among them; (b) conducting trajectory clustering using these trajectory embeddings; and (c) building a trajectory-class-aware policy. Specifically for (c), we introduce a trajectory-class predictor that performs agent-wise predictions on the trajectory class; and we design a trajectory-class representation model for each trajectory class. Each agent takes actions based on this trajectory-class representation along with its partial observation for task-aware execution. The proposed method is evaluated on various tasks, including multi-task problems built upon StarCraft II. Empirical results show further performance improvements over state-of-the-art baselines.
Diffusion Bridge AutoEncoders for Unsupervised Representation Learning
May 27, 2024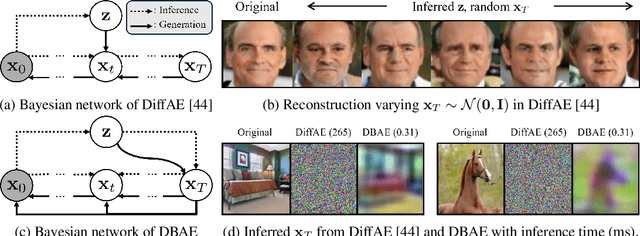
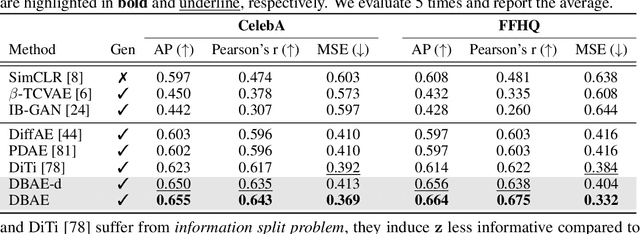
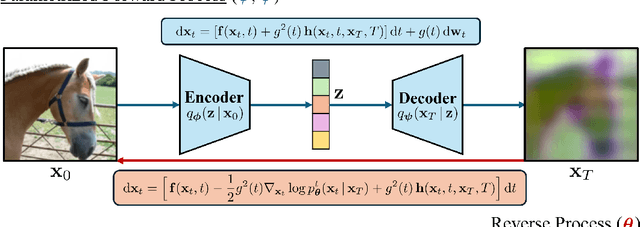
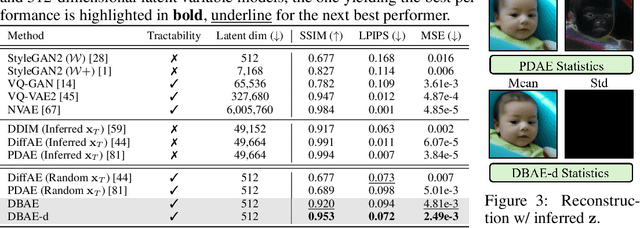
Diffusion-based representation learning has achieved substantial attention due to its promising capabilities in latent representation and sample generation. Recent studies have employed an auxiliary encoder to identify a corresponding representation from a sample and to adjust the dimensionality of a latent variable z. Meanwhile, this auxiliary structure invokes information split problem because the diffusion and the auxiliary encoder would divide the information from the sample into two representations for each model. Particularly, the information modeled by the diffusion becomes over-regularized because of the static prior distribution on xT. To address this problem, we introduce Diffusion Bridge AuteEncoders (DBAE), which enable z-dependent endpoint xT inference through a feed-forward architecture. This structure creates an information bottleneck at z, so xT becomes dependent on z in its generation. This results in two consequences: 1) z holds the full information of samples, and 2) xT becomes a learnable distribution, not static any further. We propose an objective function for DBAE to enable both reconstruction and generative modeling, with their theoretical justification. Empirical evidence supports the effectiveness of the intended design in DBAE, which notably enhances downstream inference quality, reconstruction, and disentanglement. Additionally, DBAE generates high-fidelity samples in the unconditional generation.