 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookahead Sample Reward Guidance for Test-Time Scaling of Diffusion Models
Feb 03, 2026Diffusion models have demonstrated strong generative performance; however, generated samples often fail to fully align with human intent. This paper studies a test-time scaling method that enables sampling from regions with higher human-aligned reward values. Existing gradient guidance methods approximate the expected future reward (EFR) at an intermediate particle $\mathbf{x}_t$ using a Taylor approximation, but this approximation at each time step incurs high computational cost due to sequential neural backpropagation. We show that the EFR at any $\mathbf{x}_t$ can be computed using only marginal samples from a pre-trained diffusion model. The proposed EFR formulation detaches the neural dependency between $\mathbf{x}_t$ and the EFR, enabling closed-form guidance computation without neural backpropagation. To further improve efficiency, we introduce lookahead sampling to collect marginal samples. For final sample generation, we use an accurate solver that guides particles toward high-reward lookahead samples. We refer to this sampling scheme as LiDAR sampling. LiDAR achieves substantial performance improvements using only three samples with a 3-step lookahead solver, exhibiting steep performance gains as lookahead accuracy and sample count increase; notably, it reaches the same GenEval performance as the latest gradient guidance method for SDXL with a 9.5x speedup.
Diffusion Rejection Sampling
May 28, 2024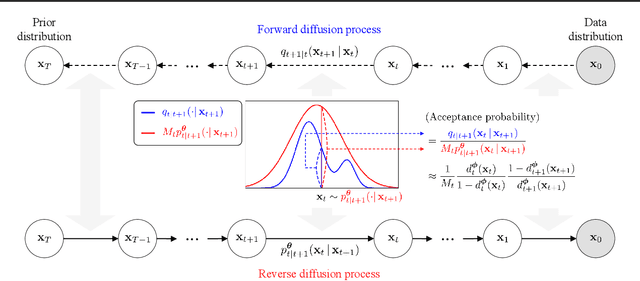
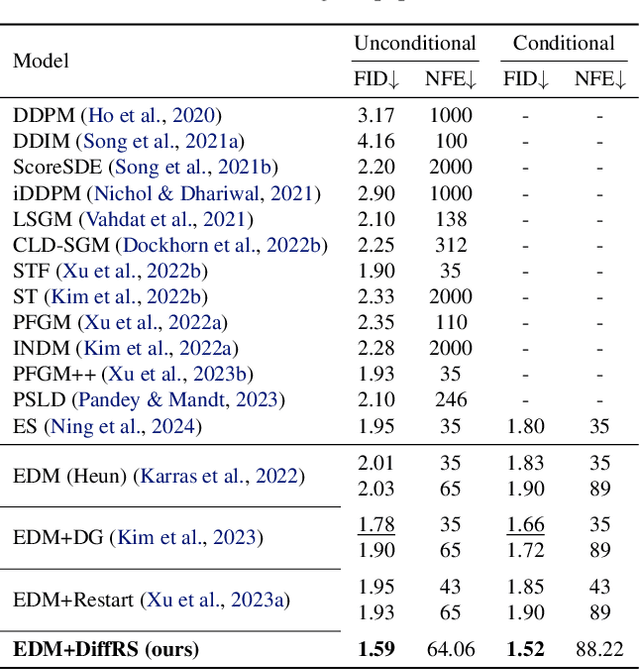
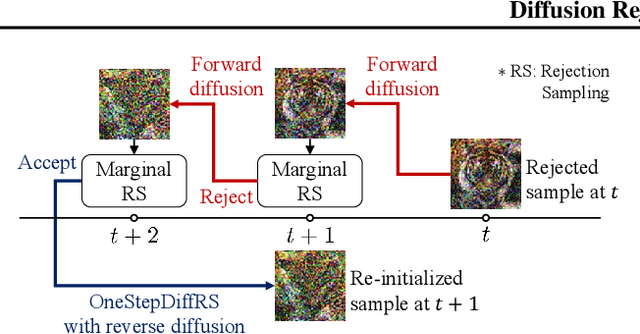
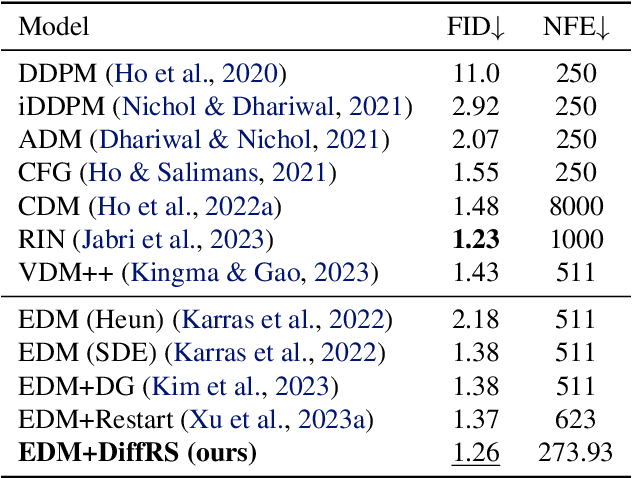
Recent advances in powerful pre-trained diffusion models encourage the development of methods to improve the sampling performance under well-trained diffusion models. This paper introduces Diffusion Rejection Sampling (DiffRS), which uses a rejection sampling scheme that aligns the sampling transition kernels with the true ones at each timestep. The proposed method can be viewed as a mechanism that evaluates the quality of samples at each intermediate timestep and refines them with varying effort depending on the sample. Theoretical analysis shows that DiffRS can achieve a tighter bound on sampling error compared to pre-trained models. Empirical results demonstrate the state-of-the-art performance of DiffRS on the benchmark datasets and the effectiveness of DiffRS for fast diffusion samplers and large-scale text-to-image diffusion models. Our code is available at https://github.com/aailabkaist/DiffRS.
Diffusion Bridge AutoEncoders for Unsupervised Representation Learning
May 27, 2024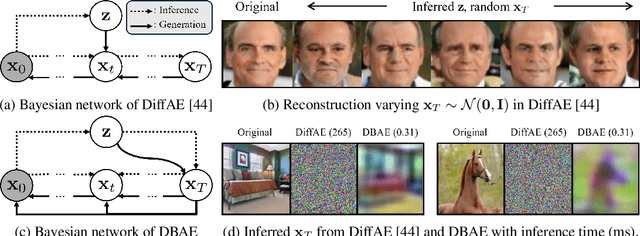
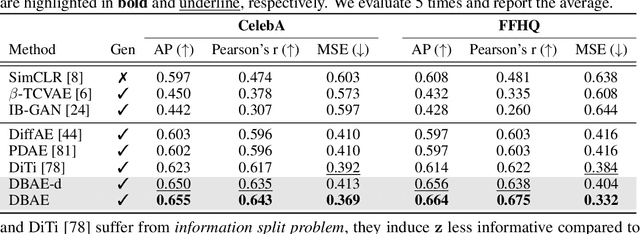
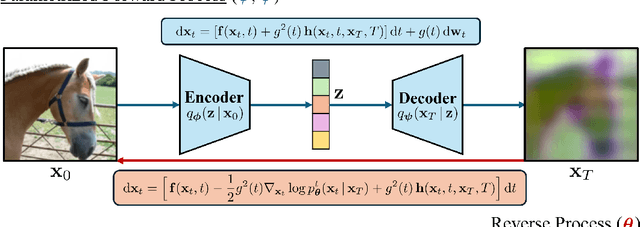
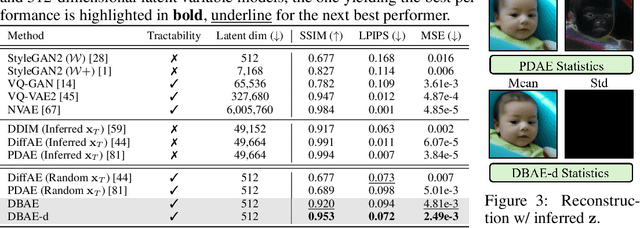
Diffusion-based representation learning has achieved substantial attention due to its promising capabilities in latent representation and sample generation. Recent studies have employed an auxiliary encoder to identify a corresponding representation from a sample and to adjust the dimensionality of a latent variable z. Meanwhile, this auxiliary structure invokes information split problem because the diffusion and the auxiliary encoder would divide the information from the sample into two representations for each model. Particularly, the information modeled by the diffusion becomes over-regularized because of the static prior distribution on xT. To address this problem, we introduce Diffusion Bridge AuteEncoders (DBAE), which enable z-dependent endpoint xT inference through a feed-forward architecture. This structure creates an information bottleneck at z, so xT becomes dependent on z in its generation. This results in two consequences: 1) z holds the full information of samples, and 2) xT becomes a learnable distribution, not static any further. We propose an objective function for DBAE to enable both reconstruction and generative modeling, with their theoretical justification. Empirical evidence supports the effectiveness of the intended design in DBAE, which notably enhances downstream inference quality, reconstruction, and disentanglement. Additionally, DBAE generates high-fidelity samples in the unconditional generation.
Training Unbiased Diffusion Models From Biased Dataset
Mar 02, 2024With significant advancements in diffusion models, addressing the potential risks of dataset bias becomes increasingly important. Since generated outputs directly suffer from dataset bias, mitigating latent bias becomes a key factor in improving sample quality and proportion. This paper proposes time-dependent importance reweighting to mitigate the bias for the diffusion models. We demonstrate that the time-dependent density ratio becomes more precise than previous approaches, thereby minimizing error propagation in generative learning. While directly applying it to score-matching is intractable, we discover that using the time-dependent density ratio both for reweighting and score correction can lead to a tractable form of the objective function to regenerate the unbiased data density. Furthermore, we theoretically establish a connection with traditional score-matching, and we demonstrate its convergence to an unbiased distribution. The experimental evidence supports the usefulness of the proposed method, which outperforms baselines including time-independent importance reweighting on CIFAR-10, CIFAR-100, FFHQ, and CelebA with various bias settings. Our code is available at https://github.com/alsdudrla10/TIW-DSM.