 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Dataset into Neural Field
Mar 05, 2025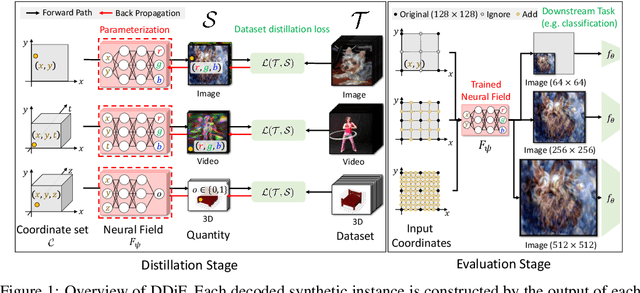
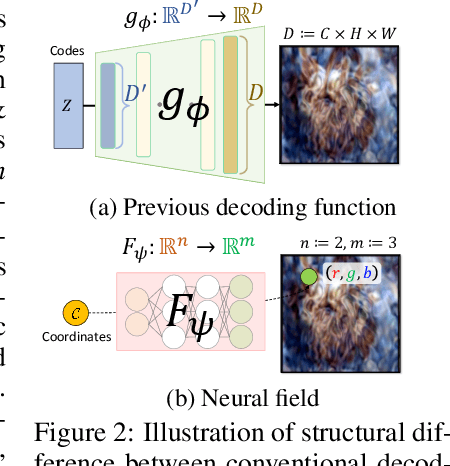

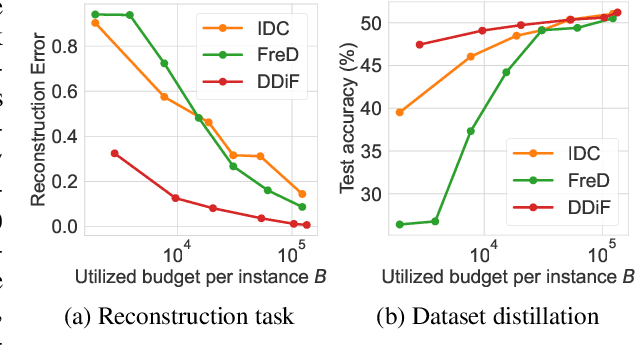
Utilizing a large-scale dataset is essential for training high-performance deep learning models, but it also comes with substantial computation and storage costs. To overcome these challenges, dataset distillation has emerged as a promising solution by compressing the large-scale dataset into a smaller synthetic dataset that retains the essential information needed for training. This paper proposes a novel parameterization framework for dataset distillation, coined Distilling Dataset into Neural Field (DDiF), which leverages the neural field to store the necessary information of the large-scale dataset. Due to the unique nature of the neural field, which takes coordinates as input and output quantity, DDiF effectively preserves the information and easily generates various shapes of data. We theoretically confirm that DDiF exhibits greater expressiveness than some previous literature when the utilized budget for a single synthetic instance is the same. Through extensive experiments, we demonstrate that DDiF achieves superior performance on several benchmark datasets, extending beyond the image domain to include video, audio, and 3D voxel. We release the code at https://github.com/aailab-kaist/DDiF.
Diffusion Rejection Sampling
May 28, 2024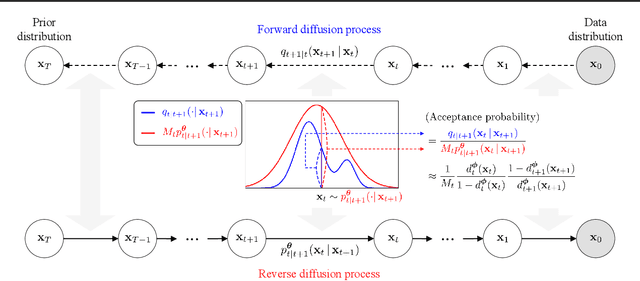
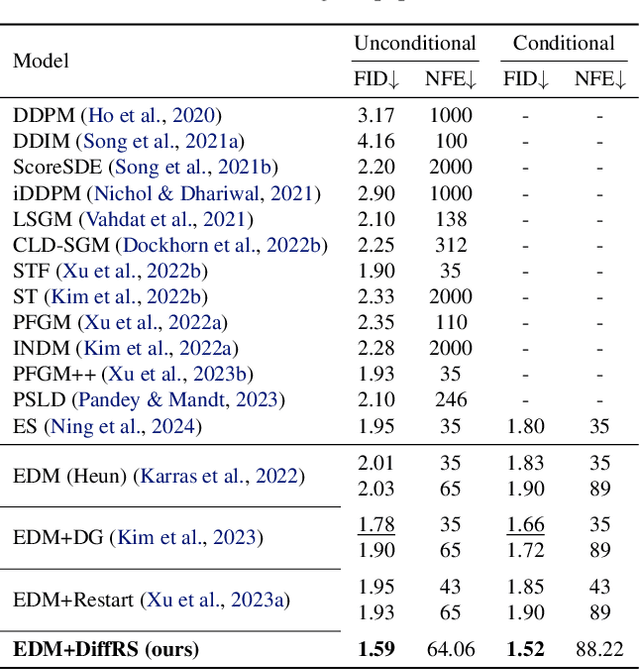
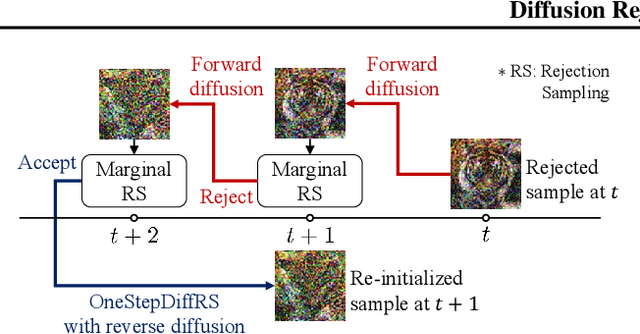
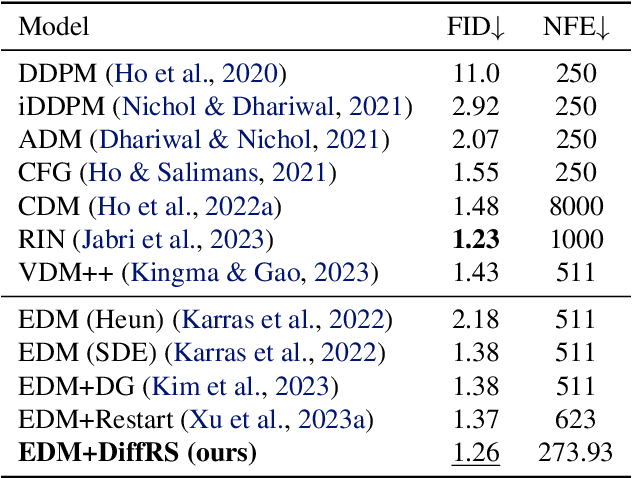
Recent advances in powerful pre-trained diffusion models encourage the development of methods to improve the sampling performance under well-trained diffusion models. This paper introduces Diffusion Rejection Sampling (DiffRS), which uses a rejection sampling scheme that aligns the sampling transition kernels with the true ones at each timestep. The proposed method can be viewed as a mechanism that evaluates the quality of samples at each intermediate timestep and refines them with varying effort depending on the sample. Theoretical analysis shows that DiffRS can achieve a tighter bound on sampling error compared to pre-trained models. Empirical results demonstrate the state-of-the-art performance of DiffRS on the benchmark datasets and the effectiveness of DiffRS for fast diffusion samplers and large-scale text-to-image diffusion models. Our code is available at https://github.com/aailabkaist/DiffRS.
Training Unbiased Diffusion Models From Biased Dataset
Mar 02, 2024With significant advancements in diffusion models, addressing the potential risks of dataset bias becomes increasingly important. Since generated outputs directly suffer from dataset bias, mitigating latent bias becomes a key factor in improving sample quality and proportion. This paper proposes time-dependent importance reweighting to mitigate the bias for the diffusion models. We demonstrate that the time-dependent density ratio becomes more precise than previous approaches, thereby minimizing error propagation in generative learning. While directly applying it to score-matching is intractable, we discover that using the time-dependent density ratio both for reweighting and score correction can lead to a tractable form of the objective function to regenerate the unbiased data density. Furthermore, we theoretically establish a connection with traditional score-matching, and we demonstrate its convergence to an unbiased distribution. The experimental evidence supports the usefulness of the proposed method, which outperforms baselines including time-independent importance reweighting on CIFAR-10, CIFAR-100, FFHQ, and CelebA with various bias settings. Our code is available at https://github.com/alsdudrla10/TIW-DSM.
Label-Noise Robust Diffusion Models
Feb 27, 2024Conditional diffusion models have shown remarkable performance in various generative tasks, but training them requires large-scale datasets that often contain noise in conditional inputs, a.k.a. noisy labels. This noise leads to condition mismatch and quality degradation of generated data. This paper proposes Transition-aware weighted Denoising Score Matching (TDSM) for training conditional diffusion models with noisy labels, which is the first study in the line of diffusion models. The TDSM objective contains a weighted sum of score networks, incorporating instance-wise and time-dependent label transition probabilities. We introduce a transition-aware weight estimator, which leverages a time-dependent noisy-label classifier distinctively customized to the diffusion process. Through experiments across various datasets and noisy label settings, TDSM improves the quality of generated samples aligned with given conditions. Furthermore, our method improves generation performance even on prevalent benchmark datasets, which implies the potential noisy labels and their risk of generative model learning. Finally, we show the improved performance of TDSM on top of conventional noisy label corrections, which empirically proving its contribution as a part of label-noise robust generative models. Our code is available at: https://github.com/byeonghu-na/tdsm.
Refining Generative Process with Discriminator Guidance in Score-based Diffusion Models
Nov 28, 2022
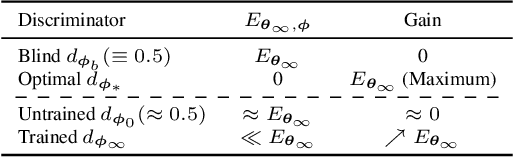


While the success of diffusion models has been witnessed in various domains, only a few works have investigated the variation of the generative process. In this paper, we introduce a new generative process that is closer to the reverse process than the original generative process, given the identical score checkpoint. Specifically, we adjust the generative process with the auxiliary discriminator between the real data and the generated data. Consequently, the adjusted generative process with the discriminator generates more realistic samples than the original process. In experiments, we achieve new SOTA FIDs of 1.74 on CIFAR-10, 1.33 on CelebA, and 1.88 on FFHQ in the unconditional generation.
Maximum Likelihood Training of Implicit Nonlinear Diffusion Models
May 27, 2022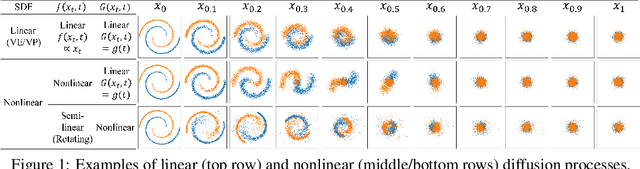

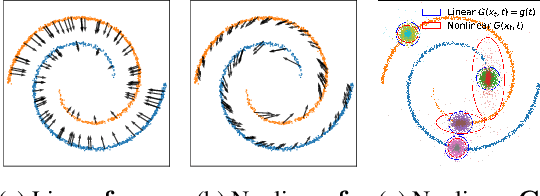

Whereas diverse variations of diffusion models exist, expanding the linear diffusion into a nonlinear diffusion process is investigated only by a few works. The nonlinearity effect has been hardly understood, but intuitively, there would be more promising diffusion patterns to optimally train the generative distribution towards the data distribution. This paper introduces such a data-adaptive and nonlinear diffusion process for score-based diffusion models. The proposed Implicit Nonlinear Diffusion Model (INDM) learns the nonlinear diffusion process by combining a normalizing flow and a diffusion process. Specifically, INDM implicitly constructs a nonlinear diffusion on the \textit{data space} by leveraging a linear diffusion on the \textit{latent space} through a flow network. This flow network is the key to forming a nonlinear diffusion as the nonlinearity fully depends on the flow network. This flexible nonlinearity is what improves the learning curve of INDM to nearly MLE training, compared against the non-MLE training of DDPM++, which turns out to be a special case of INDM with the identity flow. Also, training the nonlinear diffusion empirically yields a sampling-friendly latent diffusion that the sample trajectory of INDM is closer to an optimal transport than the trajectories of previous research. In experiments, INDM achieves the state-of-the-art FID on CelebA.
Score Matching Model for Unbounded Data Score
Jun 10, 2021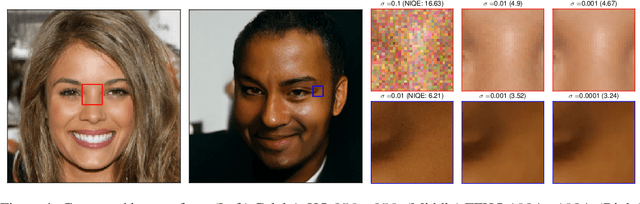
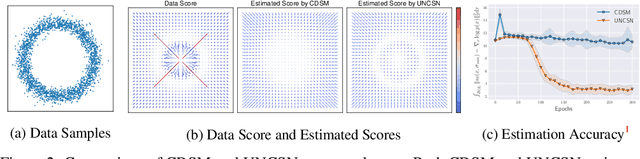
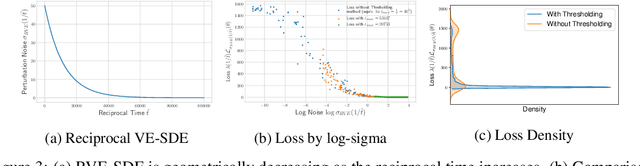
Recent advance in score-based models incorporates the stochastic differential equation (SDE), which brings the state-of-the art performance on image generation tasks. This paper improves such score-based models by analyzing the model at the zero perturbation noise. In real datasets, the score function diverges as the perturbation noise ($\sigma$) decreases to zero, and this observation leads an argument that the score estimation fails at $\sigma=0$ with any neural network structure. Subsequently, we introduce Unbounded Noise Conditional Score Network (UNCSN) that resolves the score diverging problem with an easily applicable modification to any noise conditional score-based models. Additionally, we introduce a new type of SDE, so the exact log likelihood can be calculated from the newly suggested SDE. On top of that, the associated loss function mitigates the loss imbalance issue in a mini-batch, and we present a theoretic analysis on the proposed loss to uncover the behind mechanism of the data distribution modeling by the score-based models.
Posterior-Aided Regularization for Likelihood-Free Inference
Feb 15, 2021

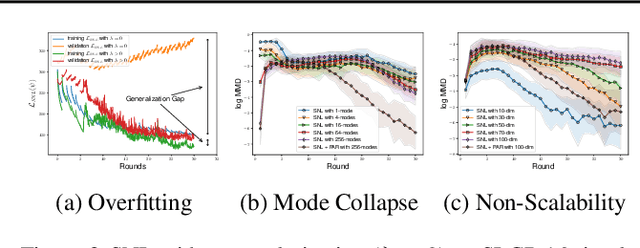

The recent development of likelihood-free inference aims training a flexible density estimator for the target posterior with a set of input-output pairs from simulation. Given the diversity of simulation structures, it is difficult to find a single unified inference method for each simulation model. This paper proposes a universally applicable regularization technique, called Posterior-Aided Regularization (PAR), which is applicable to learning the density estimator, regardless of the model structure. Particularly, PAR solves the mode collapse problem that arises as the output dimension of the simulation increases. PAR resolves this posterior mode degeneracy through a mixture of 1) the reverse KL divergence with the mode seeking property; and 2) the mutual information for the high quality representation on likelihood. Because of the estimation intractability of PAR, we provide a unified estimation method of PAR to estimate both reverse KL term and mutual information term with a single neural network. Afterwards, we theoretically prove the asymptotic convergence of the regularized optimal solution to the unregularized optimal solution as the regularization magnitude converges to zero. Additionally, we empirically show that past sequential neural likelihood inferences in conjunction with PAR present the statistically significant gains on diverse simulation tasks.
Counterfactual Fairness with Disentangled Causal Effect Variational Autoencoder
Dec 09, 2020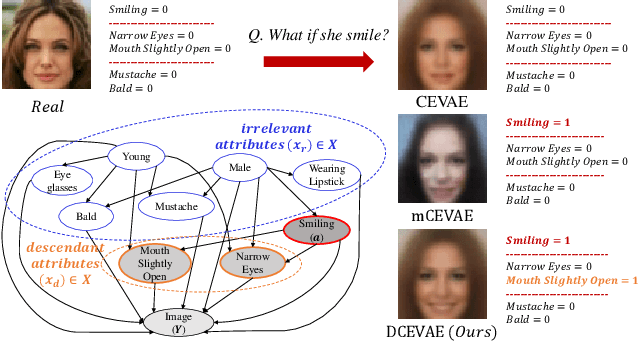
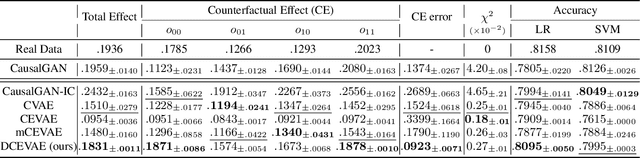
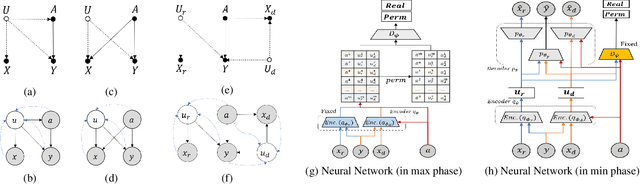
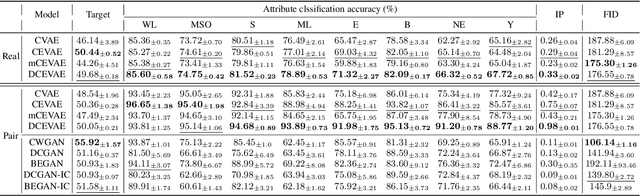
The problem of fair classification can be mollified if we develop a method to remove the embedded sensitive information from the classification features. This line of separating the sensitive information is developed through the causal inference, and the causal inference enables the counterfactual generations to contrast the what-if case of the opposite sensitive attribute. Along with this separation with the causality, a frequent assumption in the deep latent causal model defines a single latent variable to absorb the entire exogenous uncertainty of the causal graph. However, we claim that such structure cannot distinguish the 1) information caused by the intervention (i.e., sensitive variable) and 2) information correlated with the intervention from the data. Therefore, this paper proposes Disentangled Causal Effect Variational Autoencoder (DCEVAE) to resolve this limitation by disentangling the exogenous uncertainty into two latent variables: either 1) independent to interventions or 2) correlated to interventions without causality. Particularly, our disentangling approach preserves the latent variable correlated to interventions in generating counterfactual examples. We show that our method estimates the total effect and the counterfactual effect without a complete causal graph. By adding a fairness regularization, DCEVAE generates a counterfactual fair dataset while losing less original information. Also, DCEVAE generates natural counterfactual images by only flipping sensitive information. Additionally, we theoretically show the differences in the covariance structures of DCEVAE and prior works from the perspective of the latent disentanglement.
Mixout: Effective Regularization to Finetune Large-scale Pretrained Language Models
Sep 25, 2019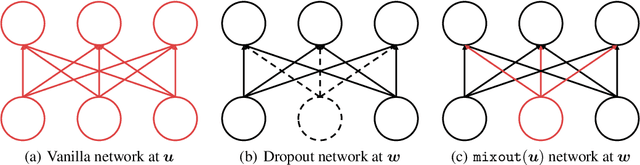
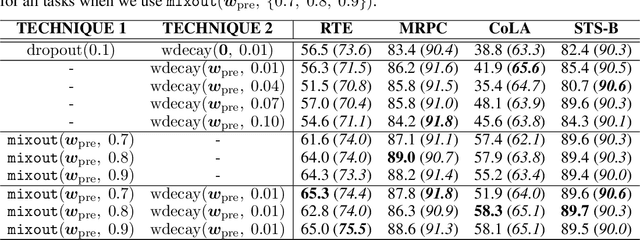
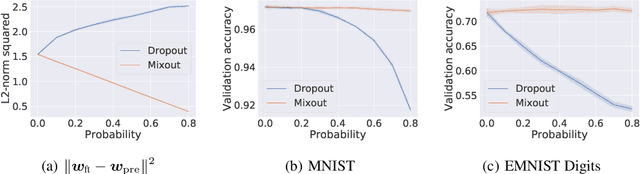
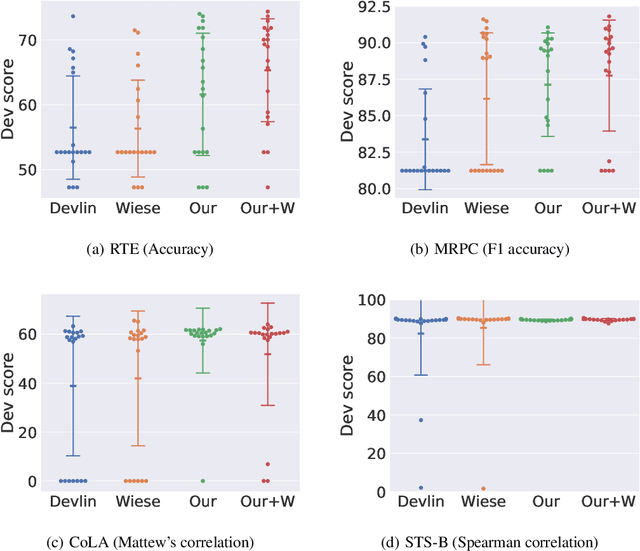
In natural language processing, it has been observed recently that generalization could be greatly improved by finetuning a large-scale language model pretrained on a large unlabeled corpus. Despite its recent success and wide adoption, finetuning a large pretrained language model on a downstream task is prone to degenerate performance when there are only a small number of training instances available. In this paper, we introduce a new regularization technique, to which we refer as "mixout", motivated by dropout. Mixout stochastically mixes the parameters of two models. We show that our mixout technique regularizes learning to minimize the deviation from one of the two models and that the strength of regularization adapts along the optimization trajectory. We empirically evaluate the proposed mixout and its variants on finetuning a pretrained language model on downstream tasks. More specifically, we demonstrate that the stability of finetuning and the average accuracy greatly increase when we use the proposed approach to regularize finetuning of BERT on downstream tasks in GLUE.