 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake Prompts Adaptable: Bayesian Modeling for Vision-Language Prompt Learning with Data-Dependent Prior
Jan 09, 2024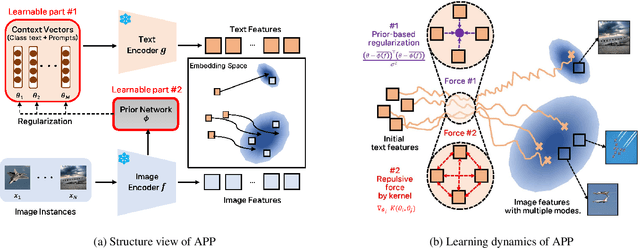

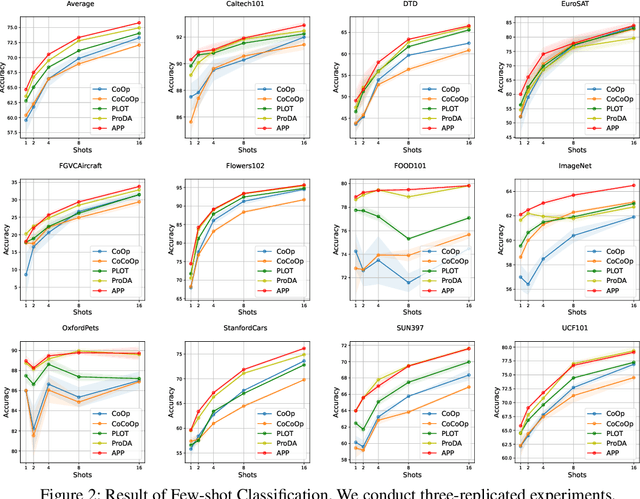

Recent Vision-Language Pretrained (VLP) models have become the backbone for many downstream tasks, but they are utilized as frozen model without learning. Prompt learning is a method to improve the pre-trained VLP model by adding a learnable context vector to the inputs of the text encoder. In a few-shot learning scenario of the downstream task, MLE training can lead the context vector to over-fit dominant image features in the training data. This overfitting can potentially harm the generalization ability, especially in the presence of a distribution shift between the training and test dataset. This paper presents a Bayesian-based framework of prompt learning, which could alleviate the overfitting issues on few-shot learning application and increase the adaptability of prompts on unseen instances. Specifically, modeling data-dependent prior enhances the adaptability of text features for both seen and unseen image features without the trade-off of performance between them. Based on the Bayesian framework, we utilize the Wasserstein Gradient Flow in the estimation of our target posterior distribution, which enables our prompt to be flexible in capturing the complex modes of image features. We demonstrate the effectiveness of our method on benchmark datasets for several experiments by showing statistically significant improvements on performance compared to existing methods. The code is available at https://github.com/youngjae-cho/APP.
Loss-Curvature Matching for Dataset Selection and Condensation
Mar 08, 2023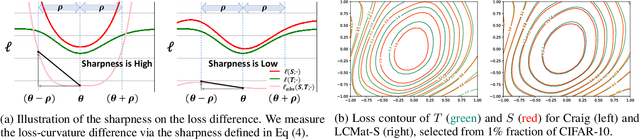
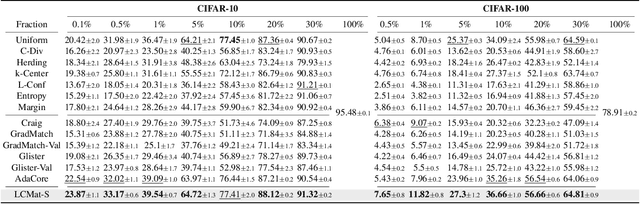
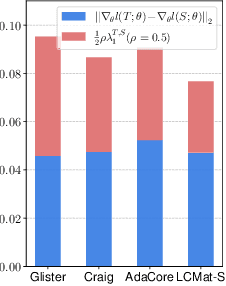
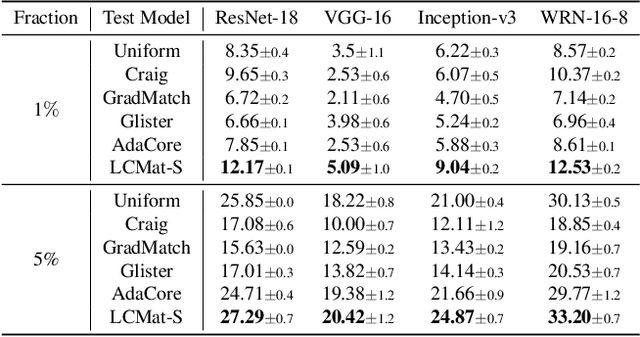
Training neural networks on a large dataset requires substantial computational costs. Dataset reduction selects or synthesizes data instances based on the large dataset, while minimizing the degradation in generalization performance from the full dataset. Existing methods utilize the neural network during the dataset reduction procedure, so the model parameter becomes important factor in preserving the performance after reduction. By depending upon the importance of parameters, this paper introduces a new reduction objective, coined LCMat, which Matches the Loss Curvatures of the original dataset and reduced dataset over the model parameter space, more than the parameter point. This new objective induces a better adaptation of the reduced dataset on the perturbed parameter region than the exact point matching. Particularly, we identify the worst case of the loss curvature gap from the local parameter region, and we derive the implementable upper bound of such worst-case with theoretical analyses. Our experiments on both coreset selection and condensation benchmarks illustrate that LCMat shows better generalization performances than existing baselines.
Counterfactual Fairness with Disentangled Causal Effect Variational Autoencoder
Dec 09, 2020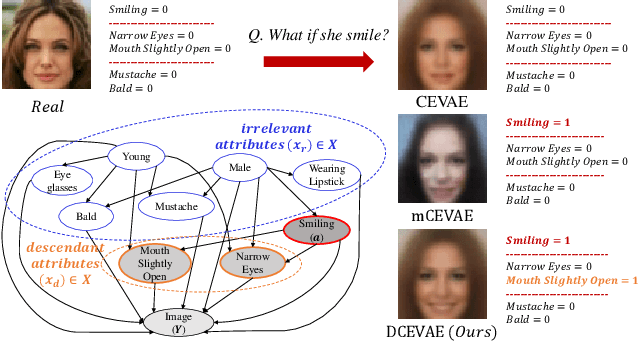
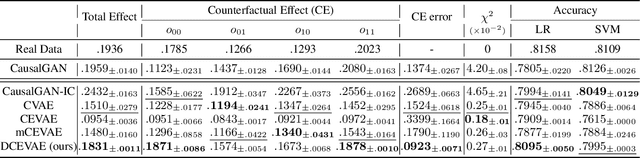
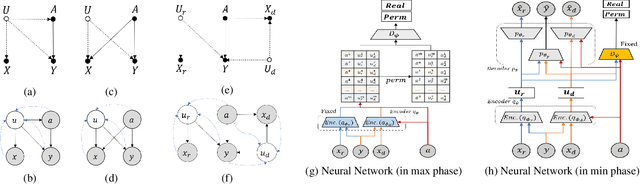
The problem of fair classification can be mollified if we develop a method to remove the embedded sensitive information from the classification features. This line of separating the sensitive information is developed through the causal inference, and the causal inference enables the counterfactual generations to contrast the what-if case of the opposite sensitive attribute. Along with this separation with the causality, a frequent assumption in the deep latent causal model defines a single latent variable to absorb the entire exogenous uncertainty of the causal graph. However, we claim that such structure cannot distinguish the 1) information caused by the intervention (i.e., sensitive variable) and 2) information correlated with the intervention from the data. Therefore, this paper proposes Disentangled Causal Effect Variational Autoencoder (DCEVAE) to resolve this limitation by disentangling the exogenous uncertainty into two latent variables: either 1) independent to interventions or 2) correlated to interventions without causality. Particularly, our disentangling approach preserves the latent variable correlated to interventions in generating counterfactual examples. We show that our method estimates the total effect and the counterfactual effect without a complete causal graph. By adding a fairness regularization, DCEVAE generates a counterfactual fair dataset while losing less original information. Also, DCEVAE generates natural counterfactual images by only flipping sensitive information. Additionally, we theoretically show the differences in the covariance structures of DCEVAE and prior works from the perspective of the latent disentanglement.
Adversarial Likelihood-Free Inference on Black-Box Generator
Apr 13, 2020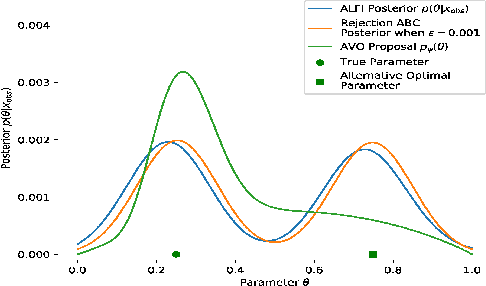
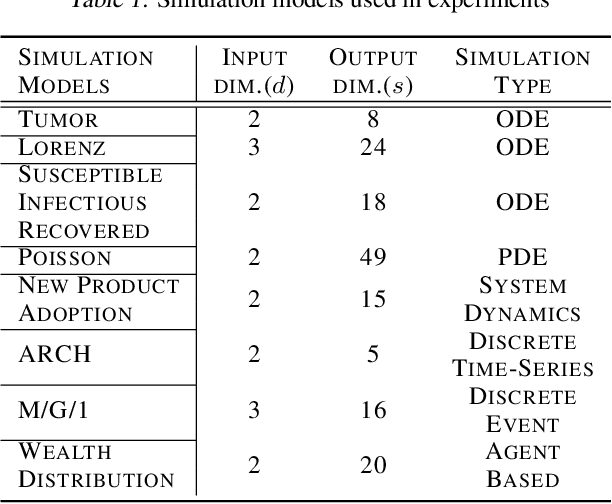
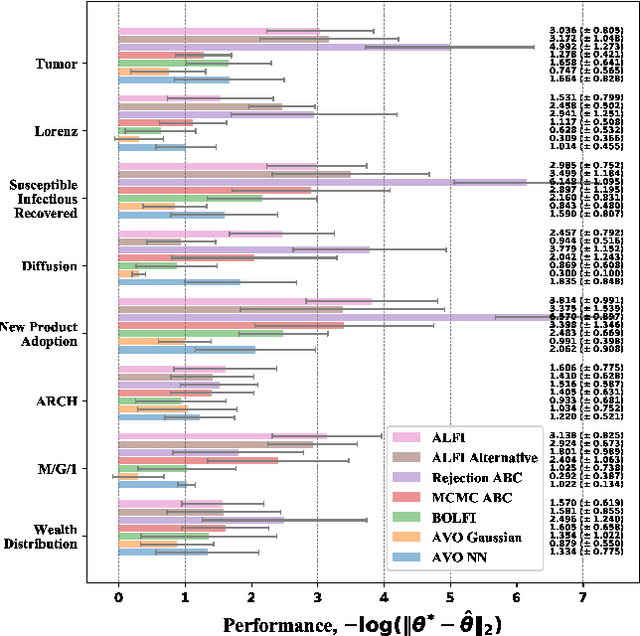
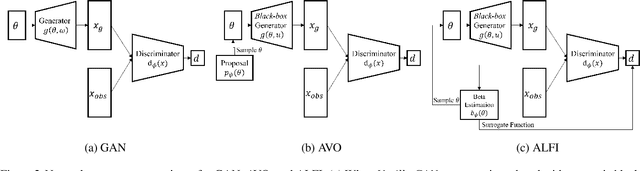
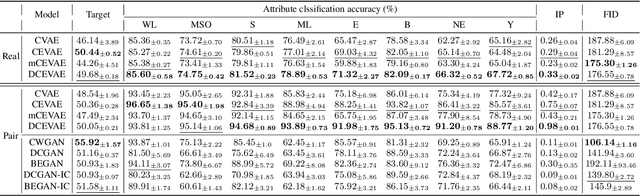
Generative Adversarial Network (GAN) can be viewed as an implicit estimator of a data distribution, and this perspective motivates using GAN in the true parameter estimation under a complex black-box generative model. While previous works investigated how to backpropagate gradients through the black-box model, this paper suggests an augmented neural structure to perform a likelihood-free inference on the blackbox model. Specifically, we suggest a new adversarial framework, Adversarial Likelihood-Free Inference (ALFI), with the beta-estimation network, that assumes a probabilistic model on the discriminator whose outputs are sampled from a stochastic process. Through the adversarial learning and the beta-estimation network learning, ALFI is able to find the posterior distribution of the parameter for the black-box generator model. We experimented ALFI with diverse simulation models as well as deconvolutional model, and we identified ALFI achieves the best parameter estimation accuracy with a limited simulation budget.
Neutralizing Gender Bias in Word Embedding with Latent Disentanglement and Counterfactual Generation
Apr 07, 2020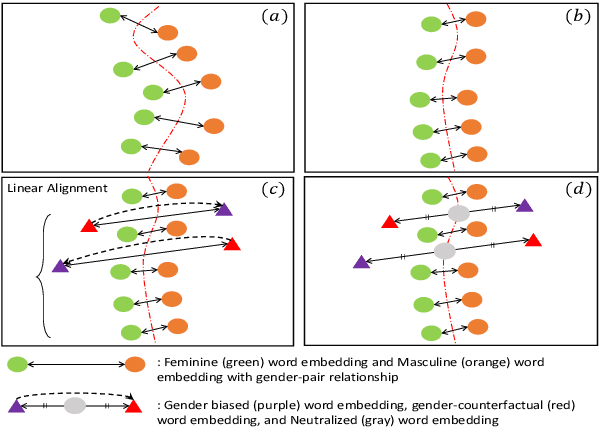
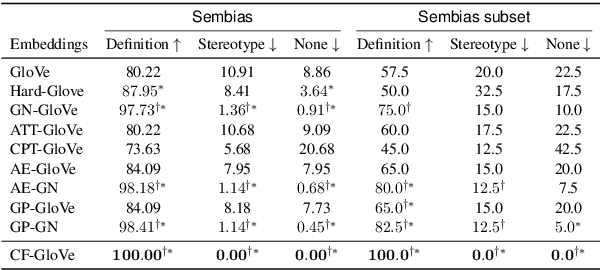
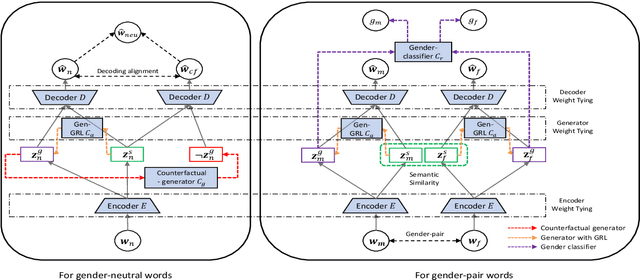
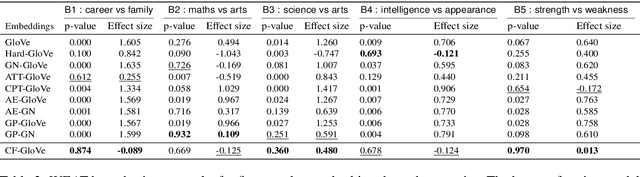
Recent researches demonstrate that word embeddings, trained on the human-generated corpus, have strong gender biases in embedding spaces, and these biases can result in the prejudiced results from the downstream tasks, i.e. sentiment analysis. Whereas the previous debiasing models project word embeddings into a linear subspace, we introduce a Latent Disentangling model with a siamese auto-encoder structure and a gradient reversal layer. Our siamese auto-encoder utilizes gender word pairs to disentangle semantics and gender information of given word, and the associated gradient reversal layer provides the negative gradient to distinguish the semantics from the gender. Afterwards, we introduce a Counterfactual Generation model to modify the gender information of words, so the original and the modified embeddings can produce a gender-neutralized word embedding after geometric alignment without loss of semantic information. Experimental results quantitatively and qualitatively indicate that the introduced method is better in debiasing word embeddings, and in minimizing the semantic information losses for NLP downstream tasks.
Generalized Gumbel-Softmax Gradient Estimator for Various Discrete Random Variables
Mar 04, 2020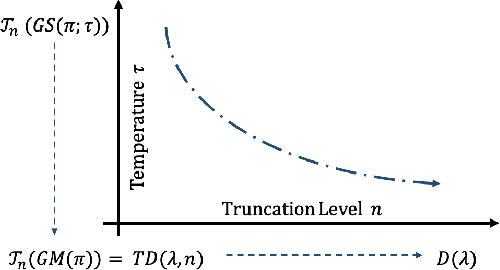
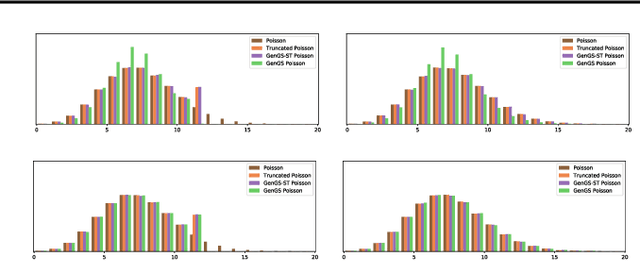
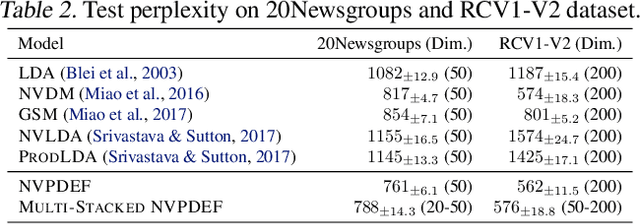
Estimating the gradients of stochastic nodes is one of the crucial research questions in the deep generative modeling community. This estimation problem becomes further complex when we regard the stochastic nodes to be discrete because pathwise derivative techniques can not be applied. Hence, the gradient estimation requires the score function methods or the continuous relaxation of the discrete random variables. This paper proposes a general version of the Gumbel-Softmax estimator with continuous relaxation, and this estimator is able to relax the discreteness of probability distributions, including broader types than the current practice. In detail, we utilize the truncation of discrete random variables and the Gumbel-Softmax trick with a linear transformation for the relaxation. The proposed approach enables the relaxed discrete random variable to be reparameterized and to backpropagate through a large scale stochastic neural network. Our experiments consist of synthetic data analyses, which show the efficacy of our methods, and topic model analyses, which demonstrates the value of the proposed estimation in practices.
Sequential Recommendation with Relation-Aware Kernelized Self-Attention
Nov 15, 2019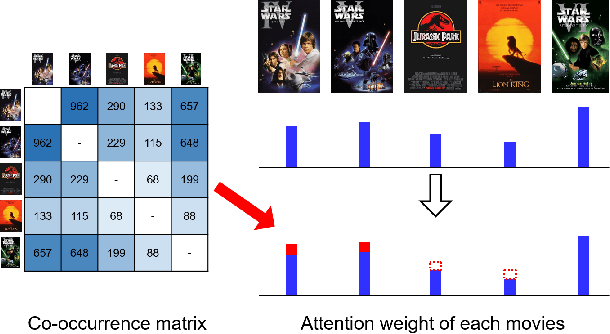

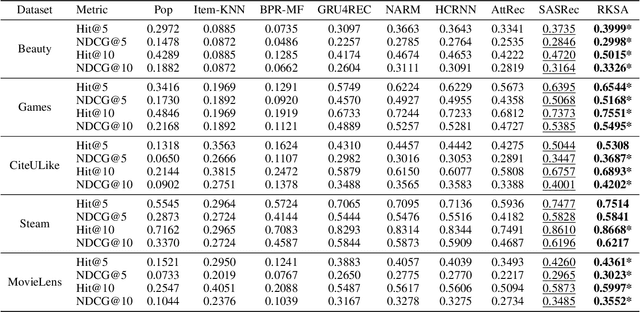
Recent studies identified that sequential Recommendation is improved by the attention mechanism. By following this development, we propose Relation-Aware Kernelized Self-Attention (RKSA) adopting a self-attention mechanism of the Transformer with augmentation of a probabilistic model. The original self-attention of Transformer is a deterministic measure without relation-awareness. Therefore, we introduce a latent space to the self-attention, and the latent space models the recommendation context from relation as a multivariate skew-normal distribution with a kernelized covariance matrix from co-occurrences, item characteristics, and user information. This work merges the self-attention of the Transformer and the sequential recommendation by adding a probabilistic model of the recommendation task specifics. We experimented RKSA over the benchmark datasets, and RKSA shows significant improvements compared to the recent baseline models. Also, RKSA were able to produce a latent space model that answers the reasons for recommendation.
* 8 pages, 5 figures, AAAI
Dirichlet Variational Autoencoder
Jan 09, 2019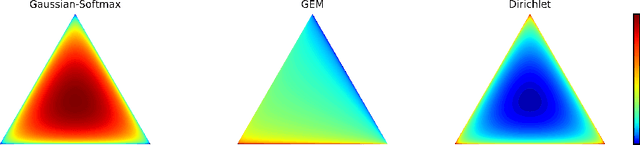
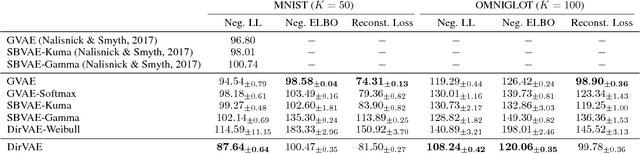
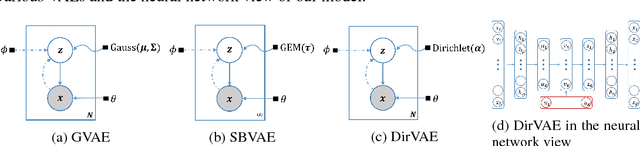

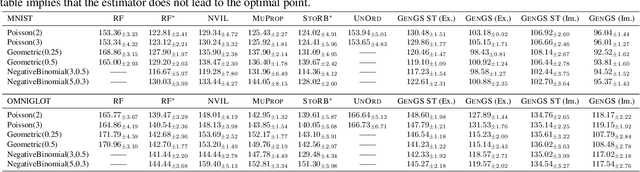
This paper proposes Dirichlet Variational Autoencoder (DirVAE) using a Dirichlet prior for a continuous latent variable that exhibits the characteristic of the categorical probabilities. To infer the parameters of DirVAE, we utilize the stochastic gradient method by approximating the Gamma distribution, which is a component of the Dirichlet distribution, with the inverse Gamma CDF approximation. Additionally, we reshape the component collapsing issue by investigating two problem sources, which are decoder weight collapsing and latent value collapsing, and we show that DirVAE has no component collapsing; while Gaussian VAE exhibits the decoder weight collapsing and Stick-Breaking VAE shows the latent value collapsing. The experimental results show that 1) DirVAE models the latent representation result with the best log-likelihood compared to the baselines; and 2) DirVAE produces more interpretable latent values with no collapsing issues which the baseline models suffer from. Also, we show that the learned latent representation from the DirVAE achieves the best classification accuracy in the semi-supervised and the supervised classification tasks on MNIST, OMNIGLOT, and SVHN compared to the baseline VAEs. Finally, we demonstrated that the DirVAE augmented topic models show better performances in most cases.