 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Optimization by Estimating the Ratio of the Data Distribution
May 26, 2025Direct preference optimization (DPO) is widely used as a simple and stable method for aligning large language models (LLMs) with human preferences. This paper investigates a generalized DPO loss that enables a policy model to match the target policy from a likelihood ratio estimation perspective. The ratio of the target policy provides a unique identification of the policy distribution without relying on reward models or partition functions. This allows the generalized loss to retain both simplicity and theoretical guarantees, which prior work such as $f$-PO fails to achieve simultaneously. We propose Bregman preference optimization (BPO), a generalized framework for ratio matching that provides a family of objective functions achieving target policy optimality. BPO subsumes DPO as a special case and offers tractable forms for all instances, allowing implementation with a few lines of code. We further develop scaled Basu's power divergence (SBA), a gradient scaling method that can be used for BPO instances. The BPO framework complements other DPO variants and is applicable to target policies defined by these variants. In experiments, unlike other probabilistic loss extensions such as $f$-DPO or $f$-PO, which exhibit a trade-off between generation fidelity and diversity, instances of BPO improve both win rate and entropy compared with DPO. When applied to Llama-3-Instruct-8B, BPO achieves state-of-the-art performance among Llama-3-8B backbones, with a 55.9\% length-controlled win rate on AlpacaEval2.
Loss-Curvature Matching for Dataset Selection and Condensation
Mar 08, 2023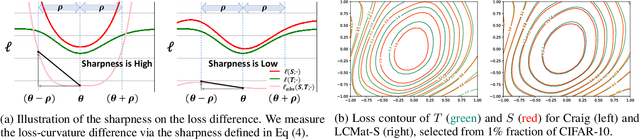
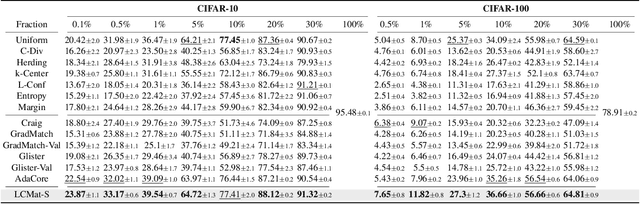
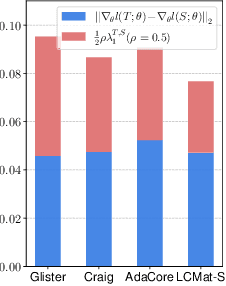
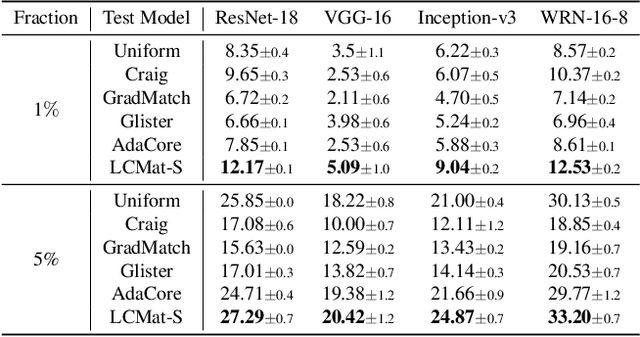
Training neural networks on a large dataset requires substantial computational costs. Dataset reduction selects or synthesizes data instances based on the large dataset, while minimizing the degradation in generalization performance from the full dataset. Existing methods utilize the neural network during the dataset reduction procedure, so the model parameter becomes important factor in preserving the performance after reduction. By depending upon the importance of parameters, this paper introduces a new reduction objective, coined LCMat, which Matches the Loss Curvatures of the original dataset and reduced dataset over the model parameter space, more than the parameter point. This new objective induces a better adaptation of the reduced dataset on the perturbed parameter region than the exact point matching. Particularly, we identify the worst case of the loss curvature gap from the local parameter region, and we derive the implementable upper bound of such worst-case with theoretical analyses. Our experiments on both coreset selection and condensation benchmarks illustrate that LCMat shows better generalization performances than existing baselines.