 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Where It Matters: Geometric Anchoring for Robust Preference Alignment
Feb 04, 2026Direct Preference Optimization (DPO) and related methods align large language models from pairwise preferences by regularizing updates against a fixed reference policy. As the policy drifts, a static reference, however, can become increasingly miscalibrated, leading to distributional mismatch and amplifying spurious preference signals under noisy supervision. Conversely, reference-free variants avoid mismatch but often suffer from unconstrained reward drift. We propose Geometric Anchor Preference Optimization (GAPO), which replaces the fixed reference with a dynamic, geometry-aware anchor: an adversarial local perturbation of the current policy within a small radius that serves as a pessimistic baseline. This anchor enables an adaptive reweighting mechanism, modulating the importance of each preference pair based on its local sensitivity. We further introduce the Anchor Gap, the reward discrepancy between the policy and its anchor, and show under smoothness conditions that it approximates worst-case local margin degradation. Optimizing a logistic objective weighted by this gap downweights geometrically brittle instances while emphasizing robust preference signals. Across diverse noise settings, GAPO consistently improves robustness while matching or improving performance on standard LLM alignment and reasoning benchmarks.
Revisiting DDIM Inversion for Controlling Defect Generation by Disentangling the Background
Nov 25, 2024In anomaly detection, the scarcity of anomalous data compared to normal data poses a challenge in effectively utilizing deep neural network representations to identify anomalous features. From a data-centric perspective, generative models can solve this data imbalance issue by synthesizing anomaly datasets. Although previous research tried to enhance the controllability and quality of generating defects, they do not consider the relation between background and defect. Since the defect depends on the object's background (i.e., the normal part of an object), training only the defect area cannot utilize the background information, and even generation can be biased depending on the mask information. In addition, controlling logical anomalies should consider the dependency between background and defect areas (e.g., orange colored defect on a orange juice bottle). In this paper, our paper proposes modeling a relationship between the background and defect, where background affects denoising defects; however, the reverse is not. We introduce the regularizing term to disentangle denoising background from defects. From the disentanglement loss, we rethink defect generation with DDIM Inversion, where we generate the defect on the target normal image. Additionally, we theoretically prove that our methodology can generate a defect on the target normal image with an invariant background. We demonstrate our synthetic data is realistic and effective in several experiments.
Make Prompts Adaptable: Bayesian Modeling for Vision-Language Prompt Learning with Data-Dependent Prior
Jan 09, 2024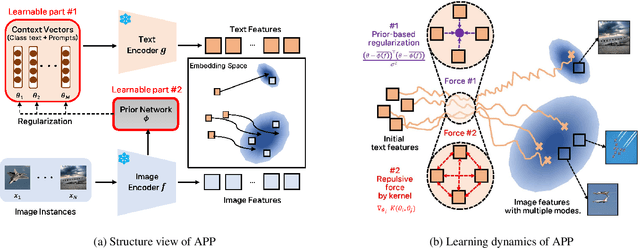

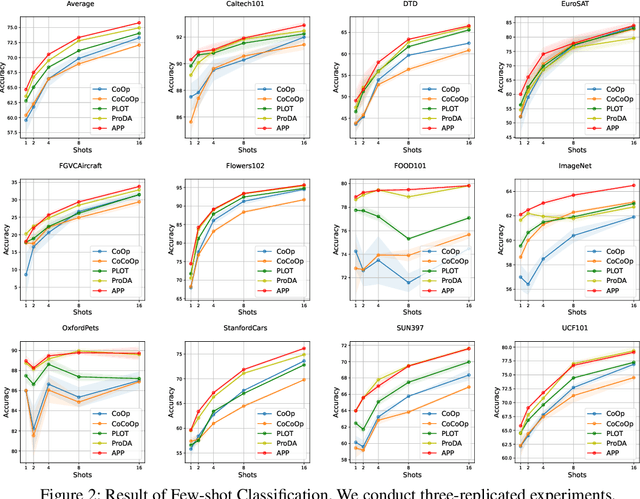

Recent Vision-Language Pretrained (VLP) models have become the backbone for many downstream tasks, but they are utilized as frozen model without learning. Prompt learning is a method to improve the pre-trained VLP model by adding a learnable context vector to the inputs of the text encoder. In a few-shot learning scenario of the downstream task, MLE training can lead the context vector to over-fit dominant image features in the training data. This overfitting can potentially harm the generalization ability, especially in the presence of a distribution shift between the training and test dataset. This paper presents a Bayesian-based framework of prompt learning, which could alleviate the overfitting issues on few-shot learning application and increase the adaptability of prompts on unseen instances. Specifically, modeling data-dependent prior enhances the adaptability of text features for both seen and unseen image features without the trade-off of performance between them. Based on the Bayesian framework, we utilize the Wasserstein Gradient Flow in the estimation of our target posterior distribution, which enables our prompt to be flexible in capturing the complex modes of image features. We demonstrate the effectiveness of our method on benchmark datasets for several experiments by showing statistically significant improvements on performance compared to existing methods. The code is available at https://github.com/youngjae-cho/APP.