 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-aware Wasserstein Policy Regularization for Large Language Model Alignment
Feb 02, 2026Large language models (LLMs) are commonly aligned with human preferences using reinforcement learning from human feedback (RLHF). In this method, LLM policies are generally optimized through reward maximization with Kullback-Leibler (KL) divergence regularization of the reference policy. However, KL and its $f$-divergence variants only compare token probabilities at identical indices, failing to capture semantic similarity. We propose Wasserstein Policy Regularization (WPR), a semantic-aware regularization for the RLHF framework based on the entropy-regularized Wasserstein distance, which incorporates the geometry of the token space. The dual formulation of the distance expresses the regularization as penalty terms applied to the reward via optimal dual variables, which yield a tractable objective compatible with standard RL algorithms. Empirically, our method outperforms KL- and $f$-divergence-based baselines, demonstrating the benefits of semantic-aware policy distances for alignment. Our code is available at https://github.com/aailab-kaist/WPR.
Distilling Dataset into Neural Field
Mar 05, 2025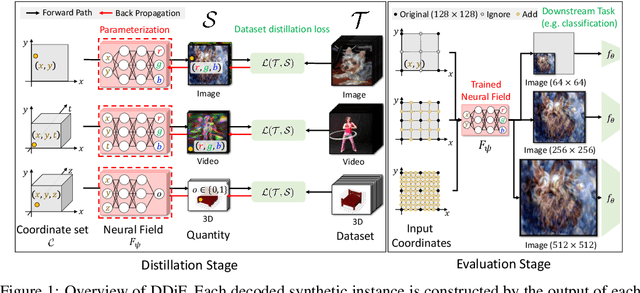
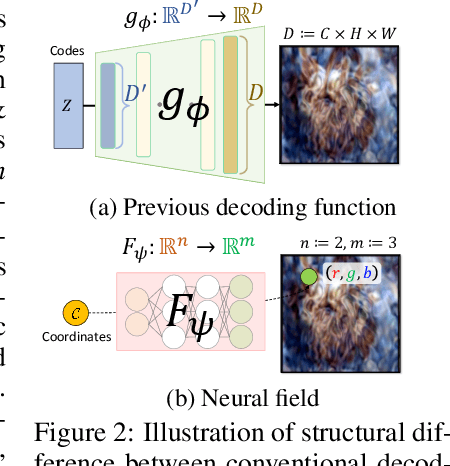

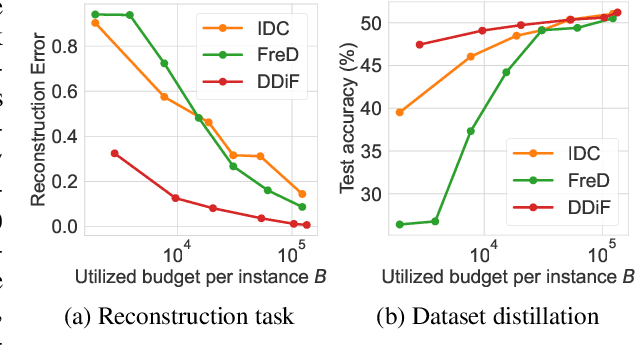
Utilizing a large-scale dataset is essential for training high-performance deep learning models, but it also comes with substantial computation and storage costs. To overcome these challenges, dataset distillation has emerged as a promising solution by compressing the large-scale dataset into a smaller synthetic dataset that retains the essential information needed for training. This paper proposes a novel parameterization framework for dataset distillation, coined Distilling Dataset into Neural Field (DDiF), which leverages the neural field to store the necessary information of the large-scale dataset. Due to the unique nature of the neural field, which takes coordinates as input and output quantity, DDiF effectively preserves the information and easily generates various shapes of data. We theoretically confirm that DDiF exhibits greater expressiveness than some previous literature when the utilized budget for a single synthetic instance is the same. Through extensive experiments, we demonstrate that DDiF achieves superior performance on several benchmark datasets, extending beyond the image domain to include video, audio, and 3D voxel. We release the code at https://github.com/aailab-kaist/DDiF.
Unknown Domain Inconsistency Minimization for Domain Generalization
Mar 12, 2024The objective of domain generalization (DG) is to enhance the transferability of the model learned from a source domain to unobserved domains. To prevent overfitting to a specific domain, Sharpness-Aware Minimization (SAM) reduces source domain's loss sharpness. Although SAM variants have delivered significant improvements in DG, we highlight that there's still potential for improvement in generalizing to unknown domains through the exploration on data space. This paper introduces an objective rooted in both parameter and data perturbed regions for domain generalization, coined Unknown Domain Inconsistency Minimization (UDIM). UDIM reduces the loss landscape inconsistency between source domain and unknown domains. As unknown domains are inaccessible, these domains are empirically crafted by perturbing instances from the source domain dataset. In particular, by aligning the loss landscape acquired in the source domain to the loss landscape of perturbed domains, we expect to achieve generalization grounded on these flat minima for the unknown domains. Theoretically, we validate that merging SAM optimization with the UDIM objective establishes an upper bound for the true objective of the DG task. In an empirical aspect, UDIM consistently outperforms SAM variants across multiple DG benchmark datasets. Notably, UDIM shows statistically significant improvements in scenarios with more restrictive domain information, underscoring UDIM's generalization capability in unseen domains. Our code is available at \url{https://github.com/SJShin-AI/UDIM}.
Dirichlet-based Per-Sample Weighting by Transition Matrix for Noisy Label Learning
Mar 05, 2024For learning with noisy labels, the transition matrix, which explicitly models the relation between noisy label distribution and clean label distribution, has been utilized to achieve the statistical consistency of either the classifier or the risk. Previous researches have focused more on how to estimate this transition matrix well, rather than how to utilize it. We propose good utilization of the transition matrix is crucial and suggest a new utilization method based on resampling, coined RENT. Specifically, we first demonstrate current utilizations can have potential limitations for implementation. As an extension to Reweighting, we suggest the Dirichlet distribution-based per-sample Weight Sampling (DWS) framework, and compare reweighting and resampling under DWS framework. With the analyses from DWS, we propose RENT, a REsampling method with Noise Transition matrix. Empirically, RENT consistently outperforms existing transition matrix utilization methods, which includes reweighting, on various benchmark datasets. Our code is available at \url{https://github.com/BaeHeeSun/RENT}.
Label-Noise Robust Diffusion Models
Feb 27, 2024Conditional diffusion models have shown remarkable performance in various generative tasks, but training them requires large-scale datasets that often contain noise in conditional inputs, a.k.a. noisy labels. This noise leads to condition mismatch and quality degradation of generated data. This paper proposes Transition-aware weighted Denoising Score Matching (TDSM) for training conditional diffusion models with noisy labels, which is the first study in the line of diffusion models. The TDSM objective contains a weighted sum of score networks, incorporating instance-wise and time-dependent label transition probabilities. We introduce a transition-aware weight estimator, which leverages a time-dependent noisy-label classifier distinctively customized to the diffusion process. Through experiments across various datasets and noisy label settings, TDSM improves the quality of generated samples aligned with given conditions. Furthermore, our method improves generation performance even on prevalent benchmark datasets, which implies the potential noisy labels and their risk of generative model learning. Finally, we show the improved performance of TDSM on top of conventional noisy label corrections, which empirically proving its contribution as a part of label-noise robust generative models. Our code is available at: https://github.com/byeonghu-na/tdsm.
Make Prompts Adaptable: Bayesian Modeling for Vision-Language Prompt Learning with Data-Dependent Prior
Jan 09, 2024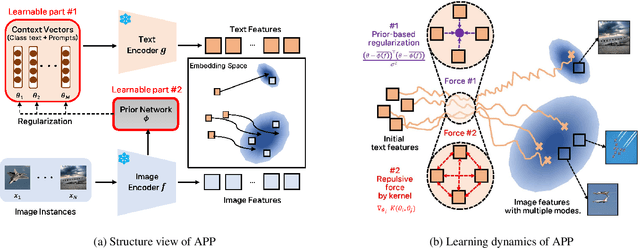

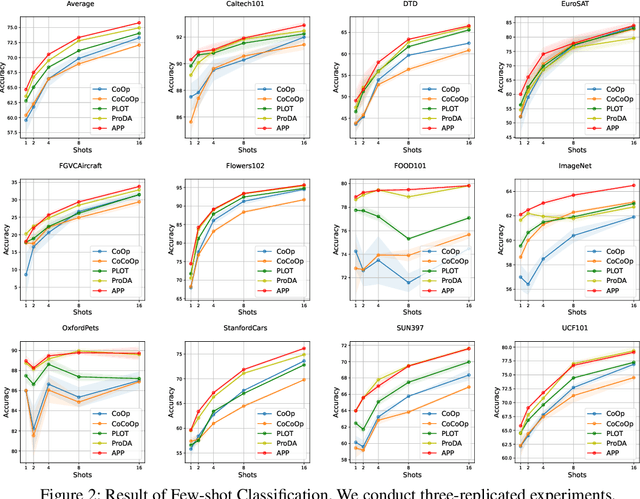

Recent Vision-Language Pretrained (VLP) models have become the backbone for many downstream tasks, but they are utilized as frozen model without learning. Prompt learning is a method to improve the pre-trained VLP model by adding a learnable context vector to the inputs of the text encoder. In a few-shot learning scenario of the downstream task, MLE training can lead the context vector to over-fit dominant image features in the training data. This overfitting can potentially harm the generalization ability, especially in the presence of a distribution shift between the training and test dataset. This paper presents a Bayesian-based framework of prompt learning, which could alleviate the overfitting issues on few-shot learning application and increase the adaptability of prompts on unseen instances. Specifically, modeling data-dependent prior enhances the adaptability of text features for both seen and unseen image features without the trade-off of performance between them. Based on the Bayesian framework, we utilize the Wasserstein Gradient Flow in the estimation of our target posterior distribution, which enables our prompt to be flexible in capturing the complex modes of image features. We demonstrate the effectiveness of our method on benchmark datasets for several experiments by showing statistically significant improvements on performance compared to existing methods. The code is available at https://github.com/youngjae-cho/APP.
From Noisy Prediction to True Label: Noisy Prediction Calibration via Generative Model
May 02, 2022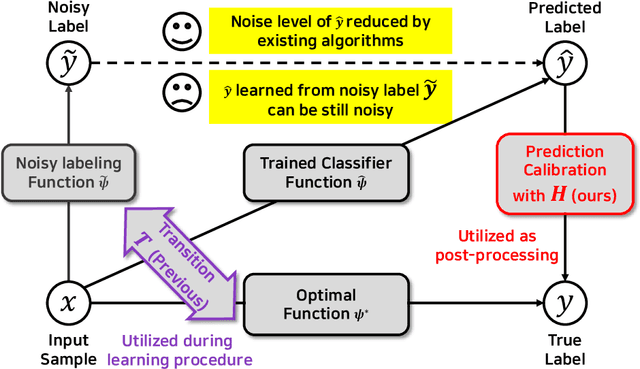
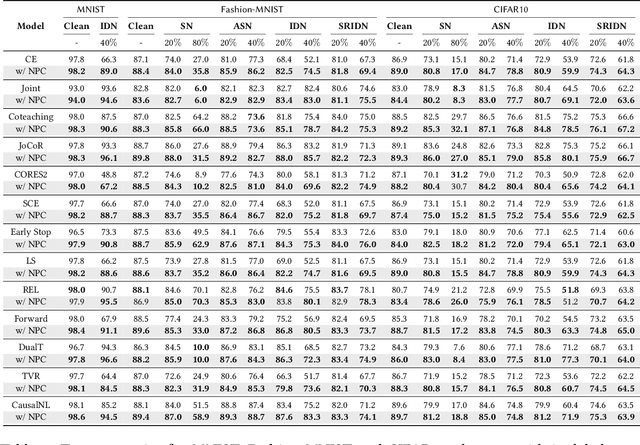
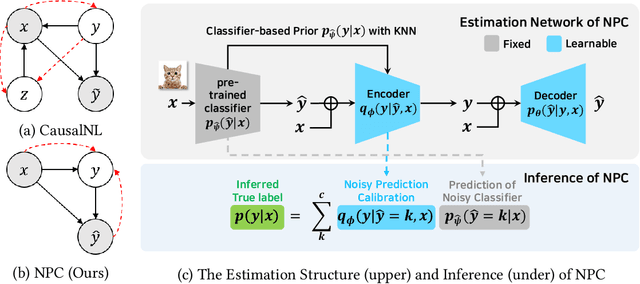
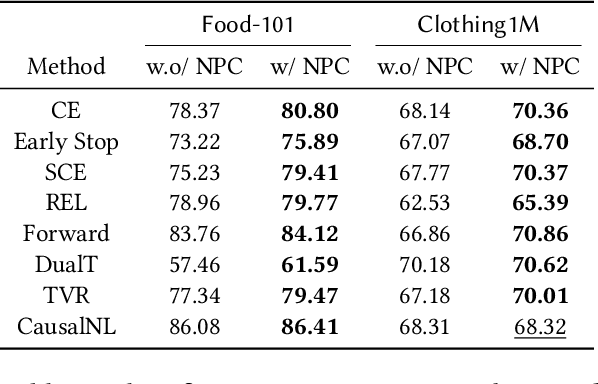
Noisy labels are inevitable yet problematic in machine learning society. It ruins the generalization power of a classifier by making the classifier be trained to be overfitted to wrong labels. Existing methods on noisy label have focused on modifying classifier training procedure. It results in two possible problems. First, these methods are not applicable to a pre-trained classifier without further access into training. Second, it is not easy to train a classifier and remove all of negative effects from noisy labels simultaneously. From these problems, we suggests a new branch of approach, Noisy Prediction Calibration (NPC) in learning with noisy labels. Through the introduction and estimation of a new type of transition matrix via generative model, NPC corrects the noisy prediction from the pre-trained classifier to the true label as a post-processing scheme. We prove that NPC theoretically aligns with the transition matrix based methods. Yet, NPC provides more accurate pathway to estimate true label, even without involvement in classifier learning. Also, NPC is applicable to any classifier trained with noisy label methods, if training instances and its predictions are available. Our method, NPC, boosts the classification performances of all baseline models on both synthetic and real-world datasets.