 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeutralizing Gender Bias in Word Embedding with Latent Disentanglement and Counterfactual Generation
Paper and Code
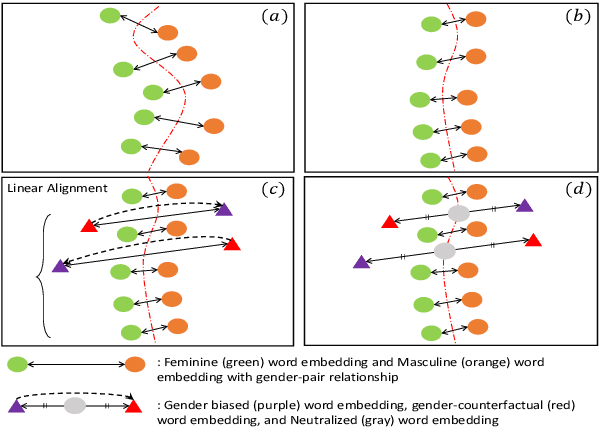
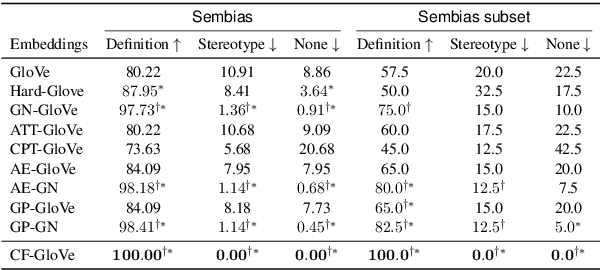
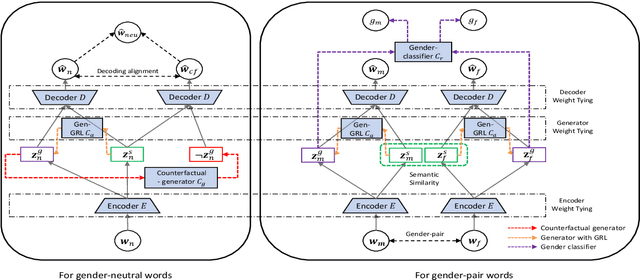
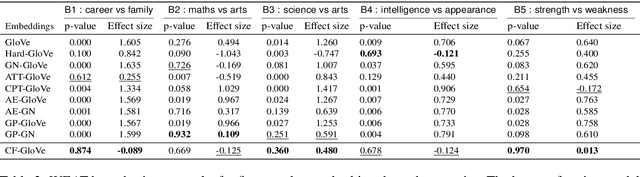
Recent researches demonstrate that word embeddings, trained on the human-generated corpus, have strong gender biases in embedding spaces, and these biases can result in the prejudiced results from the downstream tasks, i.e. sentiment analysis. Whereas the previous debiasing models project word embeddings into a linear subspace, we introduce a Latent Disentangling model with a siamese auto-encoder structure and a gradient reversal layer. Our siamese auto-encoder utilizes gender word pairs to disentangle semantics and gender information of given word, and the associated gradient reversal layer provides the negative gradient to distinguish the semantics from the gender. Afterwards, we introduce a Counterfactual Generation model to modify the gender information of words, so the original and the modified embeddings can produce a gender-neutralized word embedding after geometric alignment without loss of semantic information. Experimental results quantitatively and qualitatively indicate that the introduced method is better in debiasing word embeddings, and in minimizing the semantic information losses for NLP downstream tasks.