 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-aware Wasserstein Policy Regularization for Large Language Model Alignment
Feb 02, 2026Large language models (LLMs) are commonly aligned with human preferences using reinforcement learning from human feedback (RLHF). In this method, LLM policies are generally optimized through reward maximization with Kullback-Leibler (KL) divergence regularization of the reference policy. However, KL and its $f$-divergence variants only compare token probabilities at identical indices, failing to capture semantic similarity. We propose Wasserstein Policy Regularization (WPR), a semantic-aware regularization for the RLHF framework based on the entropy-regularized Wasserstein distance, which incorporates the geometry of the token space. The dual formulation of the distance expresses the regularization as penalty terms applied to the reward via optimal dual variables, which yield a tractable objective compatible with standard RL algorithms. Empirically, our method outperforms KL- and $f$-divergence-based baselines, demonstrating the benefits of semantic-aware policy distances for alignment. Our code is available at https://github.com/aailab-kaist/WPR.
Trajectory-Class-Aware Multi-Agent Reinforcement Learning
Mar 03, 2025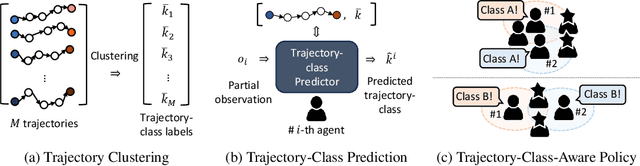


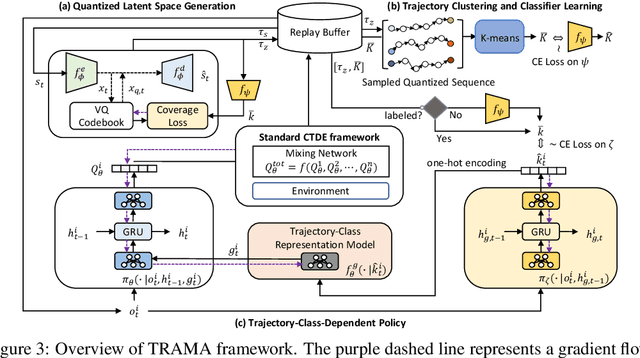
In the context of multi-agent reinforcement learning, generalization is a challenge to solve various tasks that may require different joint policies or coordination without relying on policies specialized for each task. We refer to this type of problem as a multi-task, and we train agents to be versatile in this multi-task setting through a single training process. To address this challenge, we introduce TRajectory-class-Aware Multi-Agent reinforcement learning (TRAMA). In TRAMA, agents recognize a task type by identifying the class of trajectories they are experiencing through partial observations, and the agents use this trajectory awareness or prediction as additional information for action policy. To this end, we introduce three primary objectives in TRAMA: (a) constructing a quantized latent space to generate trajectory embeddings that reflect key similarities among them; (b) conducting trajectory clustering using these trajectory embeddings; and (c) building a trajectory-class-aware policy. Specifically for (c), we introduce a trajectory-class predictor that performs agent-wise predictions on the trajectory class; and we design a trajectory-class representation model for each trajectory class. Each agent takes actions based on this trajectory-class representation along with its partial observation for task-aware execution. The proposed method is evaluated on various tasks, including multi-task problems built upon StarCraft II. Empirical results show further performance improvements over state-of-the-art baselines.
Efficient Episodic Memory Utilization of Cooperative Multi-Agent Reinforcement Learning
Mar 07, 2024



In cooperative multi-agent reinforcement learning (MARL), agents aim to achieve a common goal, such as defeating enemies or scoring a goal. Existing MARL algorithms are effective but still require significant learning time and often get trapped in local optima by complex tasks, subsequently failing to discover a goal-reaching policy. To address this, we introduce Efficient episodic Memory Utilization (EMU) for MARL, with two primary objectives: (a) accelerating reinforcement learning by leveraging semantically coherent memory from an episodic buffer and (b) selectively promoting desirable transitions to prevent local convergence. To achieve (a), EMU incorporates a trainable encoder/decoder structure alongside MARL, creating coherent memory embeddings that facilitate exploratory memory recall. To achieve (b), EMU introduces a novel reward structure called episodic incentive based on the desirability of states. This reward improves the TD target in Q-learning and acts as an additional incentive for desirable transitions. We provide theoretical support for the proposed incentive and demonstrate the effectiveness of EMU compared to conventional episodic control. The proposed method is evaluated in StarCraft II and Google Research Football, and empirical results indicate further performance improvement over state-of-the-art methods.