 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Magnitude Preservation and Rotation Modulation in Diffusion Transformers
May 25, 2025



Denoising diffusion models exhibit remarkable generative capabilities, but remain challenging to train due to their inherent stochasticity, where high-variance gradient estimates lead to slow convergence. Previous works have shown that magnitude preservation helps with stabilizing training in the U-net architecture. This work explores whether this effect extends to the Diffusion Transformer (DiT) architecture. As such, we propose a magnitude-preserving design that stabilizes training without normalization layers. Motivated by the goal of maintaining activation magnitudes, we additionally introduce rotation modulation, which is a novel conditioning method using learned rotations instead of traditional scaling or shifting. Through empirical evaluations and ablation studies on small-scale models, we show that magnitude-preserving strategies significantly improve performance, notably reducing FID scores by $\sim$12.8%. Further, we show that rotation modulation combined with scaling is competitive with AdaLN, while requiring $\sim$5.4% fewer parameters. This work provides insights into conditioning strategies and magnitude control. We will publicly release the implementation of our method.
Autoregressive Distillation of Diffusion Transformers
Apr 15, 2025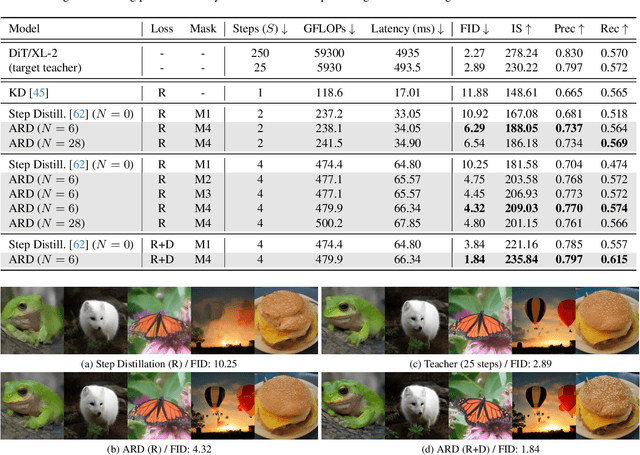
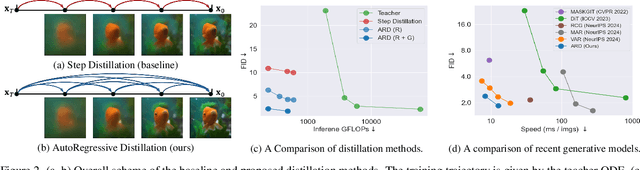
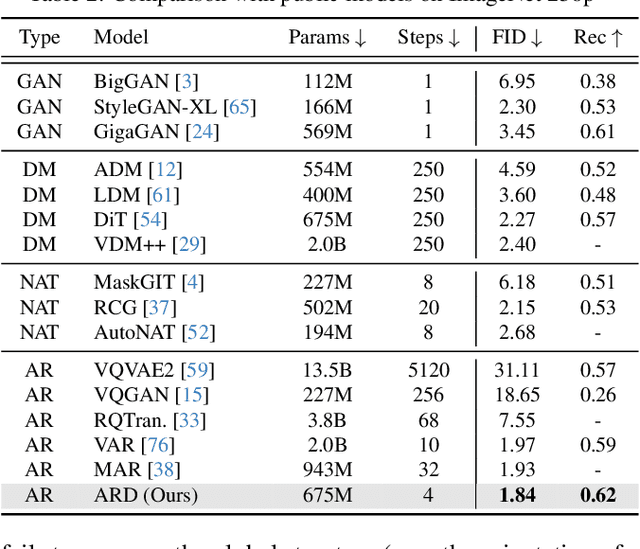
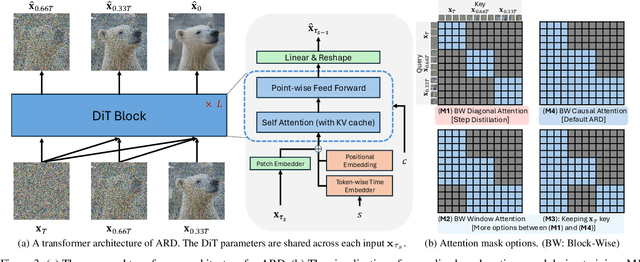
Diffusion models with transformer architectures have demonstrated promising capabilities in generating high-fidelity images and scalability for high resolution. However, iterative sampling process required for synthesis is very resource-intensive. A line of work has focused on distilling solutions to probability flow ODEs into few-step student models. Nevertheless, existing methods have been limited by their reliance on the most recent denoised samples as input, rendering them susceptible to exposure bias. To address this limitation, we propose AutoRegressive Distillation (ARD), a novel approach that leverages the historical trajectory of the ODE to predict future steps. ARD offers two key benefits: 1) it mitigates exposure bias by utilizing a predicted historical trajectory that is less susceptible to accumulated errors, and 2) it leverages the previous history of the ODE trajectory as a more effective source of coarse-grained information. ARD modifies the teacher transformer architecture by adding token-wise time embedding to mark each input from the trajectory history and employs a block-wise causal attention mask for training. Furthermore, incorporating historical inputs only in lower transformer layers enhances performance and efficiency. We validate the effectiveness of ARD in a class-conditioned generation on ImageNet and T2I synthesis. Our model achieves a $5\times$ reduction in FID degradation compared to the baseline methods while requiring only 1.1\% extra FLOPs on ImageNet-256. Moreover, ARD reaches FID of 1.84 on ImageNet-256 in merely 4 steps and outperforms the publicly available 1024p text-to-image distilled models in prompt adherence score with a minimal drop in FID compared to the teacher. Project page: https://github.com/alsdudrla10/ARD.
FlexiDiT: Your Diffusion Transformer Can Easily Generate High-Quality Samples with Less Compute
Feb 27, 2025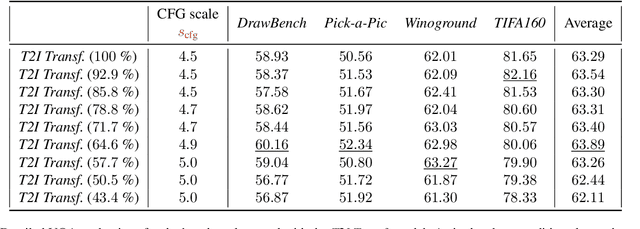


Despite their remarkable performance, modern Diffusion Transformers are hindered by substantial resource requirements during inference, stemming from the fixed and large amount of compute needed for each denoising step. In this work, we revisit the conventional static paradigm that allocates a fixed compute budget per denoising iteration and propose a dynamic strategy instead. Our simple and sample-efficient framework enables pre-trained DiT models to be converted into \emph{flexible} ones -- dubbed FlexiDiT -- allowing them to process inputs at varying compute budgets. We demonstrate how a single \emph{flexible} model can generate images without any drop in quality, while reducing the required FLOPs by more than $40$\% compared to their static counterparts, for both class-conditioned and text-conditioned image generation. Our method is general and agnostic to input and conditioning modalities. We show how our approach can be readily extended for video generation, where FlexiDiT models generate samples with up to $75$\% less compute without compromising performance.
Judge Decoding: Faster Speculative Sampling Requires Going Beyond Model Alignment
Jan 31, 2025



The performance of large language models (LLMs) is closely linked to their underlying size, leading to ever-growing networks and hence slower inference. Speculative decoding has been proposed as a technique to accelerate autoregressive generation, leveraging a fast draft model to propose candidate tokens, which are then verified in parallel based on their likelihood under the target model. While this approach guarantees to reproduce the target output, it incurs a substantial penalty: many high-quality draft tokens are rejected, even when they represent objectively valid continuations. Indeed, we show that even powerful draft models such as GPT-4o, as well as human text cannot achieve high acceptance rates under the standard verification scheme. This severely limits the speedup potential of current speculative decoding methods, as an early rejection becomes overwhelmingly likely when solely relying on alignment of draft and target. We thus ask the following question: Can we adapt verification to recognize correct, but non-aligned replies? To this end, we draw inspiration from the LLM-as-a-judge framework, which demonstrated that LLMs are able to rate answers in a versatile way. We carefully design a dataset to elicit the same capability in the target model by training a compact module on top of the embeddings to produce ``judgements" of the current continuation. We showcase our strategy on the Llama-3.1 family, where our 8b/405B-Judge achieves a speedup of 9x over Llama-405B, while maintaining its quality on a large range of benchmarks. These benefits remain present even in optimized inference frameworks, where our method reaches up to 141 tokens/s for 8B/70B-Judge and 129 tokens/s for 8B/405B on 2 and 8 H100s respectively.
IC-Portrait: In-Context Matching for View-Consistent Personalized Portrait
Jan 31, 2025Existing diffusion models show great potential for identity-preserving generation. However, personalized portrait generation remains challenging due to the diversity in user profiles, including variations in appearance and lighting conditions. To address these challenges, we propose IC-Portrait, a novel framework designed to accurately encode individual identities for personalized portrait generation. Our key insight is that pre-trained diffusion models are fast learners (e.g.,100 ~ 200 steps) for in-context dense correspondence matching, which motivates the two major designs of our IC-Portrait framework. Specifically, we reformulate portrait generation into two sub-tasks: 1) Lighting-Aware Stitching: we find that masking a high proportion of the input image, e.g., 80%, yields a highly effective self-supervisory representation learning of reference image lighting. 2) View-Consistent Adaptation: we leverage a synthetic view-consistent profile dataset to learn the in-context correspondence. The reference profile can then be warped into arbitrary poses for strong spatial-aligned view conditioning. Coupling these two designs by simply concatenating latents to form ControlNet-like supervision and modeling, enables us to significantly enhance the identity preservation fidelity and stability. Extensive evaluations demonstrate that IC-Portrait consistently outperforms existing state-of-the-art methods both quantitatively and qualitatively, with particularly notable improvements in visual qualities. Furthermore, IC-Portrait even demonstrates 3D-aware relighting capabilities.
MegaPortrait: Revisiting Diffusion Control for High-fidelity Portrait Generation
Nov 07, 2024We propose MegaPortrait. It's an innovative system for creating personalized portrait images in computer vision. It has three modules: Identity Net, Shading Net, and Harmonization Net. Identity Net generates learned identity using a customized model fine-tuned with source images. Shading Net re-renders portraits using extracted representations. Harmonization Net fuses pasted faces and the reference image's body for coherent results. Our approach with off-the-shelf Controlnets is better than state-of-the-art AI portrait products in identity preservation and image fidelity. MegaPortrait has a simple but effective design and we compare it with other methods and products to show its superiority.
How Susceptible are LLMs to Influence in Prompts?
Aug 17, 2024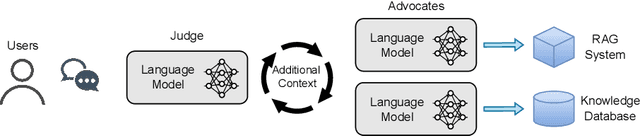



Large Language Models (LLMs) are highly sensitive to prompts, including additional context provided therein. As LLMs grow in capability, understanding their prompt-sensitivity becomes increasingly crucial for ensuring reliable and robust performance, particularly since evaluating these models becomes more challenging. In this work, we investigate how current models (Llama, Mixtral, Falcon) respond when presented with additional input from another model, mimicking a scenario where a more capable model -- or a system with access to more external information -- provides supplementary information to the target model. Across a diverse spectrum of question-answering tasks, we study how an LLM's response to multiple-choice questions changes when the prompt includes a prediction and explanation from another model. Specifically, we explore the influence of the presence of an explanation, the stated authoritativeness of the source, and the stated confidence of the supplementary input. Our findings reveal that models are strongly influenced, and when explanations are provided they are swayed irrespective of the quality of the explanation. The models are more likely to be swayed if the input is presented as being authoritative or confident, but the effect is small in size. This study underscores the significant prompt-sensitivity of LLMs and highlights the potential risks of incorporating outputs from external sources without thorough scrutiny and further validation. As LLMs continue to advance, understanding and mitigating such sensitivities will be crucial for their reliable and trustworthy deployment.
A Language Model's Guide Through Latent Space
Feb 22, 2024Concept guidance has emerged as a cheap and simple way to control the behavior of language models by probing their hidden representations for concept vectors and using them to perturb activations at inference time. While the focus of previous work has largely been on truthfulness, in this paper we extend this framework to a richer set of concepts such as appropriateness, humor, creativity and quality, and explore to what degree current detection and guidance strategies work in these challenging settings. To facilitate evaluation, we develop a novel metric for concept guidance that takes into account both the success of concept elicitation as well as the potential degradation in fluency of the guided model. Our extensive experiments reveal that while some concepts such as truthfulness more easily allow for guidance with current techniques, novel concepts such as appropriateness or humor either remain difficult to elicit, need extensive tuning to work, or even experience confusion. Moreover, we find that probes with optimal detection accuracies do not necessarily make for the optimal guides, contradicting previous observations for truthfulness. Our work warrants a deeper investigation into the interplay between detectability, guidability, and the nature of the concept, and we hope that our rich experimental test-bed for guidance research inspires stronger follow-up approaches.
Towards Meta-Pruning via Optimal Transport
Feb 13, 2024Structural pruning of neural networks conventionally relies on identifying and discarding less important neurons, a practice often resulting in significant accuracy loss that necessitates subsequent fine-tuning efforts. This paper introduces a novel approach named Intra-Fusion, challenging this prevailing pruning paradigm. Unlike existing methods that focus on designing meaningful neuron importance metrics, Intra-Fusion redefines the overlying pruning procedure. Through utilizing the concepts of model fusion and Optimal Transport, we leverage an agnostically given importance metric to arrive at a more effective sparse model representation. Notably, our approach achieves substantial accuracy recovery without the need for resource-intensive fine-tuning, making it an efficient and promising tool for neural network compression. Additionally, we explore how fusion can be added to the pruning process to significantly decrease the training time while maintaining competitive performance. We benchmark our results for various networks on commonly used datasets such as CIFAR-10, CIFAR-100, and ImageNet. More broadly, we hope that the proposed Intra-Fusion approach invigorates exploration into a fresh alternative to the predominant compression approaches. Our code is available here: https://github.com/alexandertheus/Intra-Fusion.
Harnessing Synthetic Datasets: The Role of Shape Bias in Deep Neural Network Generalization
Nov 10, 2023Recent advancements in deep learning have been primarily driven by the use of large models trained on increasingly vast datasets. While neural scaling laws have emerged to predict network performance given a specific level of computational resources, the growing demand for expansive datasets raises concerns. To address this, a new research direction has emerged, focusing on the creation of synthetic data as a substitute. In this study, we investigate how neural networks exhibit shape bias during training on synthetic datasets, serving as an indicator of the synthetic data quality. Specifically, our findings indicate three key points: (1) Shape bias varies across network architectures and types of supervision, casting doubt on its reliability as a predictor for generalization and its ability to explain differences in model recognition compared to human capabilities. (2) Relying solely on shape bias to estimate generalization is unreliable, as it is entangled with diversity and naturalism. (3) We propose a novel interpretation of shape bias as a tool for estimating the diversity of samples within a dataset. Our research aims to clarify the implications of using synthetic data and its associated shape bias in deep learning, addressing concerns regarding generalization and dataset quality.