 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOxygenREC: An Instruction-Following Generative Framework for E-commerce Recommendation
Dec 31, 2025Traditional recommendation systems suffer from inconsistency in multi-stage optimization objectives. Generative Recommendation (GR) mitigates them through an end-to-end framework; however, existing methods still rely on matching mechanisms based on inductive patterns. Although responsive, they lack the ability to uncover complex user intents that require deductive reasoning based on world knowledge. Meanwhile, LLMs show strong deep reasoning capabilities, but their latency and computational costs remain challenging for industrial applications. More critically, there are performance bottlenecks in multi-scenario scalability: as shown in Figure 1, existing solutions require independent training and deployment for each scenario, leading to low resource utilization and high maintenance costs-a challenge unaddressed in GR literature. To address these, we present OxygenREC, an industrial recommendation system that leverages Fast-Slow Thinking to deliver deep reasoning with strict latency and multi-scenario requirements of real-world environments. First, we adopt a Fast-Slow Thinking architecture. Slow thinking uses a near-line LLM pipeline to synthesize Contextual Reasoning Instructions, while fast thinking employs a high-efficiency encoder-decoder backbone for real-time generation. Second, to ensure reasoning instructions effectively enhance recommendation generation, we introduce a semantic alignment mechanism with Instruction-Guided Retrieval (IGR) to filter intent-relevant historical behaviors and use a Query-to-Item (Q2I) loss for instruction-item consistency. Finally, to resolve multi-scenario scalability, we transform scenario information into controllable instructions, using unified reward mapping and Soft Adaptive Group Clip Policy Optimization (SA-GCPO) to align policies with diverse business objectives, realizing a train-once-deploy-everywhere paradigm.
IC-Portrait: In-Context Matching for View-Consistent Personalized Portrait
Jan 31, 2025Existing diffusion models show great potential for identity-preserving generation. However, personalized portrait generation remains challenging due to the diversity in user profiles, including variations in appearance and lighting conditions. To address these challenges, we propose IC-Portrait, a novel framework designed to accurately encode individual identities for personalized portrait generation. Our key insight is that pre-trained diffusion models are fast learners (e.g.,100 ~ 200 steps) for in-context dense correspondence matching, which motivates the two major designs of our IC-Portrait framework. Specifically, we reformulate portrait generation into two sub-tasks: 1) Lighting-Aware Stitching: we find that masking a high proportion of the input image, e.g., 80%, yields a highly effective self-supervisory representation learning of reference image lighting. 2) View-Consistent Adaptation: we leverage a synthetic view-consistent profile dataset to learn the in-context correspondence. The reference profile can then be warped into arbitrary poses for strong spatial-aligned view conditioning. Coupling these two designs by simply concatenating latents to form ControlNet-like supervision and modeling, enables us to significantly enhance the identity preservation fidelity and stability. Extensive evaluations demonstrate that IC-Portrait consistently outperforms existing state-of-the-art methods both quantitatively and qualitatively, with particularly notable improvements in visual qualities. Furthermore, IC-Portrait even demonstrates 3D-aware relighting capabilities.
High-Fidelity Virtual Try-on with Large-Scale Unpaired Learning
Nov 03, 2024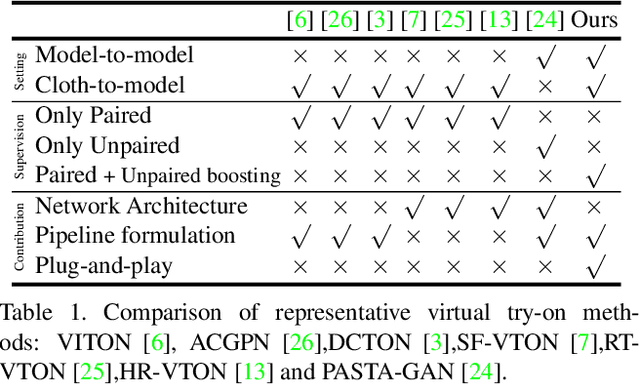



Virtual try-on (VTON) transfers a target clothing image to a reference person, where clothing fidelity is a key requirement for downstream e-commerce applications. However, existing VTON methods still fall short in high-fidelity try-on due to the conflict between the high diversity of dressing styles (\eg clothes occluded by pants or distorted by posture) and the limited paired data for training. In this work, we propose a novel framework \textbf{Boosted Virtual Try-on (BVTON)} to leverage the large-scale unpaired learning for high-fidelity try-on. Our key insight is that pseudo try-on pairs can be reliably constructed from vastly available fashion images. Specifically, \textbf{1)} we first propose a compositional canonicalizing flow that maps on-model clothes into pseudo in-shop clothes, dubbed canonical proxy. Each clothing part (sleeves, torso) is reversely deformed into an in-shop-like shape to compositionally construct the canonical proxy. \textbf{2)} Next, we design a layered mask generation module that generates accurate semantic layout by training on canonical proxy. We replace the in-shop clothes used in conventional pipelines with the derived canonical proxy to boost the training process. \textbf{3)} Finally, we propose an unpaired try-on synthesizer by constructing pseudo training pairs with randomly misaligned on-model clothes, where intricate skin texture and clothes boundaries can be generated. Extensive experiments on high-resolution ($1024\times768$) datasets demonstrate the superiority of our approach over state-of-the-art methods both qualitatively and quantitatively. Notably, BVTON shows great generalizability and scalability to various dressing styles and data sources.
Product-Level Try-on: Characteristics-preserving Try-on with Realistic Clothes Shading and Wrinkles
Jan 20, 2024Image-based virtual try-on systems,which fit new garments onto human portraits,are gaining research attention.An ideal pipeline should preserve the static features of clothes(like textures and logos)while also generating dynamic elements(e.g.shadows,folds)that adapt to the model's pose and environment.Previous works fail specifically in generating dynamic features,as they preserve the warped in-shop clothes trivially with predicted an alpha mask by composition.To break the dilemma of over-preserving and textures losses,we propose a novel diffusion-based Product-level virtual try-on pipeline,\ie PLTON, which can preserve the fine details of logos and embroideries while producing realistic clothes shading and wrinkles.The main insights are in three folds:1)Adaptive Dynamic Rendering:We take a pre-trained diffusion model as a generative prior and tame it with image features,training a dynamic extractor from scratch to generate dynamic tokens that preserve high-fidelity semantic information. Due to the strong generative power of the diffusion prior,we can generate realistic clothes shadows and wrinkles.2)Static Characteristics Transformation: High-frequency Map(HF-Map)is our fundamental insight for static representation.PLTON first warps in-shop clothes to the target model pose by a traditional warping network,and uses a high-pass filter to extract an HF-Map for preserving static cloth features.The HF-Map is used to generate modulation maps through our static extractor,which are injected into a fixed U-net to synthesize the final result.To enhance retention,a Two-stage Blended Denoising method is proposed to guide the diffusion process for correct spatial layout and color.PLTON is finetuned only with our collected small-size try-on dataset.Extensive quantitative and qualitative experiments on 1024 768 datasets demonstrate the superiority of our framework in mimicking real clothes dynamics.