 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Bias Injection Attacks against Text-to-Image Diffusion Models
Apr 02, 2025



The proliferation of text-to-image diffusion models (T2I DMs) has led to an increased presence of AI-generated images in daily life. However, biased T2I models can generate content with specific tendencies, potentially influencing people's perceptions. Intentional exploitation of these biases risks conveying misleading information to the public. Current research on bias primarily addresses explicit biases with recognizable visual patterns, such as skin color and gender. This paper introduces a novel form of implicit bias that lacks explicit visual features but can manifest in diverse ways across various semantic contexts. This subtle and versatile nature makes this bias challenging to detect, easy to propagate, and adaptable to a wide range of scenarios. We further propose an implicit bias injection attack framework (IBI-Attacks) against T2I diffusion models by precomputing a general bias direction in the prompt embedding space and adaptively adjusting it based on different inputs. Our attack module can be seamlessly integrated into pre-trained diffusion models in a plug-and-play manner without direct manipulation of user input or model retraining. Extensive experiments validate the effectiveness of our scheme in introducing bias through subtle and diverse modifications while preserving the original semantics. The strong concealment and transferability of our attack across various scenarios further underscore the significance of our approach. Code is available at https://github.com/Hannah1102/IBI-attacks.
TarPro: Targeted Protection against Malicious Image Editing
Mar 18, 2025The rapid advancement of image editing techniques has raised concerns about their misuse for generating Not-Safe-for-Work (NSFW) content. This necessitates a targeted protection mechanism that blocks malicious edits while preserving normal editability. However, existing protection methods fail to achieve this balance, as they indiscriminately disrupt all edits while still allowing some harmful content to be generated. To address this, we propose TarPro, a targeted protection framework that prevents malicious edits while maintaining benign modifications. TarPro achieves this through a semantic-aware constraint that only disrupts malicious content and a lightweight perturbation generator that produces a more stable, imperceptible, and robust perturbation for image protection. Extensive experiments demonstrate that TarPro surpasses existing methods, achieving a high protection efficacy while ensuring minimal impact on normal edits. Our results highlight TarPro as a practical solution for secure and controlled image editing.
Redistribute Ensemble Training for Mitigating Memorization in Diffusion Models
Feb 13, 2025Diffusion models, known for their tremendous ability to generate high-quality samples, have recently raised concerns due to their data memorization behavior, which poses privacy risks. Recent methods for memory mitigation have primarily addressed the issue within the context of the text modality in cross-modal generation tasks, restricting their applicability to specific conditions. In this paper, we propose a novel method for diffusion models from the perspective of visual modality, which is more generic and fundamental for mitigating memorization. Directly exposing visual data to the model increases memorization risk, so we design a framework where models learn through proxy model parameters instead. Specially, the training dataset is divided into multiple shards, with each shard training a proxy model, then aggregated to form the final model. Additionally, practical analysis of training losses illustrates that the losses for easily memorable images tend to be obviously lower. Thus, we skip the samples with abnormally low loss values from the current mini-batch to avoid memorizing. However, balancing the need to skip memorization-prone samples while maintaining sufficient training data for high-quality image generation presents a key challenge. Thus, we propose IET-AGC+, which redistributes highly memorizable samples between shards, to mitigate these samples from over-skipping. Furthermore, we dynamically augment samples based on their loss values to further reduce memorization. Extensive experiments and analysis on four datasets show that our method successfully reduces memory capacity while maintaining performance. Moreover, we fine-tune the pre-trained diffusion models, e.g., Stable Diffusion, and decrease the memorization score by 46.7\%, demonstrating the effectiveness of our method. Code is available in: https://github.com/liuxiao-guan/IET_AGC.
Image Regeneration: Evaluating Text-to-Image Model via Generating Identical Image with Multimodal Large Language Models
Nov 14, 2024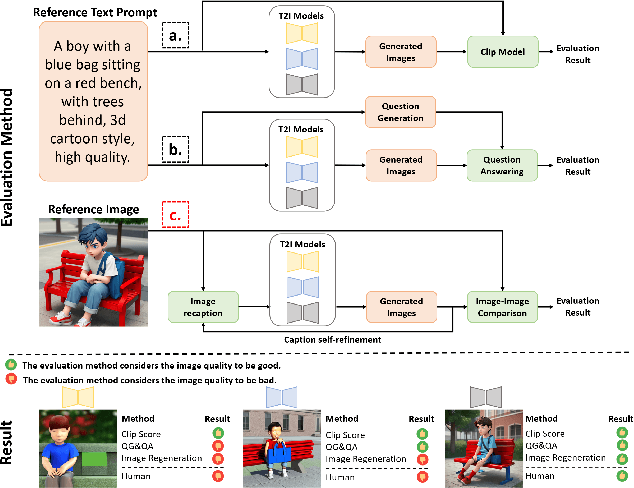



Diffusion models have revitalized the image generation domain, playing crucial roles in both academic research and artistic expression. With the emergence of new diffusion models, assessing the performance of text-to-image models has become increasingly important. Current metrics focus on directly matching the input text with the generated image, but due to cross-modal information asymmetry, this leads to unreliable or incomplete assessment results. Motivated by this, we introduce the Image Regeneration task in this study to assess text-to-image models by tasking the T2I model with generating an image according to the reference image. We use GPT4V to bridge the gap between the reference image and the text input for the T2I model, allowing T2I models to understand image content. This evaluation process is simplified as comparisons between the generated image and the reference image are straightforward. Two regeneration datasets spanning content-diverse and style-diverse evaluation dataset are introduced to evaluate the leading diffusion models currently available. Additionally, we present ImageRepainter framework to enhance the quality of generated images by improving content comprehension via MLLM guided iterative generation and revision. Our comprehensive experiments have showcased the effectiveness of this framework in assessing the generative capabilities of models. By leveraging MLLM, we have demonstrated that a robust T2M can produce images more closely resembling the reference image.
Iterative Ensemble Training with Anti-Gradient Control for Mitigating Memorization in Diffusion Models
Jul 22, 2024Diffusion models, known for their tremendous ability to generate novel and high-quality samples, have recently raised concerns due to their data memorization behavior, which poses privacy risks. Recent approaches for memory mitigation either only focused on the text modality problem in cross-modal generation tasks or utilized data augmentation strategies. In this paper, we propose a novel training framework for diffusion models from the perspective of visual modality, which is more generic and fundamental for mitigating memorization. To facilitate ``forgetting'' of stored information in diffusion model parameters, we propose an iterative ensemble training strategy by splitting the data into multiple shards for training multiple models and intermittently aggregating these model parameters. Moreover, practical analysis of losses illustrates that the training loss for easily memorable images tends to be obviously lower. Thus, we propose an anti-gradient control method to exclude the sample with a lower loss value from the current mini-batch to avoid memorizing. Extensive experiments and analysis on \crnote{four} datasets are conducted to illustrate the effectiveness of our method, and results show that our method successfully reduces memory capacity while even improving the performance slightly. Moreover, to save the computing cost, we successfully apply our method to fine-tune the well-trained diffusion models by limited epochs, demonstrating the applicability of our method. Code is available in https://github.com/liuxiao-guan/IET_AGC.
Product-Level Try-on: Characteristics-preserving Try-on with Realistic Clothes Shading and Wrinkles
Jan 20, 2024Image-based virtual try-on systems,which fit new garments onto human portraits,are gaining research attention.An ideal pipeline should preserve the static features of clothes(like textures and logos)while also generating dynamic elements(e.g.shadows,folds)that adapt to the model's pose and environment.Previous works fail specifically in generating dynamic features,as they preserve the warped in-shop clothes trivially with predicted an alpha mask by composition.To break the dilemma of over-preserving and textures losses,we propose a novel diffusion-based Product-level virtual try-on pipeline,\ie PLTON, which can preserve the fine details of logos and embroideries while producing realistic clothes shading and wrinkles.The main insights are in three folds:1)Adaptive Dynamic Rendering:We take a pre-trained diffusion model as a generative prior and tame it with image features,training a dynamic extractor from scratch to generate dynamic tokens that preserve high-fidelity semantic information. Due to the strong generative power of the diffusion prior,we can generate realistic clothes shadows and wrinkles.2)Static Characteristics Transformation: High-frequency Map(HF-Map)is our fundamental insight for static representation.PLTON first warps in-shop clothes to the target model pose by a traditional warping network,and uses a high-pass filter to extract an HF-Map for preserving static cloth features.The HF-Map is used to generate modulation maps through our static extractor,which are injected into a fixed U-net to synthesize the final result.To enhance retention,a Two-stage Blended Denoising method is proposed to guide the diffusion process for correct spatial layout and color.PLTON is finetuned only with our collected small-size try-on dataset.Extensive quantitative and qualitative experiments on 1024 768 datasets demonstrate the superiority of our framework in mimicking real clothes dynamics.
Logic-induced Diagnostic Reasoning for Semi-supervised Semantic Segmentation
Aug 24, 2023



Recent advances in semi-supervised semantic segmentation have been heavily reliant on pseudo labeling to compensate for limited labeled data, disregarding the valuable relational knowledge among semantic concepts. To bridge this gap, we devise LogicDiag, a brand new neural-logic semi-supervised learning framework. Our key insight is that conflicts within pseudo labels, identified through symbolic knowledge, can serve as strong yet commonly ignored learning signals. LogicDiag resolves such conflicts via reasoning with logic-induced diagnoses, enabling the recovery of (potentially) erroneous pseudo labels, ultimately alleviating the notorious error accumulation problem. We showcase the practical application of LogicDiag in the data-hungry segmentation scenario, where we formalize the structured abstraction of semantic concepts as a set of logic rules. Extensive experiments on three standard semi-supervised semantic segmentation benchmarks demonstrate the effectiveness and generality of LogicDiag. Moreover, LogicDiag highlights the promising opportunities arising from the systematic integration of symbolic reasoning into the prevalent statistical, neural learning approaches.
GMMSeg: Gaussian Mixture based Generative Semantic Segmentation Models
Oct 05, 2022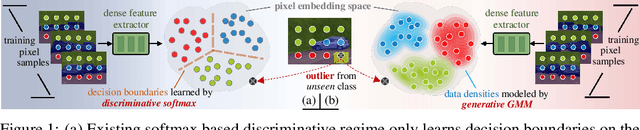



Prevalent semantic segmentation solutions are, in essence, a dense discriminative classifier of p(class|pixel feature). Though straightforward, this de facto paradigm neglects the underlying data distribution p(pixel feature|class), and struggles to identify out-of-distribution data. Going beyond this, we propose GMMSeg, a new family of segmentation models that rely on a dense generative classifier for the joint distribution p(pixel feature,class). For each class, GMMSeg builds Gaussian Mixture Models (GMMs) via Expectation-Maximization (EM), so as to capture class-conditional densities. Meanwhile, the deep dense representation is end-to-end trained in a discriminative manner, i.e., maximizing p(class|pixel feature). This endows GMMSeg with the strengths of both generative and discriminative models. With a variety of segmentation architectures and backbones, GMMSeg outperforms the discriminative counterparts on three closed-set datasets. More impressively, without any modification, GMMSeg even performs well on open-world datasets. We believe this work brings fundamental insights into the related fields.
MHR-Net: Multiple-Hypothesis Reconstruction of Non-Rigid Shapes from 2D Views
Jul 19, 2022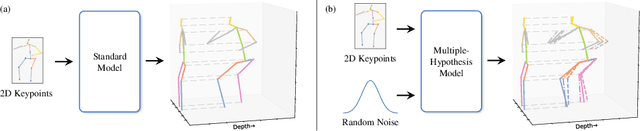
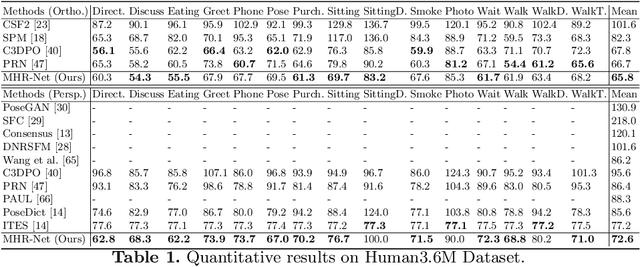
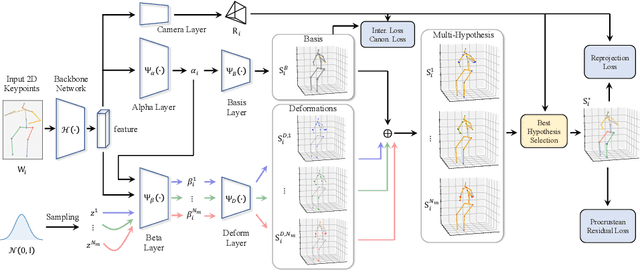

We propose MHR-Net, a novel method for recovering Non-Rigid Shapes from Motion (NRSfM). MHR-Net aims to find a set of reasonable reconstructions for a 2D view, and it also selects the most likely reconstruction from the set. To deal with the challenging unsupervised generation of non-rigid shapes, we develop a new Deterministic Basis and Stochastic Deformation scheme in MHR-Net. The non-rigid shape is first expressed as the sum of a coarse shape basis and a flexible shape deformation, then multiple hypotheses are generated with uncertainty modeling of the deformation part. MHR-Net is optimized with reprojection loss on the basis and the best hypothesis. Furthermore, we design a new Procrustean Residual Loss, which reduces the rigid rotations between similar shapes and further improves the performance. Experiments show that MHR-Net achieves state-of-the-art reconstruction accuracy on Human3.6M, SURREAL and 300-VW datasets.
Associating Objects with Scalable Transformers for Video Object Segmentation
Mar 27, 2022


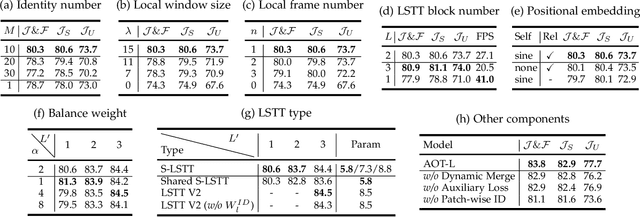
This paper investigates how to realize better and more efficient embedding learning to tackle the semi-supervised video object segmentation under challenging multi-object scenarios. The state-of-the-art methods learn to decode features with a single positive object and thus have to match and segment each target separately under multi-object scenarios, consuming multiple times computation resources. To solve the problem, we propose an Associating Objects with Transformers (AOT) approach to match and decode multiple objects jointly and collaboratively. In detail, AOT employs an identification mechanism to associate multiple targets into the same high-dimensional embedding space. Thus, we can simultaneously process multiple objects' matching and segmentation decoding as efficiently as processing a single object. To sufficiently model multi-object association, a Long Short-Term Transformer (LSTT) is devised to construct hierarchical matching and propagation. Based on AOT, we further propose a more flexible and robust framework, Associating Objects with Scalable Transformers (AOST), in which a scalable version of LSTT is designed to enable run-time adaptation of accuracy-efficiency trade-offs. Besides, AOST introduces a better layer-wise manner to couple identification and vision embeddings. We conduct extensive experiments on multi-object and single-object benchmarks to examine AOT series frameworks. Compared to the state-of-the-art competitors, our methods can maintain times of run-time efficiency with superior performance. Notably, we achieve new state-of-the-art performance on three popular benchmarks, i.e., YouTube-VOS (86.5%), DAVIS 2017 Val/Test (87.0%/84.7%), and DAVIS 2016 (93.0%). Project page: https://github.com/z-x-yang/AOT.