 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssociating Objects with Scalable Transformers for Video Object Segmentation
Paper and Code



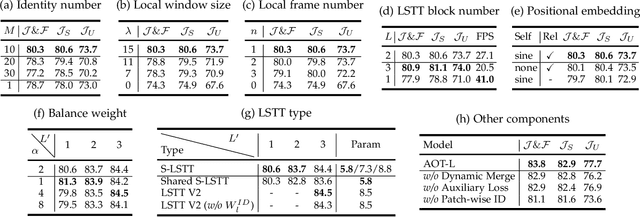
This paper investigates how to realize better and more efficient embedding learning to tackle the semi-supervised video object segmentation under challenging multi-object scenarios. The state-of-the-art methods learn to decode features with a single positive object and thus have to match and segment each target separately under multi-object scenarios, consuming multiple times computation resources. To solve the problem, we propose an Associating Objects with Transformers (AOT) approach to match and decode multiple objects jointly and collaboratively. In detail, AOT employs an identification mechanism to associate multiple targets into the same high-dimensional embedding space. Thus, we can simultaneously process multiple objects' matching and segmentation decoding as efficiently as processing a single object. To sufficiently model multi-object association, a Long Short-Term Transformer (LSTT) is devised to construct hierarchical matching and propagation. Based on AOT, we further propose a more flexible and robust framework, Associating Objects with Scalable Transformers (AOST), in which a scalable version of LSTT is designed to enable run-time adaptation of accuracy-efficiency trade-offs. Besides, AOST introduces a better layer-wise manner to couple identification and vision embeddings. We conduct extensive experiments on multi-object and single-object benchmarks to examine AOT series frameworks. Compared to the state-of-the-art competitors, our methods can maintain times of run-time efficiency with superior performance. Notably, we achieve new state-of-the-art performance on three popular benchmarks, i.e., YouTube-VOS (86.5%), DAVIS 2017 Val/Test (87.0%/84.7%), and DAVIS 2016 (93.0%). Project page: https://github.com/z-x-yang/AOT.