 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKefa: A Knowledge Enhanced and Fine-grained Aligned Speaker for Navigation Instruction Generation
Jul 25, 2023We introduce a novel speaker model \textsc{Kefa} for navigation instruction generation. The existing speaker models in Vision-and-Language Navigation suffer from the large domain gap of vision features between different environments and insufficient temporal grounding capability. To address the challenges, we propose a Knowledge Refinement Module to enhance the feature representation with external knowledge facts, and an Adaptive Temporal Alignment method to enforce fine-grained alignment between the generated instructions and the observation sequences. Moreover, we propose a new metric SPICE-D for navigation instruction evaluation, which is aware of the correctness of direction phrases. The experimental results on R2R and UrbanWalk datasets show that the proposed KEFA speaker achieves state-of-the-art instruction generation performance for both indoor and outdoor scenes.
MHR-Net: Multiple-Hypothesis Reconstruction of Non-Rigid Shapes from 2D Views
Jul 19, 2022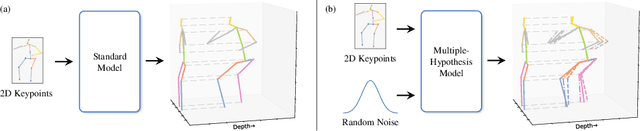
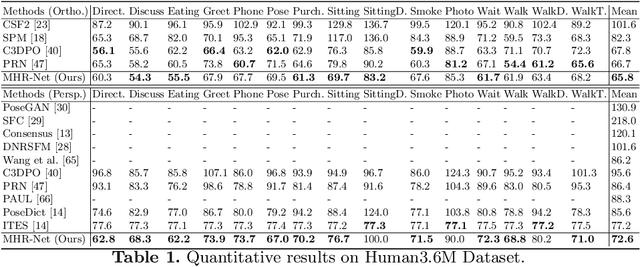
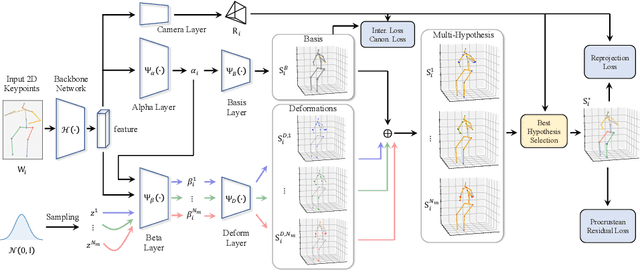

We propose MHR-Net, a novel method for recovering Non-Rigid Shapes from Motion (NRSfM). MHR-Net aims to find a set of reasonable reconstructions for a 2D view, and it also selects the most likely reconstruction from the set. To deal with the challenging unsupervised generation of non-rigid shapes, we develop a new Deterministic Basis and Stochastic Deformation scheme in MHR-Net. The non-rigid shape is first expressed as the sum of a coarse shape basis and a flexible shape deformation, then multiple hypotheses are generated with uncertainty modeling of the deformation part. MHR-Net is optimized with reprojection loss on the basis and the best hypothesis. Furthermore, we design a new Procrustean Residual Loss, which reduces the rigid rotations between similar shapes and further improves the performance. Experiments show that MHR-Net achieves state-of-the-art reconstruction accuracy on Human3.6M, SURREAL and 300-VW datasets.
PR-RRN: Pairwise-Regularized Residual-Recursive Networks for Non-rigid Structure-from-Motion
Aug 17, 2021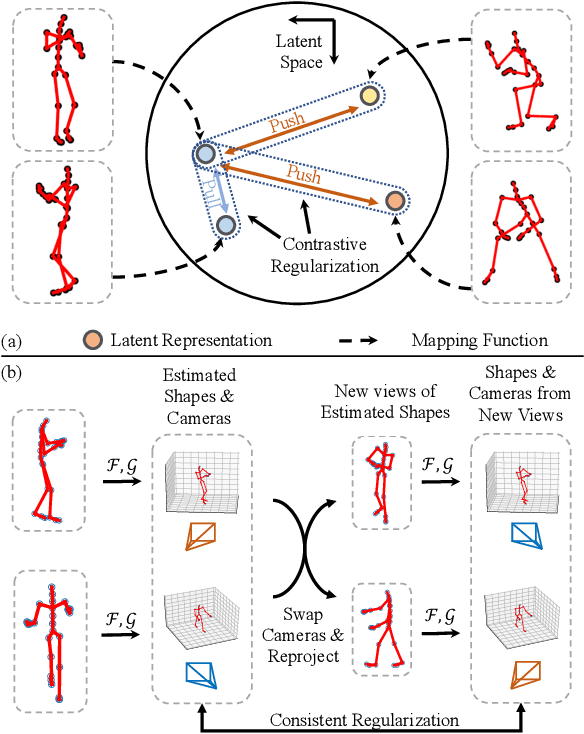
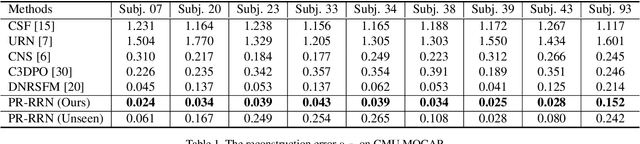
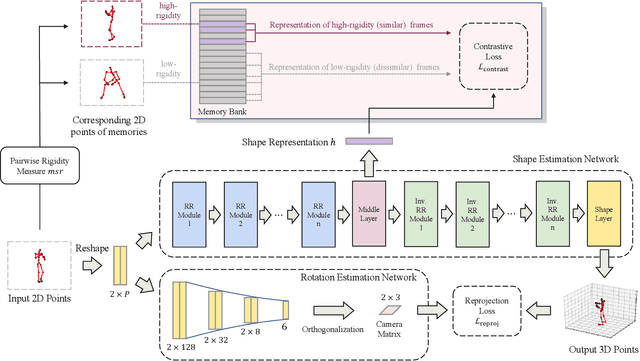

We propose PR-RRN, a novel neural-network based method for Non-rigid Structure-from-Motion (NRSfM). PR-RRN consists of Residual-Recursive Networks (RRN) and two extra regularization losses. RRN is designed to effectively recover 3D shape and camera from 2D keypoints with novel residual-recursive structure. As NRSfM is a highly under-constrained problem, we propose two new pairwise regularization to further regularize the reconstruction. The Rigidity-based Pairwise Contrastive Loss regularizes the shape representation by encouraging higher similarity between the representations of high-rigidity pairs of frames than low-rigidity pairs. We propose minimum singular-value ratio to measure the pairwise rigidity. The Pairwise Consistency Loss enforces the reconstruction to be consistent when the estimated shapes and cameras are exchanged between pairs. Our approach achieves state-of-the-art performance on CMU MOCAP and PASCAL3D+ dataset.
Multi-Task Learning via Co-Attentive Sharing for Pedestrian Attribute Recognition
Apr 07, 2020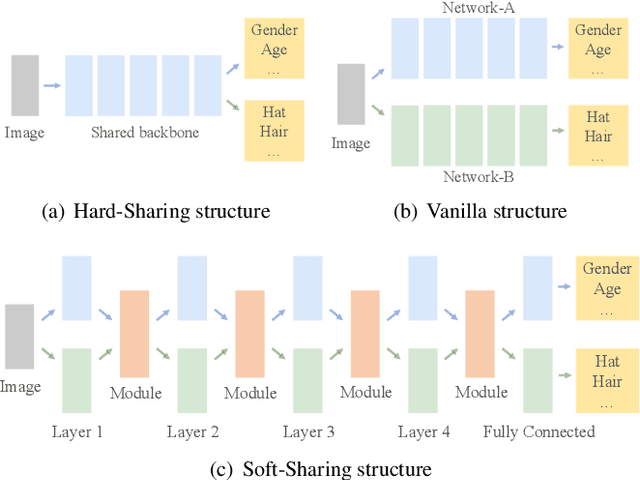
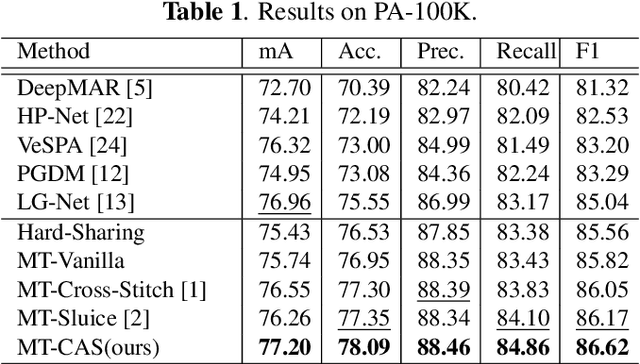
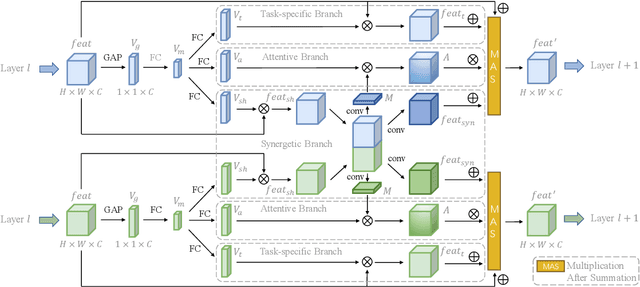
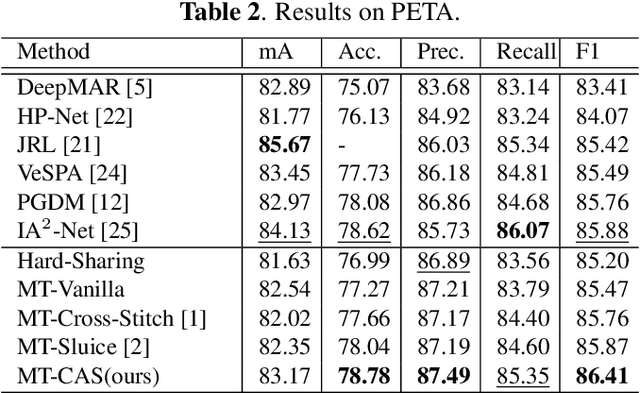
Learning to predict multiple attributes of a pedestrian is a multi-task learning problem. To share feature representation between two individual task networks, conventional methods like Cross-Stitch and Sluice network learn a linear combination of features or feature subspaces. However, linear combination rules out the complex interdependency between channels. Moreover, spatial information exchanging is less-considered. In this paper, we propose a novel Co-Attentive Sharing (CAS) module which extracts discriminative channels and spatial regions for more effective feature sharing in multi-task learning. The module consists of three branches, which leverage different channels for between-task feature fusing, attention generation and task-specific feature enhancing, respectively. Experiments on two pedestrian attribute recognition datasets show that our module outperforms the conventional sharing units and achieves superior results compared to the state-of-the-art approaches using many metrics.