 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMemory: Toward Consistent Video Generation via Memory Integration
Jan 07, 2026Maintaining consistent characters, props, and environments across multiple shots is a central challenge in narrative video generation. Existing models can produce high-quality short clips but often fail to preserve entity identity and appearance when scenes change or when entities reappear after long temporal gaps. We present VideoMemory, an entity-centric framework that integrates narrative planning with visual generation through a Dynamic Memory Bank. Given a structured script, a multi-agent system decomposes the narrative into shots, retrieves entity representations from memory, and synthesizes keyframes and videos conditioned on these retrieved states. The Dynamic Memory Bank stores explicit visual and semantic descriptors for characters, props, and backgrounds, and is updated after each shot to reflect story-driven changes while preserving identity. This retrieval-update mechanism enables consistent portrayal of entities across distant shots and supports coherent long-form generation. To evaluate this setting, we construct a 54-case multi-shot consistency benchmark covering character-, prop-, and background-persistent scenarios. Extensive experiments show that VideoMemory achieves strong entity-level coherence and high perceptual quality across diverse narrative sequences.
Spatiotemporal Transformer for Video-based Person Re-identification
Mar 30, 2021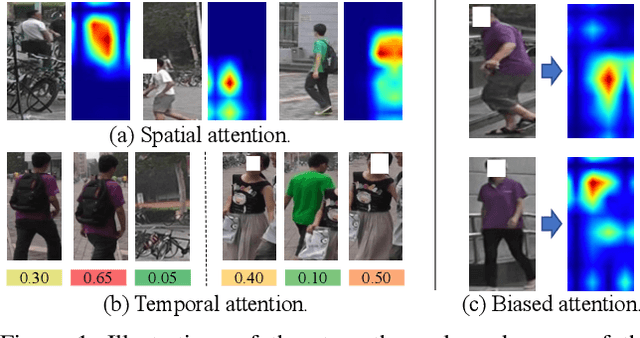
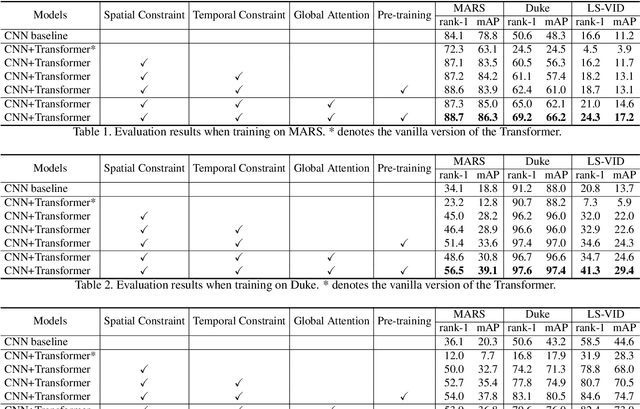
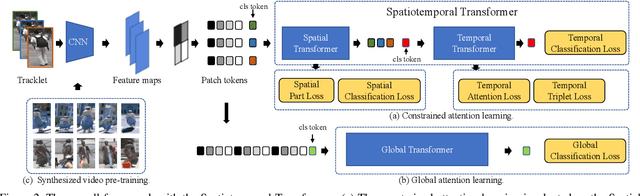
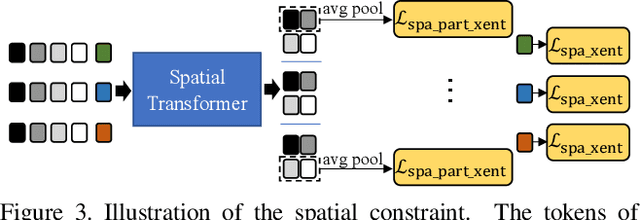
Recently, the Transformer module has been transplanted from natural language processing to computer vision. This paper applies the Transformer to video-based person re-identification, where the key issue is to extract the discriminative information from a tracklet. We show that, despite the strong learning ability, the vanilla Transformer suffers from an increased risk of over-fitting, arguably due to a large number of attention parameters and insufficient training data. To solve this problem, we propose a novel pipeline where the model is pre-trained on a set of synthesized video data and then transferred to the downstream domains with the perception-constrained Spatiotemporal Transformer (STT) module and Global Transformer (GT) module. The derived algorithm achieves significant accuracy gain on three popular video-based person re-identification benchmarks, MARS, DukeMTMC-VideoReID, and LS-VID, especially when the training and testing data are from different domains. More importantly, our research sheds light on the application of the Transformer on highly-structured visual data.
UnrealPerson: An Adaptive Pipeline towards Costless Person Re-identification
Dec 09, 2020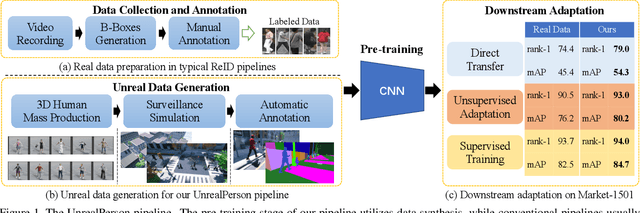

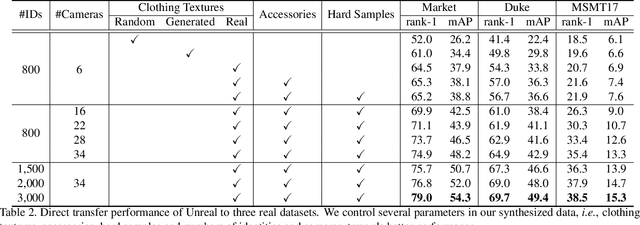

The main difficulty of person re-identification (ReID) lies in collecting annotated data and transferring the model across different domains. This paper presents UnrealPerson, a novel pipeline that makes full use of unreal image data to decrease the costs in both the training and deployment stages. Its fundamental part is a system that can generate synthesized images of high-quality and from controllable distributions. Instance-level annotation goes with the synthesized data and is almost free. We point out some details in image synthesis that largely impact the data quality. With 3,000 IDs and 120,000 instances, our method achieves a 38.5% rank-1 accuracy when being directly transferred to MSMT17. It almost doubles the former record using synthesized data and even surpasses previous direct transfer records using real data. This offers a good basis for unsupervised domain adaption, where our pre-trained model is easily plugged into the state-of-the-art algorithms towards higher accuracy. In addition, the data distribution can be flexibly adjusted to fit some corner ReID scenarios, which widens the application of our pipeline. We will publish our data synthesis toolkit and synthesized data in https://github.com/FlyHighest/UnrealPerson.
Multi-Task Learning via Co-Attentive Sharing for Pedestrian Attribute Recognition
Apr 07, 2020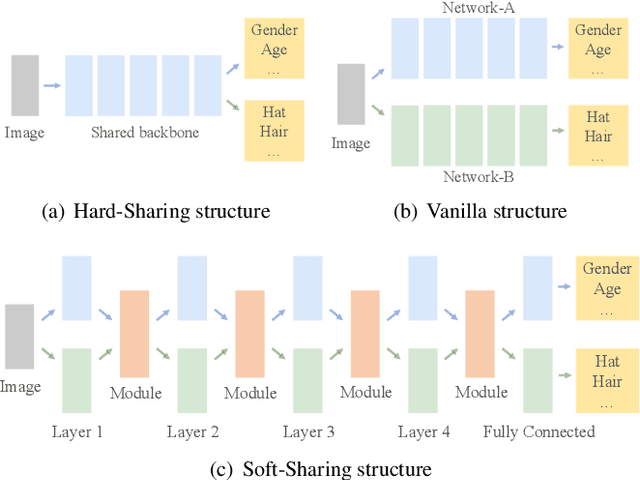
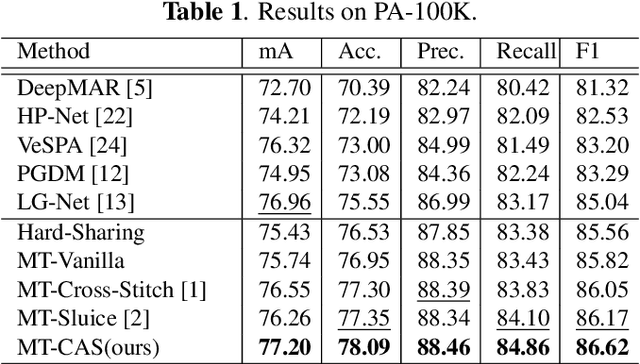
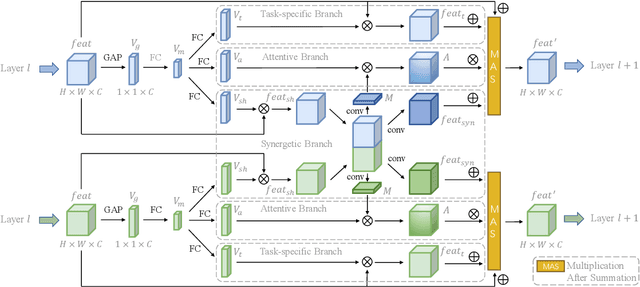
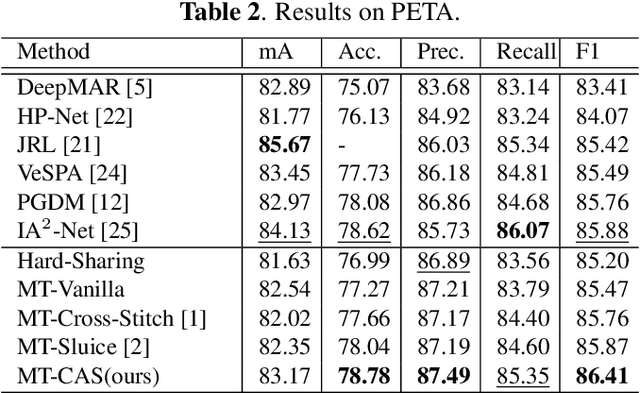
Learning to predict multiple attributes of a pedestrian is a multi-task learning problem. To share feature representation between two individual task networks, conventional methods like Cross-Stitch and Sluice network learn a linear combination of features or feature subspaces. However, linear combination rules out the complex interdependency between channels. Moreover, spatial information exchanging is less-considered. In this paper, we propose a novel Co-Attentive Sharing (CAS) module which extracts discriminative channels and spatial regions for more effective feature sharing in multi-task learning. The module consists of three branches, which leverage different channels for between-task feature fusing, attention generation and task-specific feature enhancing, respectively. Experiments on two pedestrian attribute recognition datasets show that our module outperforms the conventional sharing units and achieves superior results compared to the state-of-the-art approaches using many metrics.
Cross-View Tracking for Multi-Human 3D Pose Estimation at over 100 FPS
Mar 09, 2020
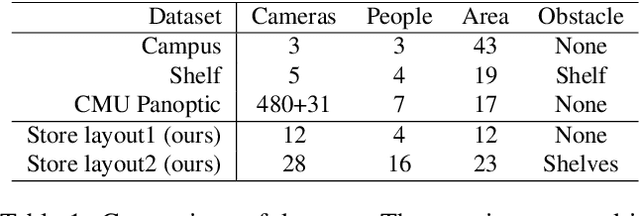
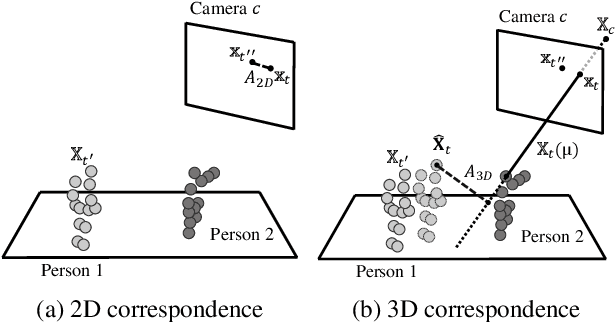
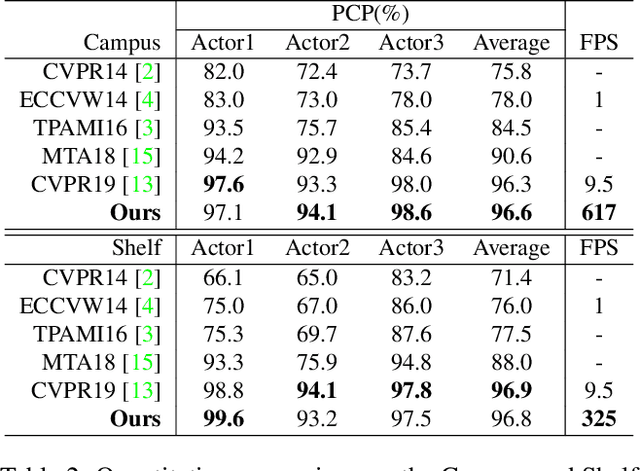
Estimating 3D poses of multiple humans in real-time is a classic but still challenging task in computer vision. Its major difficulty lies in the ambiguity in cross-view association of 2D poses and the huge state space when there are multiple people in multiple views. In this paper, we present a novel solution for multi-human 3D pose estimation from multiple calibrated camera views. It takes 2D poses in different camera coordinates as inputs and aims for the accurate 3D poses in the global coordinate. Unlike previous methods that associate 2D poses among all pairs of views from scratch at every frame, we exploit the temporal consistency in videos to match the 2D inputs with 3D poses directly in 3-space. More specifically, we propose to retain the 3D pose for each person and update them iteratively via the cross-view multi-human tracking. This novel formulation improves both accuracy and efficiency, as we demonstrated on widely-used public datasets. To further verify the scalability of our method, we propose a new large-scale multi-human dataset with 12 to 28 camera views. Without bells and whistles, our solution achieves 154 FPS on 12 cameras and 34 FPS on 28 cameras, indicating its ability to handle large-scale real-world applications. The proposed dataset will be released soon.
Disassembling the Dataset: A Camera Alignment Mechanism for Multiple Tasks in Person Re-identification
Jan 23, 2020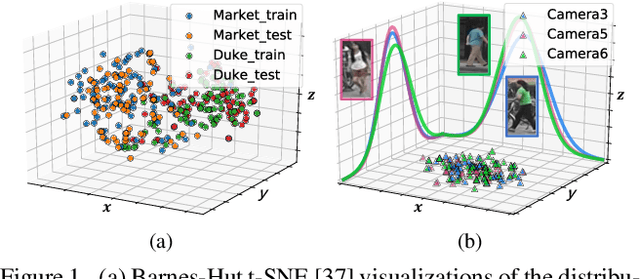
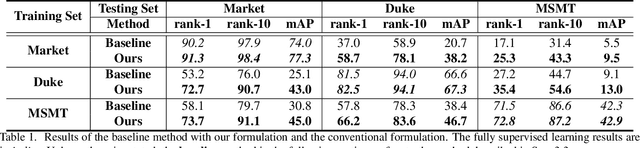
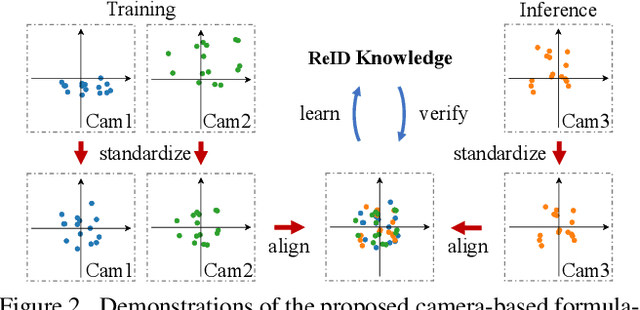
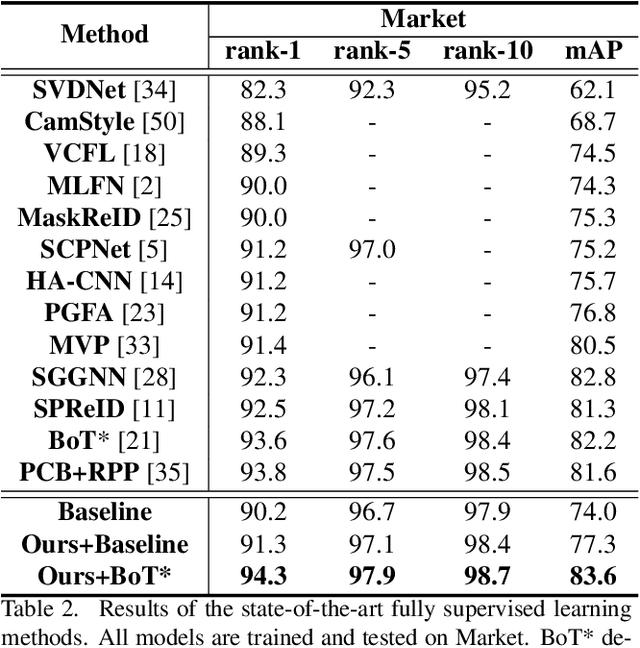
In person re-identification (ReID), one of the main challenges is the distribution inconsistency among different datasets. Previous researchers have defined several seemingly individual topics, such as fully supervised learning, direct transfer, domain adaptation, and incremental learning, each with different settings of training and testing scenarios. These topics are designed in a dataset-wise manner, i.e., images from the same dataset, even from disjoint cameras, are presumed to follow the same distribution. However, such distribution is coarse and training-set-specific, and the ReID knowledge learned in such manner works well only on the corresponding scenarios. To address this issue, we propose a fine-grained distribution alignment formulation, which disassembles the dataset and aligns all training and testing cameras. It connects all topics above and guarantees that ReID knowledge is always learned, accumulated, and verified in the aligned distributions. In practice, we devise the Camera-based Batch Normalization, which is easy for integration and nearly cost-free for existing ReID methods. Extensive experiments on the above four ReID tasks demonstrate the superiority of our approach. The code will be publicly available.
Learning Lightweight Pedestrian Detector with Hierarchical Knowledge Distillation
Sep 20, 2019
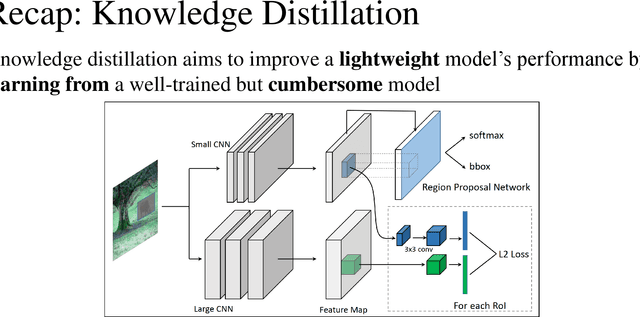
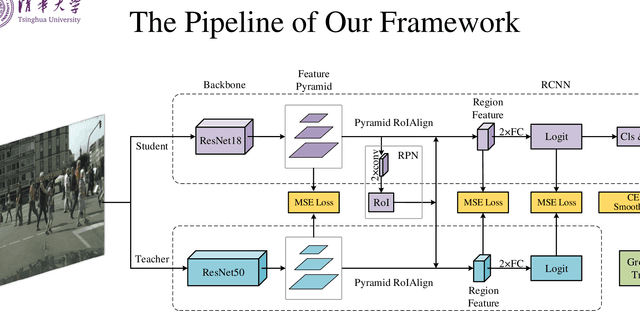
It remains very challenging to build a pedestrian detection system for real world applications, which demand for both accuracy and speed. This work presents a novel hierarchical knowledge distillation framework to learn a lightweight pedestrian detector, which significantly reduces the computational cost and still holds the high accuracy at the same time. Following the `teacher--student' diagram that a stronger, deeper neural network can teach a lightweight network to learn better representations, we explore multiple knowledge distillation architectures and reframe this approach as a unified, hierarchical distillation framework. In particular, the proposed distillation is performed at multiple hierarchies, multiple stages in a modern detector, which empowers the student detector to learn both low-level details and high-level abstractions simultaneously. Experiment result shows that a student model trained by our framework, with 6 times compression in number of parameters, still achieves competitive performance as the teacher model on the widely used pedestrian detection benchmark.
* Accepted at ICIP 2019 as Oral
Cross-Resolution Person Re-identification with Deep Antithetical Learning
Oct 24, 2018
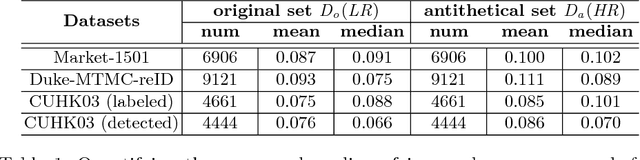
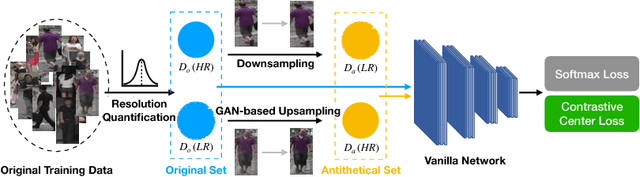
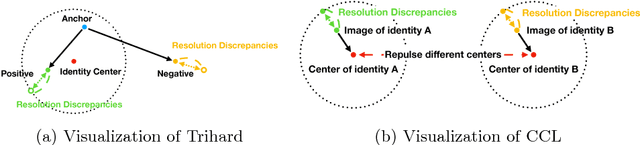
Images with different resolutions are ubiquitous in public person re-identification (ReID) datasets and real-world scenes, it is thus crucial for a person ReID model to handle the image resolution variations for improving its generalization ability. However, most existing person ReID methods pay little attention to this resolution discrepancy problem. One paradigm to deal with this problem is to use some complicated methods for mapping all images into an artificial image space, which however will disrupt the natural image distribution and requires heavy image preprocessing. In this paper, we analyze the deficiencies of several widely-used objective functions handling image resolution discrepancies and propose a new framework called deep antithetical learning that directly learns from the natural image space rather than creating an arbitrary one. We first quantify and categorize original training images according to their resolutions. Then we create an antithetical training set and make sure that original training images have counterparts with antithetical resolutions in this new set. At last, a novel Contrastive Center Loss(CCL) is proposed to learn from images with different resolutions without being interfered by their resolution discrepancies. Extensive experimental analyses and evaluations indicate that the proposed framework, even using a vanilla deep ReID network, exhibits remarkable performance improvements. Without bells and whistles, our approach outperforms previous state-of-the-art methods by a large margin.
Real-time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification
Sep 12, 2018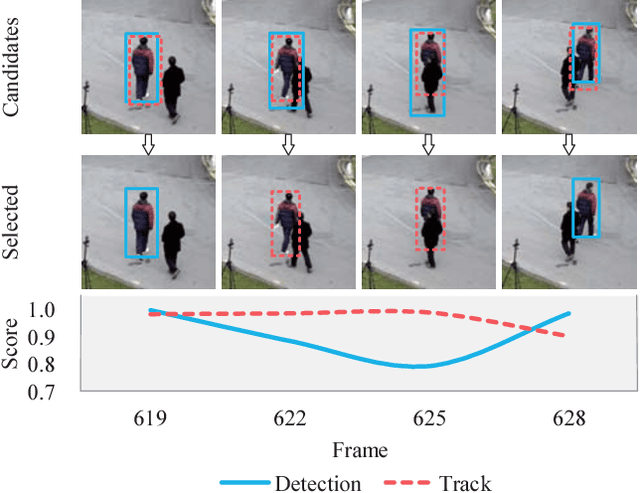
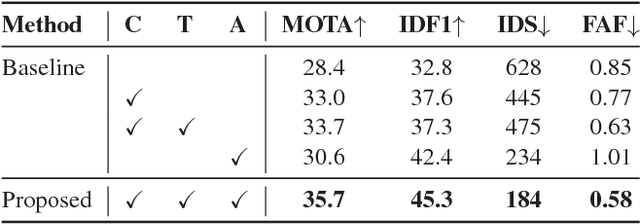
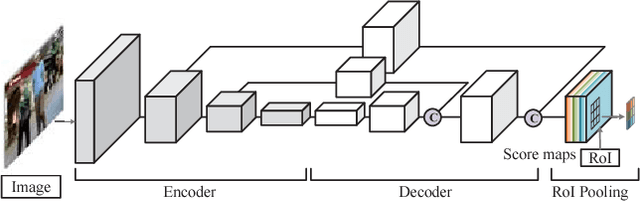
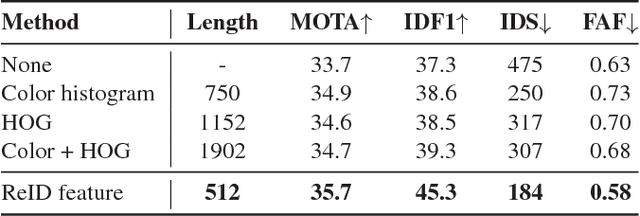
Online multi-object tracking is a fundamental problem in time-critical video analysis applications. A major challenge in the popular tracking-by-detection framework is how to associate unreliable detection results with existing tracks. In this paper, we propose to handle unreliable detection by collecting candidates from outputs of both detection and tracking. The intuition behind generating redundant candidates is that detection and tracks can complement each other in different scenarios. Detection results of high confidence prevent tracking drifts in the long term, and predictions of tracks can handle noisy detection caused by occlusion. In order to apply optimal selection from a considerable amount of candidates in real-time, we present a novel scoring function based on a fully convolutional neural network, that shares most computations on the entire image. Moreover, we adopt a deeply learned appearance representation, which is trained on large-scale person re-identification datasets, to improve the identification ability of our tracker. Extensive experiments show that our tracker achieves real-time and state-of-the-art performance on a widely used people tracking benchmark.