 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning via Co-Attentive Sharing for Pedestrian Attribute Recognition
Paper and Code
Apr 07, 2020
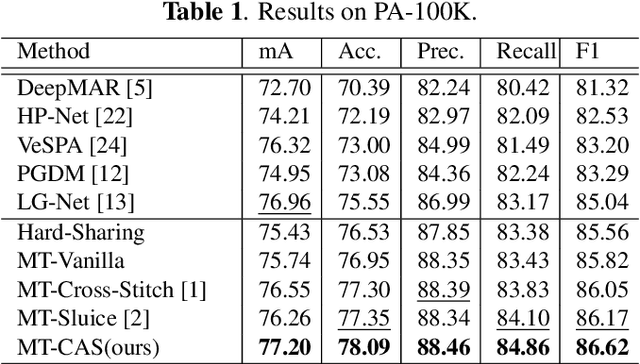
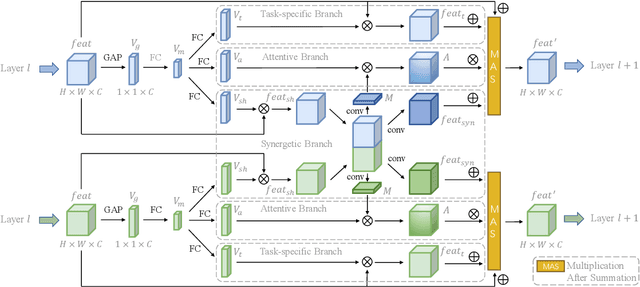
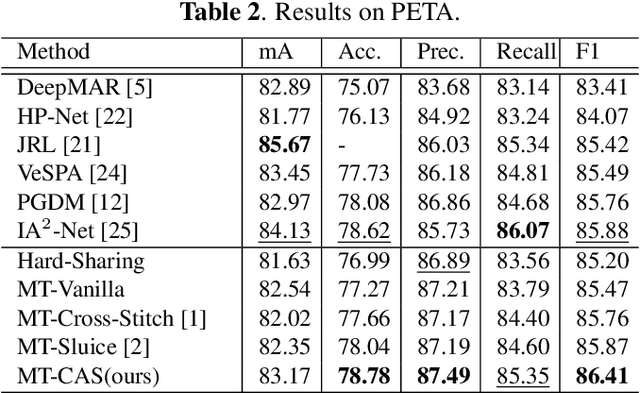
Learning to predict multiple attributes of a pedestrian is a multi-task learning problem. To share feature representation between two individual task networks, conventional methods like Cross-Stitch and Sluice network learn a linear combination of features or feature subspaces. However, linear combination rules out the complex interdependency between channels. Moreover, spatial information exchanging is less-considered. In this paper, we propose a novel Co-Attentive Sharing (CAS) module which extracts discriminative channels and spatial regions for more effective feature sharing in multi-task learning. The module consists of three branches, which leverage different channels for between-task feature fusing, attention generation and task-specific feature enhancing, respectively. Experiments on two pedestrian attribute recognition datasets show that our module outperforms the conventional sharing units and achieves superior results compared to the state-of-the-art approaches using many metrics.