 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Autoregressive Shape Generation via Octree-Based Adaptive Tokenization
Apr 03, 2025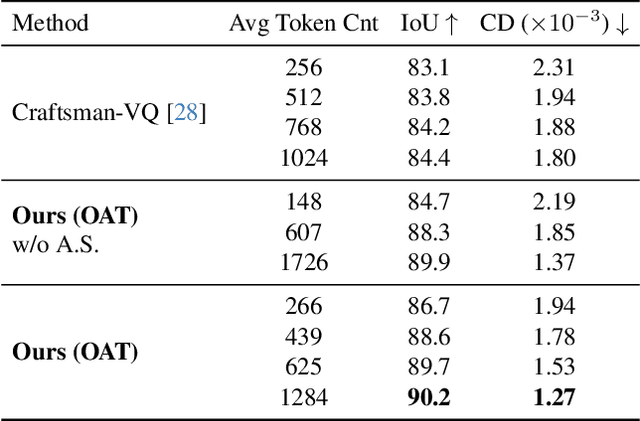

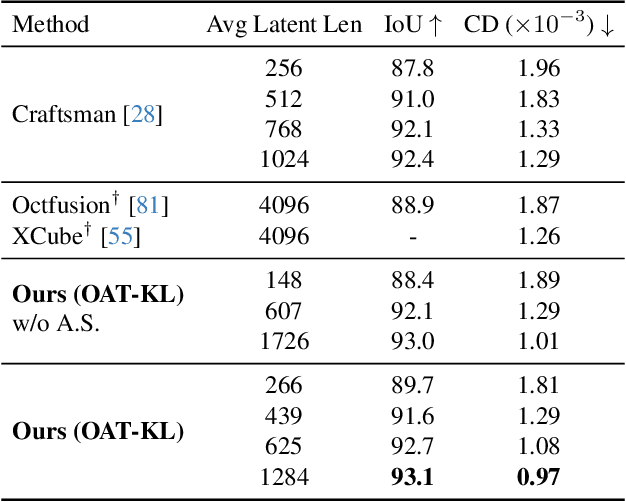
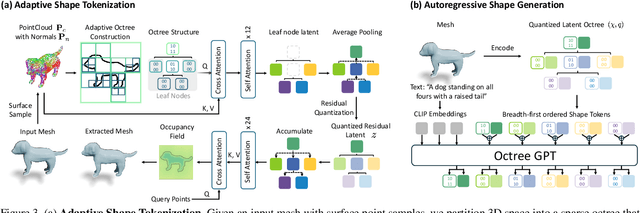
Many 3D generative models rely on variational autoencoders (VAEs) to learn compact shape representations. However, existing methods encode all shapes into a fixed-size token, disregarding the inherent variations in scale and complexity across 3D data. This leads to inefficient latent representations that can compromise downstream generation. We address this challenge by introducing Octree-based Adaptive Tokenization, a novel framework that adjusts the dimension of latent representations according to shape complexity. Our approach constructs an adaptive octree structure guided by a quadric-error-based subdivision criterion and allocates a shape latent vector to each octree cell using a query-based transformer. Building upon this tokenization, we develop an octree-based autoregressive generative model that effectively leverages these variable-sized representations in shape generation. Extensive experiments demonstrate that our approach reduces token counts by 50% compared to fixed-size methods while maintaining comparable visual quality. When using a similar token length, our method produces significantly higher-quality shapes. When incorporated with our downstream generative model, our method creates more detailed and diverse 3D content than existing approaches.
Learning Lightweight Pedestrian Detector with Hierarchical Knowledge Distillation
Sep 20, 2019
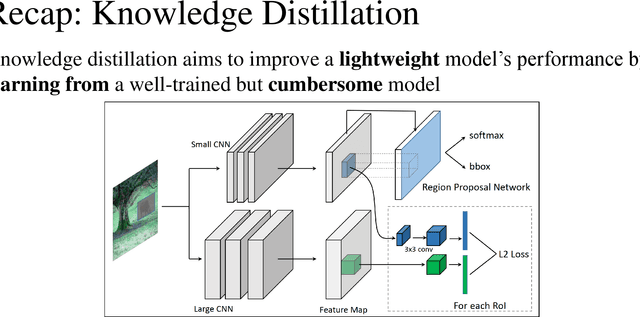
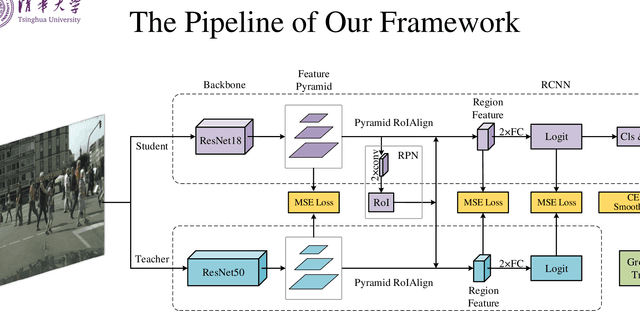
It remains very challenging to build a pedestrian detection system for real world applications, which demand for both accuracy and speed. This work presents a novel hierarchical knowledge distillation framework to learn a lightweight pedestrian detector, which significantly reduces the computational cost and still holds the high accuracy at the same time. Following the `teacher--student' diagram that a stronger, deeper neural network can teach a lightweight network to learn better representations, we explore multiple knowledge distillation architectures and reframe this approach as a unified, hierarchical distillation framework. In particular, the proposed distillation is performed at multiple hierarchies, multiple stages in a modern detector, which empowers the student detector to learn both low-level details and high-level abstractions simultaneously. Experiment result shows that a student model trained by our framework, with 6 times compression in number of parameters, still achieves competitive performance as the teacher model on the widely used pedestrian detection benchmark.
* Accepted at ICIP 2019 as Oral
Cross-Resolution Person Re-identification with Deep Antithetical Learning
Oct 24, 2018
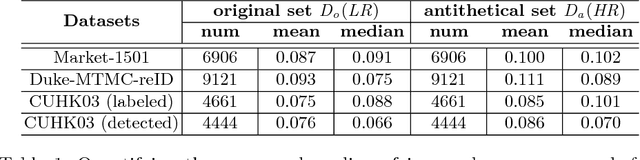
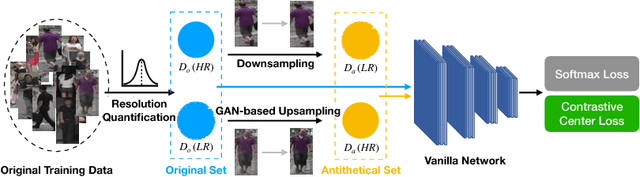
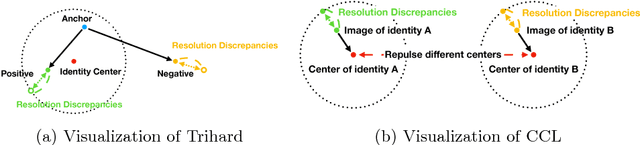
Images with different resolutions are ubiquitous in public person re-identification (ReID) datasets and real-world scenes, it is thus crucial for a person ReID model to handle the image resolution variations for improving its generalization ability. However, most existing person ReID methods pay little attention to this resolution discrepancy problem. One paradigm to deal with this problem is to use some complicated methods for mapping all images into an artificial image space, which however will disrupt the natural image distribution and requires heavy image preprocessing. In this paper, we analyze the deficiencies of several widely-used objective functions handling image resolution discrepancies and propose a new framework called deep antithetical learning that directly learns from the natural image space rather than creating an arbitrary one. We first quantify and categorize original training images according to their resolutions. Then we create an antithetical training set and make sure that original training images have counterparts with antithetical resolutions in this new set. At last, a novel Contrastive Center Loss(CCL) is proposed to learn from images with different resolutions without being interfered by their resolution discrepancies. Extensive experimental analyses and evaluations indicate that the proposed framework, even using a vanilla deep ReID network, exhibits remarkable performance improvements. Without bells and whistles, our approach outperforms previous state-of-the-art methods by a large margin.
Real-time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification
Sep 12, 2018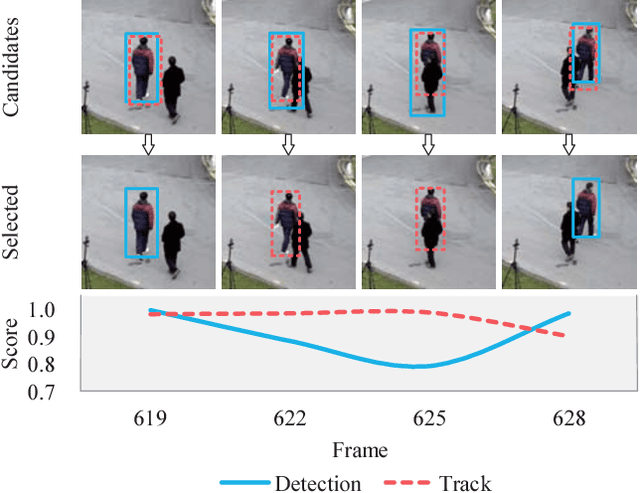
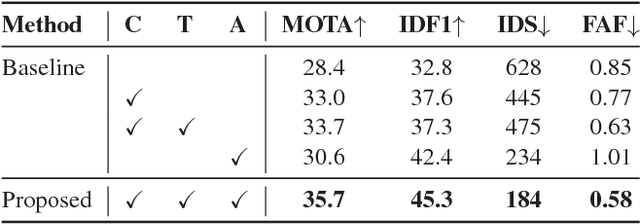
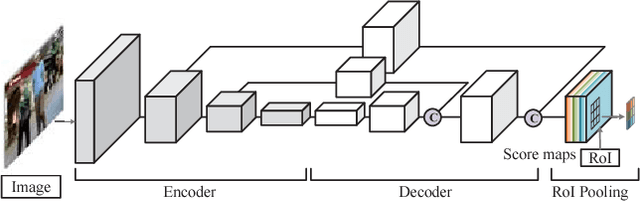
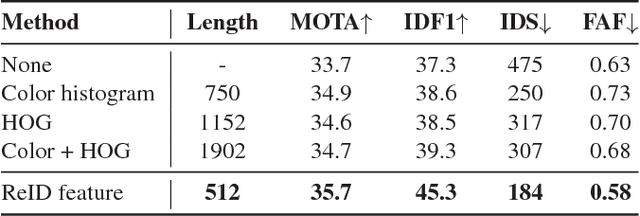
Online multi-object tracking is a fundamental problem in time-critical video analysis applications. A major challenge in the popular tracking-by-detection framework is how to associate unreliable detection results with existing tracks. In this paper, we propose to handle unreliable detection by collecting candidates from outputs of both detection and tracking. The intuition behind generating redundant candidates is that detection and tracks can complement each other in different scenarios. Detection results of high confidence prevent tracking drifts in the long term, and predictions of tracks can handle noisy detection caused by occlusion. In order to apply optimal selection from a considerable amount of candidates in real-time, we present a novel scoring function based on a fully convolutional neural network, that shares most computations on the entire image. Moreover, we adopt a deeply learned appearance representation, which is trained on large-scale person re-identification datasets, to improve the identification ability of our tracker. Extensive experiments show that our tracker achieves real-time and state-of-the-art performance on a widely used people tracking benchmark.