 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-to-Product: Generative Assembly via Bimanual Manipulation
Aug 28, 2025

Creating assembly products demands significant manual effort and expert knowledge in 1) designing the assembly and 2) constructing the product. This paper introduces Prompt-to-Product, an automated pipeline that generates real-world assembly products from natural language prompts. Specifically, we leverage LEGO bricks as the assembly platform and automate the process of creating brick assembly structures. Given the user design requirements, Prompt-to-Product generates physically buildable brick designs, and then leverages a bimanual robotic system to construct the real assembly products, bringing user imaginations into the real world. We conduct a comprehensive user study, and the results demonstrate that Prompt-to-Product significantly lowers the barrier and reduces manual effort in creating assembly products from imaginative ideas.
Generating Physically Stable and Buildable LEGO Designs from Text
May 08, 2025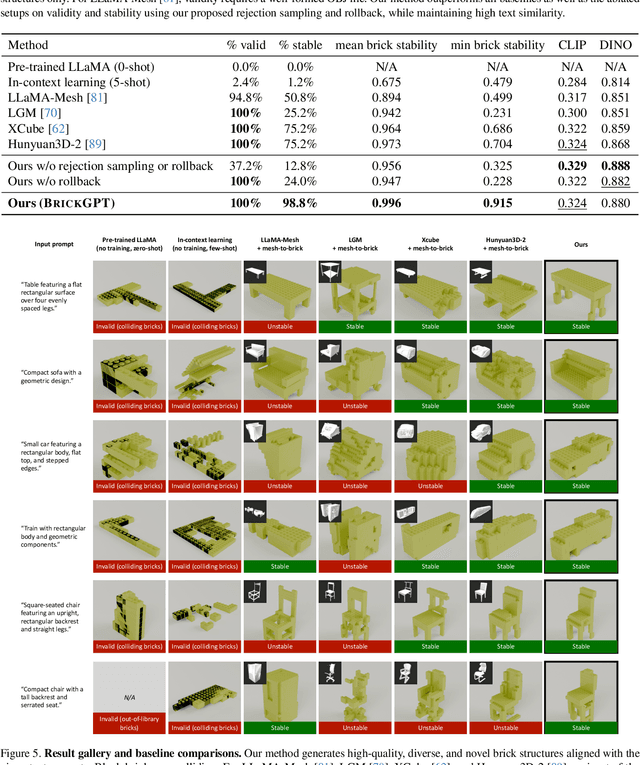
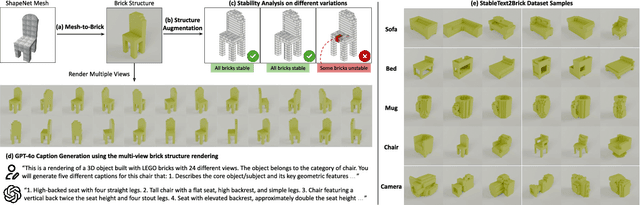
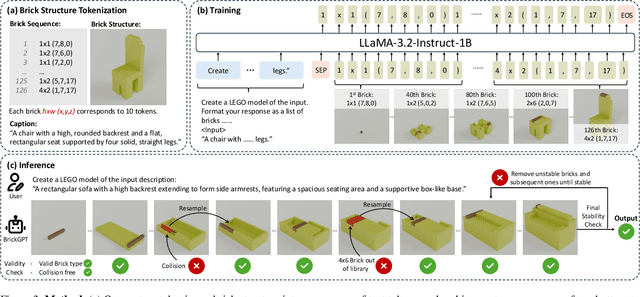
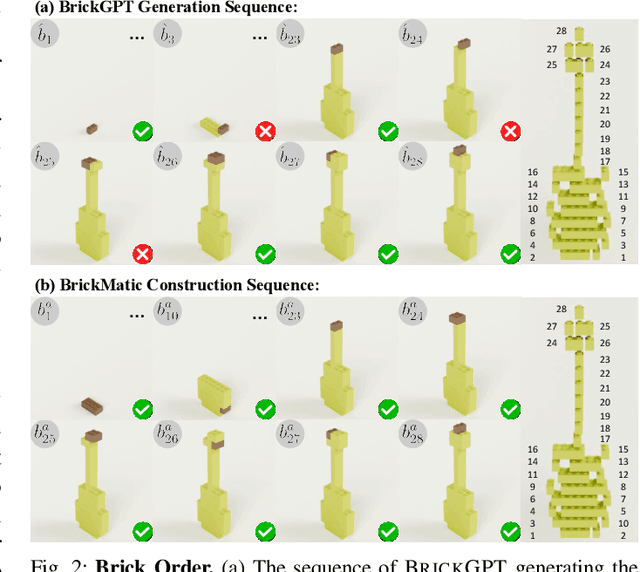
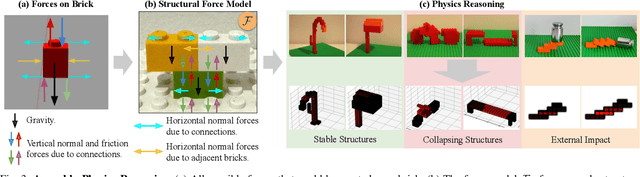
We introduce LegoGPT, the first approach for generating physically stable LEGO brick models from text prompts. To achieve this, we construct a large-scale, physically stable dataset of LEGO designs, along with their associated captions, and train an autoregressive large language model to predict the next brick to add via next-token prediction. To improve the stability of the resulting designs, we employ an efficient validity check and physics-aware rollback during autoregressive inference, which prunes infeasible token predictions using physics laws and assembly constraints. Our experiments show that LegoGPT produces stable, diverse, and aesthetically pleasing LEGO designs that align closely with the input text prompts. We also develop a text-based LEGO texturing method to generate colored and textured designs. We show that our designs can be assembled manually by humans and automatically by robotic arms. We also release our new dataset, StableText2Lego, containing over 47,000 LEGO structures of over 28,000 unique 3D objects accompanied by detailed captions, along with our code and models at the project website: https://avalovelace1.github.io/LegoGPT/.
Efficient Autoregressive Shape Generation via Octree-Based Adaptive Tokenization
Apr 03, 2025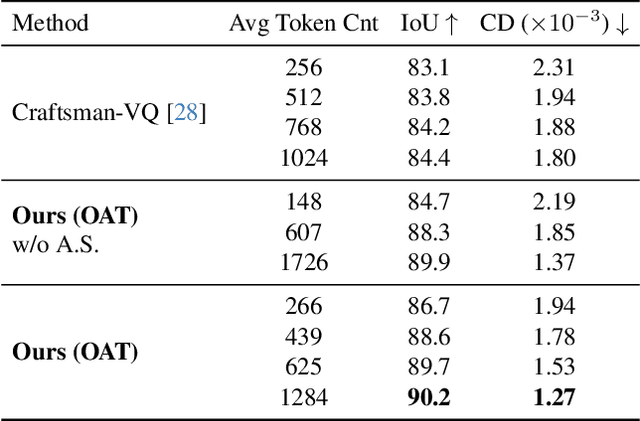

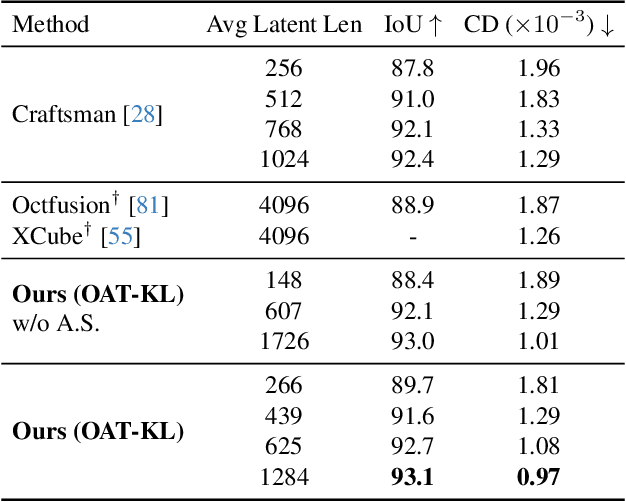
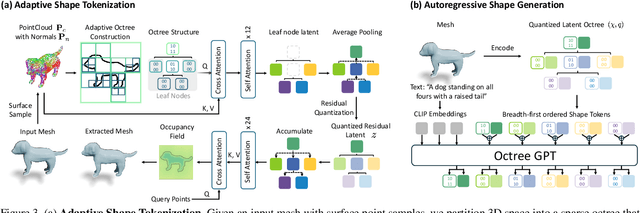
Many 3D generative models rely on variational autoencoders (VAEs) to learn compact shape representations. However, existing methods encode all shapes into a fixed-size token, disregarding the inherent variations in scale and complexity across 3D data. This leads to inefficient latent representations that can compromise downstream generation. We address this challenge by introducing Octree-based Adaptive Tokenization, a novel framework that adjusts the dimension of latent representations according to shape complexity. Our approach constructs an adaptive octree structure guided by a quadric-error-based subdivision criterion and allocates a shape latent vector to each octree cell using a query-based transformer. Building upon this tokenization, we develop an octree-based autoregressive generative model that effectively leverages these variable-sized representations in shape generation. Extensive experiments demonstrate that our approach reduces token counts by 50% compared to fixed-size methods while maintaining comparable visual quality. When using a similar token length, our method produces significantly higher-quality shapes. When incorporated with our downstream generative model, our method creates more detailed and diverse 3D content than existing approaches.
Cube: A Roblox View of 3D Intelligence
Mar 19, 2025



Foundation models trained on vast amounts of data have demonstrated remarkable reasoning and generation capabilities in the domains of text, images, audio and video. Our goal at Roblox is to build such a foundation model for 3D intelligence, a model that can support developers in producing all aspects of a Roblox experience, from generating 3D objects and scenes to rigging characters for animation to producing programmatic scripts describing object behaviors. We discuss three key design requirements for such a 3D foundation model and then present our first step towards building such a model. We expect that 3D geometric shapes will be a core data type and describe our solution for 3D shape tokenizer. We show how our tokenization scheme can be used in applications for text-to-shape generation, shape-to-text generation and text-to-scene generation. We demonstrate how these applications can collaborate with existing large language models (LLMs) to perform scene analysis and reasoning. We conclude with a discussion outlining our path to building a fully unified foundation model for 3D intelligence.
Tactile DreamFusion: Exploiting Tactile Sensing for 3D Generation
Dec 09, 2024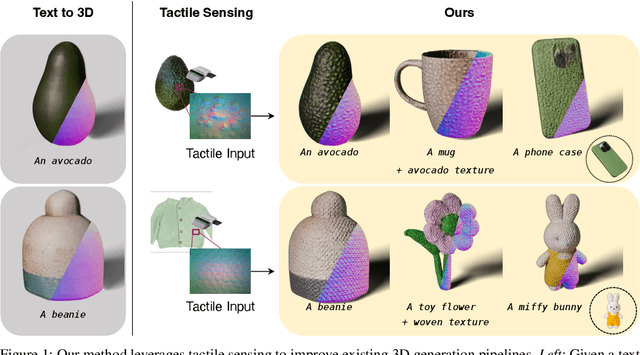
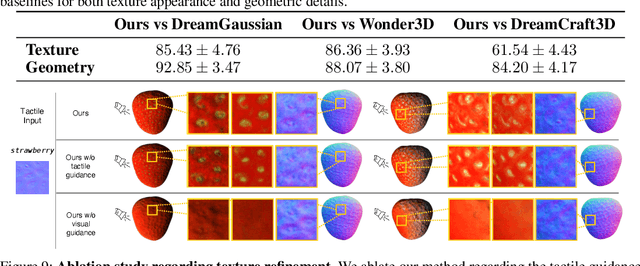
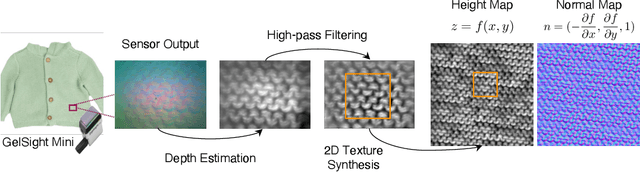

3D generation methods have shown visually compelling results powered by diffusion image priors. However, they often fail to produce realistic geometric details, resulting in overly smooth surfaces or geometric details inaccurately baked in albedo maps. To address this, we introduce a new method that incorporates touch as an additional modality to improve the geometric details of generated 3D assets. We design a lightweight 3D texture field to synthesize visual and tactile textures, guided by 2D diffusion model priors on both visual and tactile domains. We condition the visual texture generation on high-resolution tactile normals and guide the patch-based tactile texture refinement with a customized TextureDreambooth. We further present a multi-part generation pipeline that enables us to synthesize different textures across various regions. To our knowledge, we are the first to leverage high-resolution tactile sensing to enhance geometric details for 3D generation tasks. We evaluate our method in both text-to-3D and image-to-3D settings. Our experiments demonstrate that our method provides customized and realistic fine geometric textures while maintaining accurate alignment between two modalities of vision and touch.
FlashTex: Fast Relightable Mesh Texturing with LightControlNet
Feb 20, 2024



Manually creating textures for 3D meshes is time-consuming, even for expert visual content creators. We propose a fast approach for automatically texturing an input 3D mesh based on a user-provided text prompt. Importantly, our approach disentangles lighting from surface material/reflectance in the resulting texture so that the mesh can be properly relit and rendered in any lighting environment. We introduce LightControlNet, a new text-to-image model based on the ControlNet architecture, which allows the specification of the desired lighting as a conditioning image to the model. Our text-to-texture pipeline then constructs the texture in two stages. The first stage produces a sparse set of visually consistent reference views of the mesh using LightControlNet. The second stage applies a texture optimization based on Score Distillation Sampling (SDS) that works with LightControlNet to increase the texture quality while disentangling surface material from lighting. Our pipeline is significantly faster than previous text-to-texture methods, while producing high-quality and relightable textures.
StableLego: Stability Analysis of Block Stacking Assembly
Feb 16, 2024



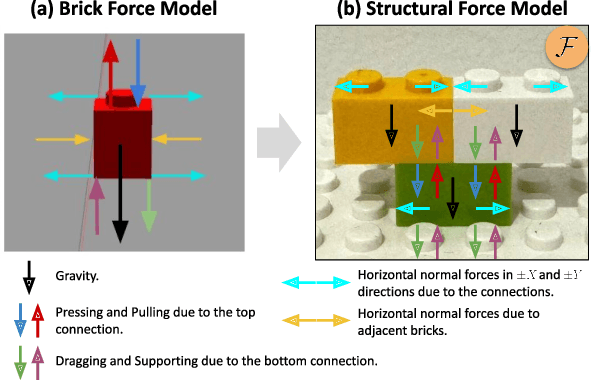
Recent advancements in robotics enable robots to accomplish complex assembly tasks. However, designing an assembly requires a non-trivial effort since a slight variation in the design could significantly affect the task feasibility. It is critical to ensure the physical feasibility of the assembly design so that the assembly task can be successfully executed. To address the challenge, this paper studies the physical stability of assembly structures, in particular, block stacking assembly, where people use cubic blocks to build 3D structures (e.g., Lego constructions). The paper proposes a new optimization formulation, which optimizes over force balancing equations, for inferring the structural stability of 3D block-stacking structures. The proposed stability analysis is tested and verified on hand-crafted Lego examples. The experiment results demonstrate that the proposed stability analysis can correctly predict whether the structure is stable. In addition, it outperforms the existing methods since it can locate the weakest parts in the design, and more importantly, solve any given assembly structure. To further validate the proposed analysis formulation, we provide StableLego: a comprehensive dataset including more than 50k 3D objects with their Lego layouts. We test the proposed stability analysis and include the stability inference for each corresponding object in StableLego. Our code and the dataset are available at https://github.com/intelligent-control-lab/StableLego.
Total-Recon: Deformable Scene Reconstruction for Embodied View Synthesis
Apr 24, 2023We explore the task of embodied view synthesis from monocular videos of deformable scenes. Given a minute-long RGBD video of people interacting with their pets, we render the scene from novel camera trajectories derived from in-scene motion of actors: (1) egocentric cameras that simulate the point of view of a target actor and (2) 3rd-person cameras that follow the actor. Building such a system requires reconstructing the root-body and articulated motion of each actor in the scene, as well as a scene representation that supports free-viewpoint synthesis. Longer videos are more likely to capture the scene from diverse viewpoints (which helps reconstruction) but are also more likely to contain larger motions (which complicates reconstruction). To address these challenges, we present Total-Recon, the first method to photorealistically reconstruct deformable scenes from long monocular RGBD videos. Crucially, to scale to long videos, our method hierarchically decomposes the scene motion into the motion of each object, which itself is decomposed into global root-body motion and local articulations. To quantify such "in-the-wild" reconstruction and view synthesis, we collect ground-truth data from a specialized stereo RGBD capture rig for 11 challenging videos, significantly outperforming prior art. Code, videos, and data can be found at https://andrewsonga.github.io/totalrecon .
3D-aware Conditional Image Synthesis
Feb 16, 2023



We propose pix2pix3D, a 3D-aware conditional generative model for controllable photorealistic image synthesis. Given a 2D label map, such as a segmentation or edge map, our model learns to synthesize a corresponding image from different viewpoints. To enable explicit 3D user control, we extend conditional generative models with neural radiance fields. Given widely-available monocular images and label map pairs, our model learns to assign a label to every 3D point in addition to color and density, which enables it to render the image and pixel-aligned label map simultaneously. Finally, we build an interactive system that allows users to edit the label map from any viewpoint and generate outputs accordingly.
Depth-supervised NeRF: Fewer Views and Faster Training for Free
Jul 06, 2021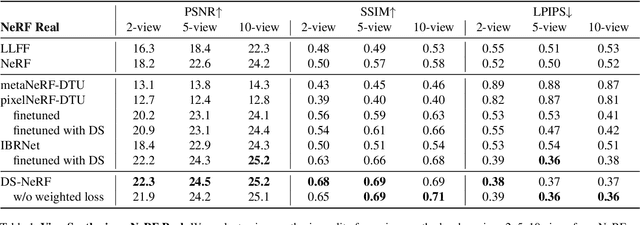
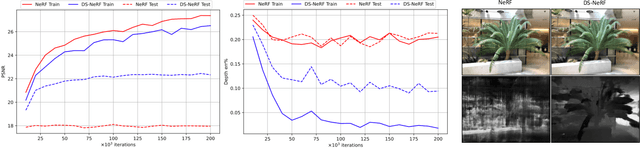
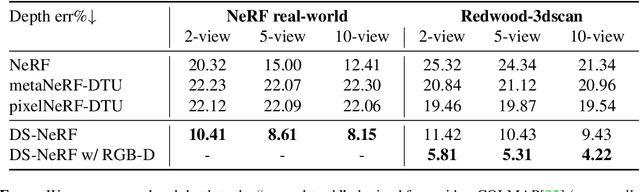
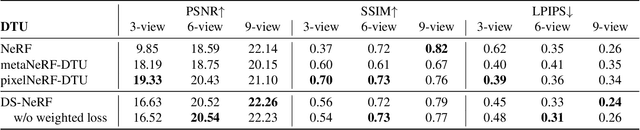
One common failure mode of Neural Radiance Field (NeRF) models is fitting incorrect geometries when given an insufficient number of input views. We propose DS-NeRF (Depth-supervised Neural Radiance Fields), a loss for learning neural radiance fields that takes advantage of readily-available depth supervision. Our key insight is that sparse depth supervision can be used to regularize the learned geometry, a crucial component for effectively rendering novel views using NeRF. We exploit the fact that current NeRF pipelines require images with known camera poses that are typically estimated by running structure-from-motion (SFM). Crucially, SFM also produces sparse 3D points that can be used as ``free" depth supervision during training: we simply add a loss to ensure that depth rendered along rays that intersect these 3D points is close to the observed depth. We find that DS-NeRF can render more accurate images given fewer training views while training 2-6x faster. With only two training views on real-world images, DS-NeRF significantly outperforms NeRF as well as other sparse-view variants. We show that our loss is compatible with these NeRF models, demonstrating that depth is a cheap and easily digestible supervisory signal. Finally, we show that DS-NeRF supports other types of depth supervision such as scanned depth sensors and RGBD reconstruction outputs.