 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-to-Product: Generative Assembly via Bimanual Manipulation
Aug 28, 2025

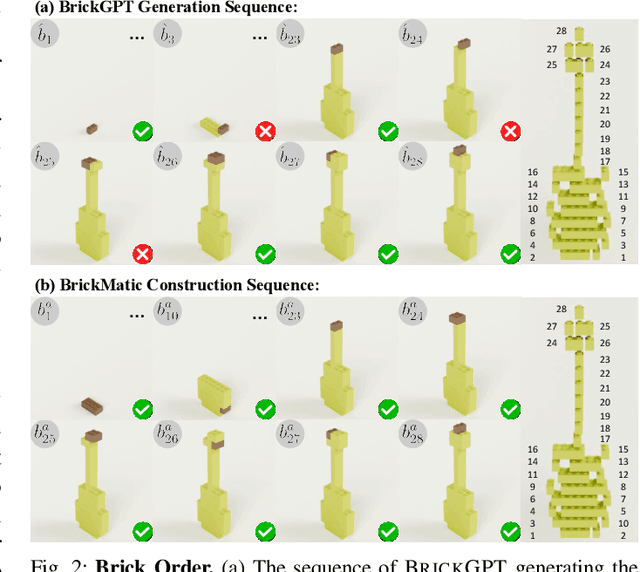
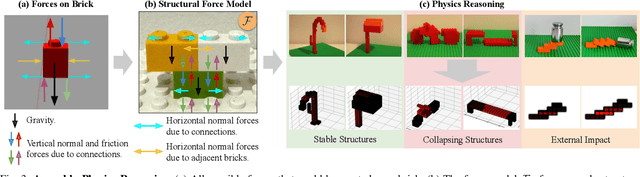
Creating assembly products demands significant manual effort and expert knowledge in 1) designing the assembly and 2) constructing the product. This paper introduces Prompt-to-Product, an automated pipeline that generates real-world assembly products from natural language prompts. Specifically, we leverage LEGO bricks as the assembly platform and automate the process of creating brick assembly structures. Given the user design requirements, Prompt-to-Product generates physically buildable brick designs, and then leverages a bimanual robotic system to construct the real assembly products, bringing user imaginations into the real world. We conduct a comprehensive user study, and the results demonstrate that Prompt-to-Product significantly lowers the barrier and reduces manual effort in creating assembly products from imaginative ideas.
Modeling Probabilistic Reduction using Information Theory and Naive Discriminative Learning
Jun 11, 2025This study compares probabilistic predictors based on information theory with Naive Discriminative Learning (NDL) predictors in modeling acoustic word duration, focusing on probabilistic reduction. We examine three models using the Buckeye corpus: one with NDL-derived predictors using information-theoretic formulas, one with traditional NDL predictors, and one with N-gram probabilistic predictors. Results show that the N-gram model outperforms both NDL models, challenging the assumption that NDL is more effective due to its cognitive motivation. However, incorporating information-theoretic formulas into NDL improves model performance over the traditional model. This research highlights a) the need to incorporate not only frequency and contextual predictability but also average contextual predictability, and b) the importance of combining information-theoretic metrics of predictability and information derived from discriminative learning in modeling acoustic reduction.
Automatic Speech Recognition of African American English: Lexical and Contextual Effects
Jun 07, 2025Automatic Speech Recognition (ASR) models often struggle with the phonetic, phonological, and morphosyntactic features found in African American English (AAE). This study focuses on two key AAE variables: Consonant Cluster Reduction (CCR) and ING-reduction. It examines whether the presence of CCR and ING-reduction increases ASR misrecognition. Subsequently, it investigates whether end-to-end ASR systems without an external Language Model (LM) are more influenced by lexical neighborhood effect and less by contextual predictability compared to systems with an LM. The Corpus of Regional African American Language (CORAAL) was transcribed using wav2vec 2.0 with and without an LM. CCR and ING-reduction were detected using the Montreal Forced Aligner (MFA) with pronunciation expansion. The analysis reveals a small but significant effect of CCR and ING on Word Error Rate (WER) and indicates a stronger presence of lexical neighborhood effect in ASR systems without LMs.
Connecting the Persian-speaking World through Transliteration
Feb 27, 2025Despite speaking mutually intelligible varieties of the same language, speakers of Tajik Persian, written in a modified Cyrillic alphabet, cannot read Iranian and Afghan texts written in the Perso-Arabic script. As the vast majority of Persian text on the Internet is written in Perso-Arabic, monolingual Tajik speakers are unable to interface with the Internet in any meaningful way. Due to overwhelming similarity between the formal registers of these dialects and the scarcity of Tajik-Farsi parallel data, machine transliteration has been proposed as more a practical and appropriate solution than machine translation. This paper presents a transformer-based G2P approach to Tajik-Farsi transliteration, achieving chrF++ scores of 58.70 (Farsi to Tajik) and 74.20 (Tajik to Farsi) on novel digraphic datasets, setting a comparable baseline metric for future work. Our results also demonstrate the non-trivial difficulty of this task in both directions. We also provide an overview of the differences between the two scripts and the challenges they present, so as to aid future efforts in Tajik-Farsi transliteration.
Playing with Voices: Tabletop Role-Playing Game Recordings as a Diarization Challenge
Feb 18, 2025This paper provides a proof of concept that audio of tabletop role-playing games (TTRPG) could serve as a challenge for diarization systems. TTRPGs are carried out mostly by conversation. Participants often alter their voices to indicate that they are talking as a fictional character. Audio processing systems are susceptible to voice conversion with or without technological assistance. TTRPG present a conversational phenomenon in which voice conversion is an inherent characteristic for an immersive gaming experience. This could make it more challenging for diarizers to pick the real speaker and determine that impersonating is just that. We present the creation of a small TTRPG audio dataset and compare it against the AMI and the ICSI corpus. The performance of two diarizers, pyannote.audio and wespeaker, were evaluated. We observed that TTRPGs' properties result in a higher confusion rate for both diarizers. Additionally, wespeaker strongly underestimates the number of speakers in the TTRPG audio files. We propose TTRPG audio as a promising challenge for diarization systems.
Analysis of LLM as a grammatical feature tagger for African American English
Feb 09, 2025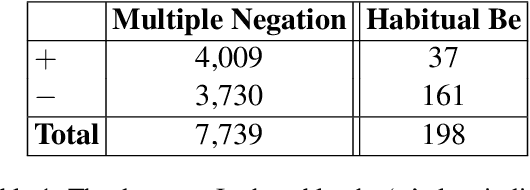
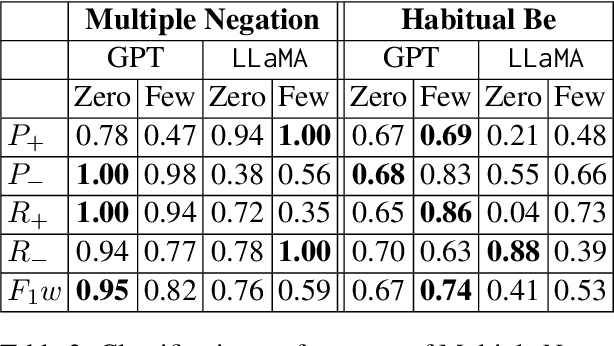
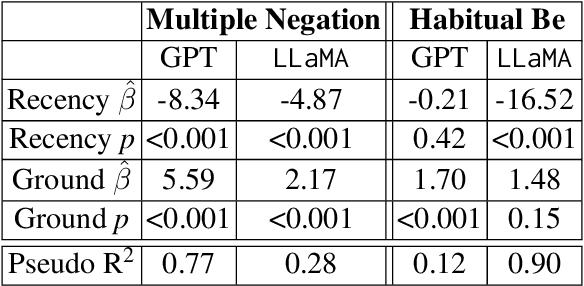
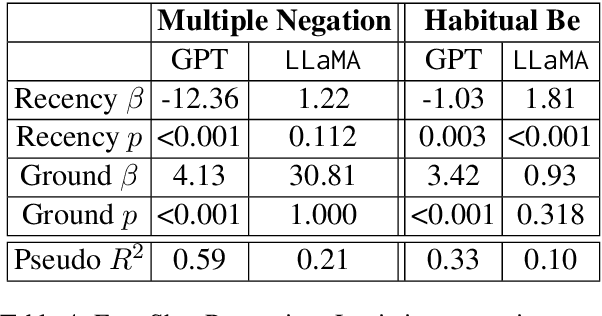
African American English (AAE) presents unique challenges in natural language processing (NLP). This research systematically compares the performance of available NLP models--rule-based, transformer-based, and large language models (LLMs)--capable of identifying key grammatical features of AAE, namely Habitual Be and Multiple Negation. These features were selected for their distinct grammatical complexity and frequency of occurrence. The evaluation involved sentence-level binary classification tasks, using both zero-shot and few-shot strategies. The analysis reveals that while LLMs show promise compared to the baseline, they are influenced by biases such as recency and unrelated features in the text such as formality. This study highlights the necessity for improved model training and architectural adjustments to better accommodate AAE's unique linguistic characteristics. Data and code are available.
Frequency matters: Modeling irregular morphological patterns in Spanish with Transformers
Oct 28, 2024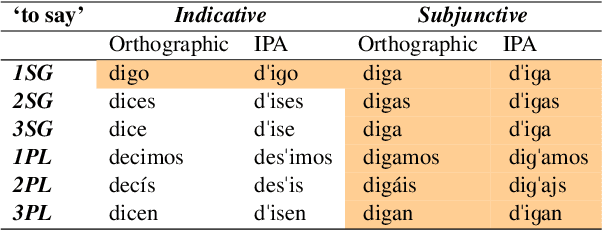
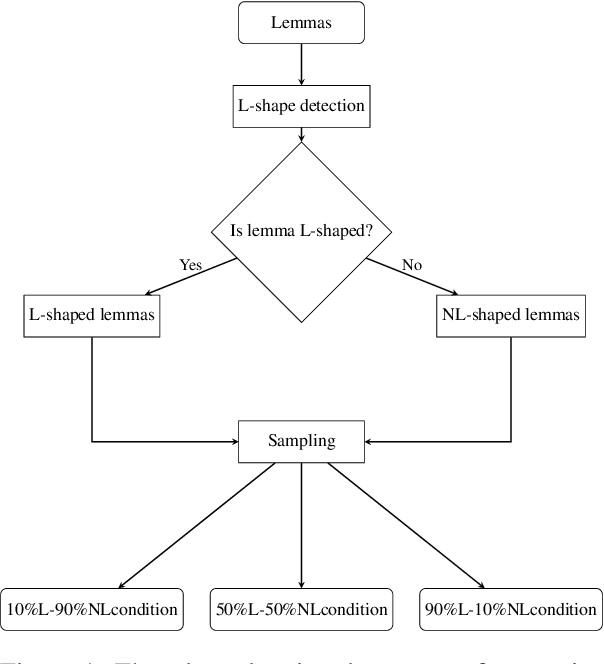
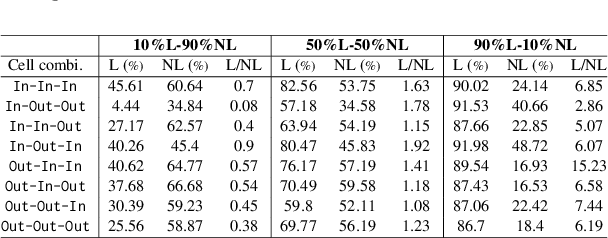
The present paper evaluates the learning behaviour of a transformer-based neural network with regard to an irregular inflectional paradigm. We apply the paradigm cell filling problem to irregular patterns. We approach this problem using the morphological reinflection task and model it as a character sequence-to-sequence learning problem. The test case under investigation are irregular verbs in Spanish. Besides many regular verbs in Spanish L-shaped verbs the first person singular indicative stem irregularly matches the subjunctive paradigm, while other indicative forms remain unaltered. We examine the role of frequency during learning and compare models under differing input frequency conditions. We train the model on a corpus of Spanish with a realistic distribution of regular and irregular verbs to compare it with models trained on input with augmented distributions of (ir)regular words. We explore how the neural models learn this L-shaped pattern using post-hoc analyses. Our experiments show that, across frequency conditions, the models are surprisingly capable of learning the irregular pattern. Furthermore, our post-hoc analyses reveal the possible sources of errors. All code and data are available at \url{https://anonymous.4open.science/r/modeling_spanish_acl-7567/} under MIT license.
GreedLlama: Performance of Financial Value-Aligned Large Language Models in Moral Reasoning
Apr 03, 2024This paper investigates the ethical implications of aligning Large Language Models (LLMs) with financial optimization, through the case study of GreedLlama, a model fine-tuned to prioritize economically beneficial outcomes. By comparing GreedLlama's performance in moral reasoning tasks to a base Llama2 model, our results highlight a concerning trend: GreedLlama demonstrates a marked preference for profit over ethical considerations, making morally appropriate decisions at significantly lower rates than the base model in scenarios of both low and high moral ambiguity. In low ambiguity situations, GreedLlama's ethical decisions decreased to 54.4%, compared to the base model's 86.9%, while in high ambiguity contexts, the rate was 47.4% against the base model's 65.1%. These findings emphasize the risks of single-dimensional value alignment in LLMs, underscoring the need for integrating broader ethical values into AI development to ensure decisions are not solely driven by financial incentives. The study calls for a balanced approach to LLM deployment, advocating for the incorporation of ethical considerations in models intended for business applications, particularly in light of the absence of regulatory oversight.
VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence
Dec 05, 2023



Current diffusion-based video editing primarily focuses on structure-preserved editing by utilizing various dense correspondences to ensure temporal consistency and motion alignment. However, these approaches are often ineffective when the target edit involves a shape change. To embark on video editing with shape change, we explore customized video subject swapping in this work, where we aim to replace the main subject in a source video with a target subject having a distinct identity and potentially different shape. In contrast to previous methods that rely on dense correspondences, we introduce the VideoSwap framework that exploits semantic point correspondences, inspired by our observation that only a small number of semantic points are necessary to align the subject's motion trajectory and modify its shape. We also introduce various user-point interactions (\eg, removing points and dragging points) to address various semantic point correspondence. Extensive experiments demonstrate state-of-the-art video subject swapping results across a variety of real-world videos.
Disambiguation of morpho-syntactic features of African American English -- the case of habitual be
Apr 26, 2022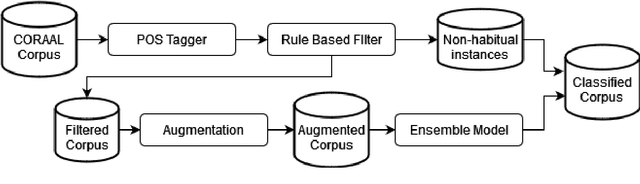
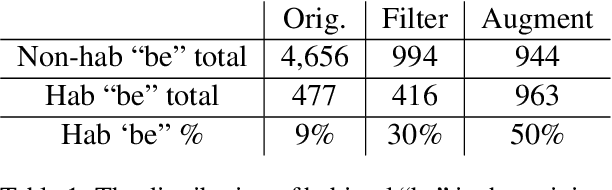
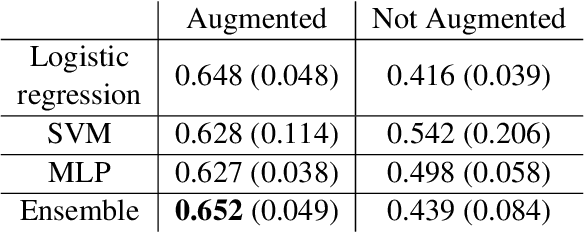
Recent research has highlighted that natural language processing (NLP) systems exhibit a bias against African American speakers. The bias errors are often caused by poor representation of linguistic features unique to African American English (AAE), due to the relatively low probability of occurrence of many such features in training data. We present a workflow to overcome such bias in the case of habitual "be". Habitual "be" is isomorphic, and therefore ambiguous, with other forms of "be" found in both AAE and other varieties of English. This creates a clear challenge for bias in NLP technologies. To overcome the scarcity, we employ a combination of rule-based filters and data augmentation that generate a corpus balanced between habitual and non-habitual instances. With this balanced corpus, we train unbiased machine learning classifiers, as demonstrated on a corpus of AAE transcribed texts, achieving .65 F$_1$ score disambiguating habitual "be".