 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of LLM as a grammatical feature tagger for African American English
Feb 09, 2025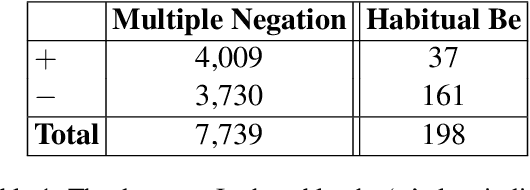
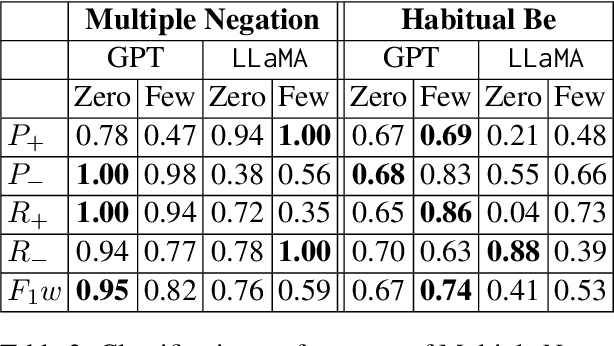
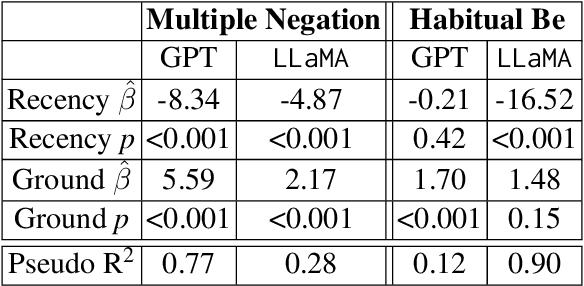
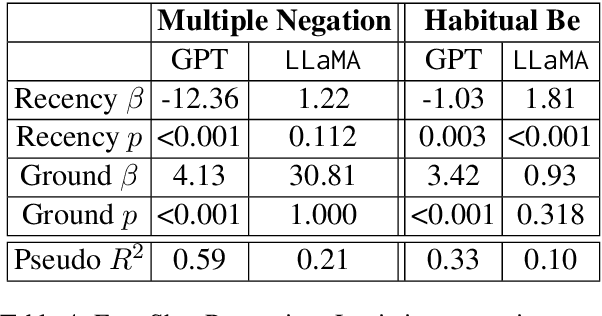
African American English (AAE) presents unique challenges in natural language processing (NLP). This research systematically compares the performance of available NLP models--rule-based, transformer-based, and large language models (LLMs)--capable of identifying key grammatical features of AAE, namely Habitual Be and Multiple Negation. These features were selected for their distinct grammatical complexity and frequency of occurrence. The evaluation involved sentence-level binary classification tasks, using both zero-shot and few-shot strategies. The analysis reveals that while LLMs show promise compared to the baseline, they are influenced by biases such as recency and unrelated features in the text such as formality. This study highlights the necessity for improved model training and architectural adjustments to better accommodate AAE's unique linguistic characteristics. Data and code are available.
Disambiguation of morpho-syntactic features of African American English -- the case of habitual be
Apr 26, 2022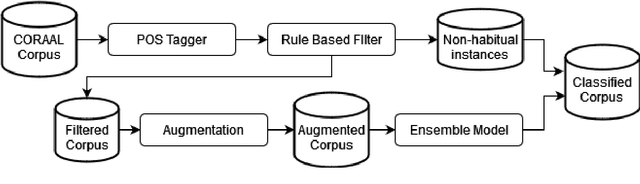
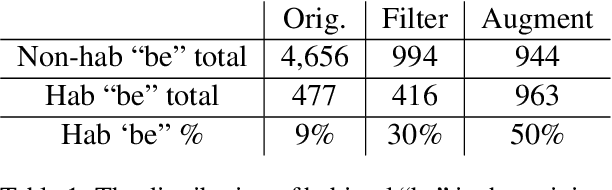
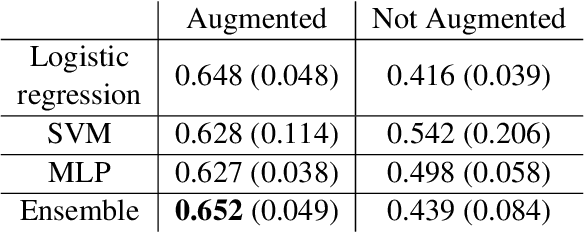
Recent research has highlighted that natural language processing (NLP) systems exhibit a bias against African American speakers. The bias errors are often caused by poor representation of linguistic features unique to African American English (AAE), due to the relatively low probability of occurrence of many such features in training data. We present a workflow to overcome such bias in the case of habitual "be". Habitual "be" is isomorphic, and therefore ambiguous, with other forms of "be" found in both AAE and other varieties of English. This creates a clear challenge for bias in NLP technologies. To overcome the scarcity, we employ a combination of rule-based filters and data augmentation that generate a corpus balanced between habitual and non-habitual instances. With this balanced corpus, we train unbiased machine learning classifiers, as demonstrated on a corpus of AAE transcribed texts, achieving .65 F$_1$ score disambiguating habitual "be".
A Summary of the First Workshop on Language Technology for Language Documentation and Revitalization
Apr 27, 2020


Despite recent advances in natural language processing and other language technology, the application of such technology to language documentation and conservation has been limited. In August 2019, a workshop was held at Carnegie Mellon University in Pittsburgh to attempt to bring together language community members, documentary linguists, and technologists to discuss how to bridge this gap and create prototypes of novel and practical language revitalization technologies. This paper reports the results of this workshop, including issues discussed, and various conceived and implemented technologies for nine languages: Arapaho, Cayuga, Inuktitut, Irish Gaelic, Kidaw'ida, Kwak'wala, Ojibwe, San Juan Quiahije Chatino, and Seneca.