 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Summary of the First Workshop on Language Technology for Language Documentation and Revitalization
Apr 27, 2020


Despite recent advances in natural language processing and other language technology, the application of such technology to language documentation and conservation has been limited. In August 2019, a workshop was held at Carnegie Mellon University in Pittsburgh to attempt to bring together language community members, documentary linguists, and technologists to discuss how to bridge this gap and create prototypes of novel and practical language revitalization technologies. This paper reports the results of this workshop, including issues discussed, and various conceived and implemented technologies for nine languages: Arapaho, Cayuga, Inuktitut, Irish Gaelic, Kidaw'ida, Kwak'wala, Ojibwe, San Juan Quiahije Chatino, and Seneca.
Stochastic Attribute-Value Grammars
Oct 23, 1996
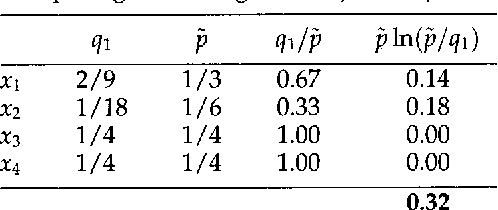
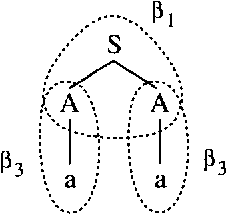
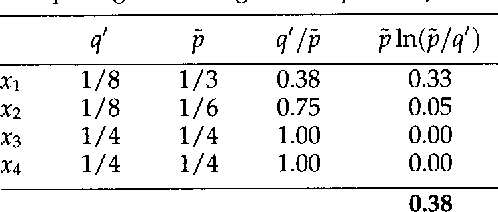
Probabilistic analogues of regular and context-free grammars are well-known in computational linguistics, and currently the subject of intensive research. To date, however, no satisfactory probabilistic analogue of attribute-value grammars has been proposed: previous attempts have failed to define a correct parameter-estimation algorithm. In the present paper, I define stochastic attribute-value grammars and give a correct algorithm for estimating their parameters. The estimation algorithm is adapted from Della Pietra, Della Pietra, and Lafferty (1995). To estimate model parameters, it is necessary to compute the expectations of certain functions under random fields. In the application discussed by Della Pietra, Della Pietra, and Lafferty (representing English orthographic constraints), Gibbs sampling can be used to estimate the needed expectations. The fact that attribute-value grammars generate constrained languages makes Gibbs sampling inapplicable, but I show how a variant of Gibbs sampling, the Metropolis-Hastings algorithm, can be used instead.