 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of LLM as a grammatical feature tagger for African American English
Feb 09, 2025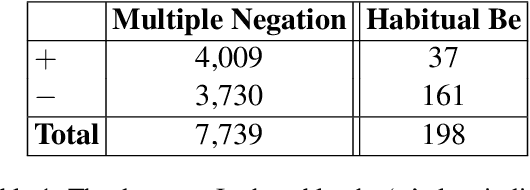
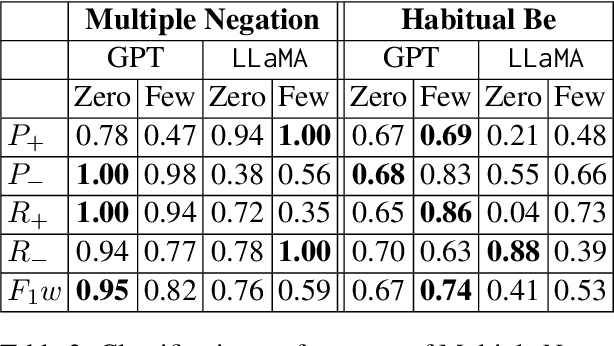
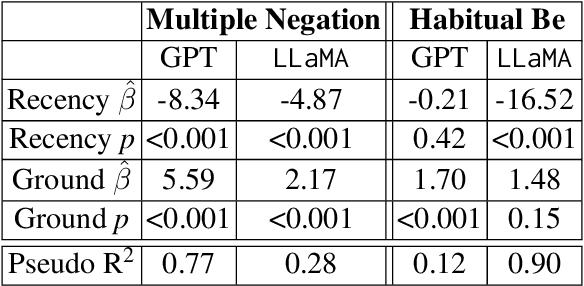
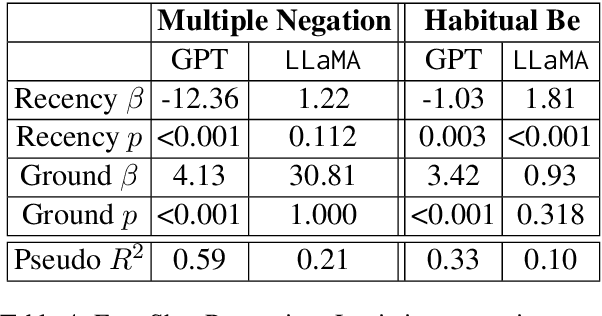
African American English (AAE) presents unique challenges in natural language processing (NLP). This research systematically compares the performance of available NLP models--rule-based, transformer-based, and large language models (LLMs)--capable of identifying key grammatical features of AAE, namely Habitual Be and Multiple Negation. These features were selected for their distinct grammatical complexity and frequency of occurrence. The evaluation involved sentence-level binary classification tasks, using both zero-shot and few-shot strategies. The analysis reveals that while LLMs show promise compared to the baseline, they are influenced by biases such as recency and unrelated features in the text such as formality. This study highlights the necessity for improved model training and architectural adjustments to better accommodate AAE's unique linguistic characteristics. Data and code are available.