 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyboards for the Endangered Idu Mishmi Language
Feb 23, 2026We present a mobile and desktop keyboard suite for Idu Mishmi, an endangered Trans-Himalayan language spoken by approximately 11,000 people in Arunachal Pradesh, India. Although a Latin-based orthography was developed in 2018, no digital input tools existed to use it, forcing speakers into ad-hoc romanizations that cannot represent the full writing system. Our keyboards comprise two tools: (1) an Android mobile keyboard, published on the Google Play Store and actively used in teacher training programs, and (2) a Windows desktop keyboard currently undergoing community testing. Both tools support the complete Idu Mishmi character inventory, including schwa, retracted schwa, nasalized vowels, and accented forms. Both operate fully offline with zero network permissions, addressing connectivity constraints and data sovereignty concerns. We describe the design, implementation, and deployment as a replicable model for other endangered language communities.
Character-aware Transformers Learn an Irregular Morphological Pattern Yet None Generalize Like Humans
Feb 15, 2026Whether neural networks can serve as cognitive models of morphological learning remains an open question. Recent work has shown that encoder-decoder models can acquire irregular patterns, but evidence that they generalize these patterns like humans is mixed. We investigate this using the Spanish \emph{L-shaped morphome}, where only the first-person singular indicative (e.g., \textit{pongo} `I put') shares its stem with all subjunctive forms (e.g., \textit{ponga, pongas}) despite lacking apparent phonological, semantic, or syntactic motivation. We compare five encoder-decoder transformers varying along two dimensions: sequential vs. position-invariant positional encoding, and atomic vs. decomposed tag representations. Positional encoding proves decisive: position-invariant models recover the correct L-shaped paradigm clustering even when L-shaped verbs are scarce in training, whereas sequential positional encoding models only partially capture the pattern. Yet none of the models productively generalize this pattern to novel forms. Position-invariant models generalize the L-shaped stem across subjunctive cells but fail to extend it to the first-person singular indicative, producing a mood-based generalization rather than the L-shaped morphomic pattern. Humans do the opposite, generalizing preferentially to the first-person singular indicative over subjunctive forms. None of the models reproduce the human pattern, highlighting the gap between statistical pattern reproduction and morphological abstraction.
Connecting the Persian-speaking World through Transliteration
Feb 27, 2025Despite speaking mutually intelligible varieties of the same language, speakers of Tajik Persian, written in a modified Cyrillic alphabet, cannot read Iranian and Afghan texts written in the Perso-Arabic script. As the vast majority of Persian text on the Internet is written in Perso-Arabic, monolingual Tajik speakers are unable to interface with the Internet in any meaningful way. Due to overwhelming similarity between the formal registers of these dialects and the scarcity of Tajik-Farsi parallel data, machine transliteration has been proposed as more a practical and appropriate solution than machine translation. This paper presents a transformer-based G2P approach to Tajik-Farsi transliteration, achieving chrF++ scores of 58.70 (Farsi to Tajik) and 74.20 (Tajik to Farsi) on novel digraphic datasets, setting a comparable baseline metric for future work. Our results also demonstrate the non-trivial difficulty of this task in both directions. We also provide an overview of the differences between the two scripts and the challenges they present, so as to aid future efforts in Tajik-Farsi transliteration.
Frequency matters: Modeling irregular morphological patterns in Spanish with Transformers
Oct 28, 2024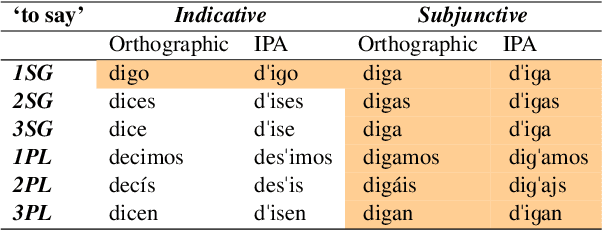
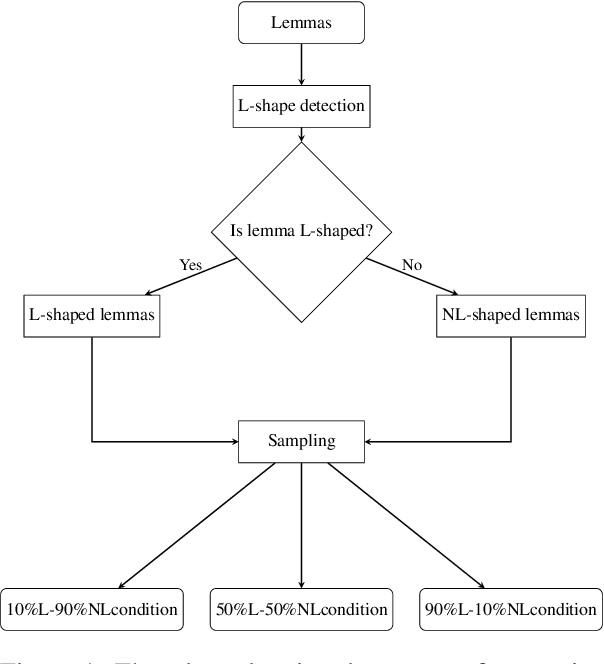
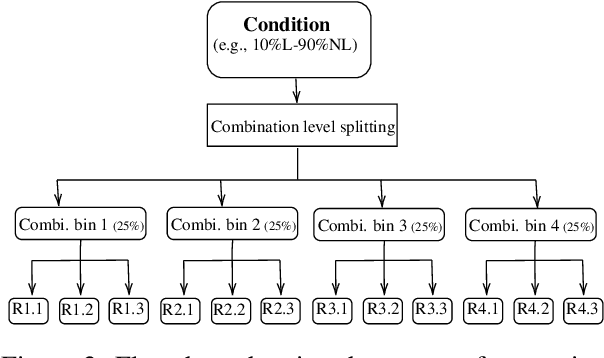
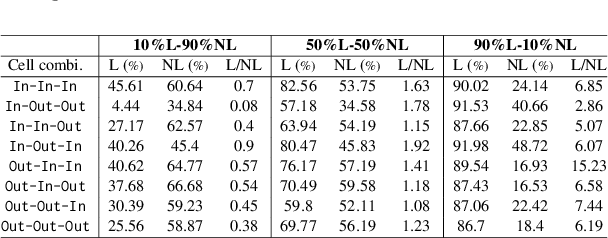
The present paper evaluates the learning behaviour of a transformer-based neural network with regard to an irregular inflectional paradigm. We apply the paradigm cell filling problem to irregular patterns. We approach this problem using the morphological reinflection task and model it as a character sequence-to-sequence learning problem. The test case under investigation are irregular verbs in Spanish. Besides many regular verbs in Spanish L-shaped verbs the first person singular indicative stem irregularly matches the subjunctive paradigm, while other indicative forms remain unaltered. We examine the role of frequency during learning and compare models under differing input frequency conditions. We train the model on a corpus of Spanish with a realistic distribution of regular and irregular verbs to compare it with models trained on input with augmented distributions of (ir)regular words. We explore how the neural models learn this L-shaped pattern using post-hoc analyses. Our experiments show that, across frequency conditions, the models are surprisingly capable of learning the irregular pattern. Furthermore, our post-hoc analyses reveal the possible sources of errors. All code and data are available at \url{https://anonymous.4open.science/r/modeling_spanish_acl-7567/} under MIT license.