 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-oriented Conversation Compiler for Agent Trace Analysis
Apr 01, 2026Agent traces carry increasing analytical value in agentic systems and context engineering, yet most prior work treats conversation format as a trivial implementation detail. Modern agent conversations, however, contain deeply structured content, including nested tool calls and results, chain-of-thought reasoning blocks, sub-agent invocations, context-window compaction boundaries, and harness-injected system directives, whose complexity far exceeds that of simple user-assistant exchanges. Feeding such traces to a reflector or other analytical mechanism in plain text, JSON, YAML, or via grep can materially degrade analysis quality. This paper presents VCC (View-oriented Conversation Compiler), a compiler (lex, parse, IR, lower, emit) that transforms raw agent JSONL logs into a family of structured views: a full view (lossless transcript serving as the canonical line-number coordinate system), a user-interface (UI) view (reconstructing the interaction as the user actually perceived it), and an adaptive view (a structure-preserving projection governed by a relevance predicate). In a context-engineering experiment on AppWorld, replacing only the reflector's input format, from raw JSONL to VCC-compiled views, leads to higher pass rates across all three model configurations tested, while cutting reflector token consumption by half to two-thirds and producing more concise learned memory. These results suggest that message format functions as infrastructure for context engineering, not as an incidental implementation choice.
Self-Consistency for LLM-Based Motion Trajectory Generation and Verification
Mar 31, 2026Self-consistency has proven to be an effective technique for improving LLM performance on natural language reasoning tasks in a lightweight, unsupervised manner. In this work, we study how to adapt self-consistency to visual domains. Specifically, we consider the generation and verification of LLM-produced motion graphics trajectories. Given a prompt (e.g., "Move the circle in a spiral path"), we first sample diverse motion trajectories from an LLM, and then identify groups of consistent trajectories via clustering. Our key insight is to model the family of shapes associated with a prompt as a prototype trajectory paired with a group of geometric transformations (e.g., rigid, similarity, and affine). Two trajectories can then be considered consistent if one can be transformed into the other under the warps allowable by the transformation group. We propose an algorithm that automatically recovers a shape family, using hierarchical relationships between a set of candidate transformation groups. Our approach improves the accuracy of LLM-based trajectory generation by 4-6%. We further extend our method to support verification, observing 11% precision gains over VLM baselines. Our code and dataset are available at https://majiaju.io/trajectory-self-consistency .
Mode Seeking meets Mean Seeking for Fast Long Video Generation
Feb 27, 2026Scaling video generation from seconds to minutes faces a critical bottleneck: while short-video data is abundant and high-fidelity, coherent long-form data is scarce and limited to narrow domains. To address this, we propose a training paradigm where Mode Seeking meets Mean Seeking, decoupling local fidelity from long-term coherence based on a unified representation via a Decoupled Diffusion Transformer. Our approach utilizes a global Flow Matching head trained via supervised learning on long videos to capture narrative structure, while simultaneously employing a local Distribution Matching head that aligns sliding windows to a frozen short-video teacher via a mode-seeking reverse-KL divergence. This strategy enables the synthesis of minute-scale videos that learns long-range coherence and motions from limited long videos via supervised flow matching, while inheriting local realism by aligning every sliding-window segment of the student to a frozen short-video teacher, resulting in a few-step fast long video generator. Evaluations show that our method effectively closes the fidelity-horizon gap by jointly improving local sharpness, motion and long-range consistency. Project website: https://primecai.github.io/mmm/.
Pretraining Frame Preservation in Autoregressive Video Memory Compression
Dec 29, 2025We present PFP, a neural network structure to compress long videos into short contexts, with an explicit pretraining objective to preserve the high-frequency details of single frames at arbitrary temporal positions. The baseline model can compress a 20-second video into a context at about 5k length, where random frames can be retrieved with perceptually preserved appearances. Such pretrained models can be directly fine-tuned as memory encoders for autoregressive video models, enabling long history memory with low context cost and relatively low fidelity loss. We evaluate the framework with ablative settings and discuss the trade-offs of possible neural architecture designs.
LouvreSAE: Sparse Autoencoders for Interpretable and Controllable Style Transfer
Dec 22, 2025Artistic style transfer in generative models remains a significant challenge, as existing methods often introduce style only via model fine-tuning, additional adapters, or prompt engineering, all of which can be computationally expensive and may still entangle style with subject matter. In this paper, we introduce a training- and inference-light, interpretable method for representing and transferring artistic style. Our approach leverages an art-specific Sparse Autoencoder (SAE) on top of latent embeddings of generative image models. Trained on artistic data, our SAE learns an emergent, largely disentangled set of stylistic and compositional concepts, corresponding to style-related elements pertaining brushwork, texture, and color palette, as well as semantic and structural concepts. We call it LouvreSAE and use it to construct style profiles: compact, decomposable steering vectors that enable style transfer without any model updates or optimization. Unlike prior concept-based style transfer methods, our method requires no fine-tuning, no LoRA training, and no additional inference passes, enabling direct steering of artistic styles from only a few reference images. We validate our method on ArtBench10, achieving or surpassing existing methods on style evaluations (VGG Style Loss and CLIP Score Style) while being 1.7-20x faster and, critically, interpretable.
StreamDiffusionV2: A Streaming System for Dynamic and Interactive Video Generation
Nov 10, 2025



Generative models are reshaping the live-streaming industry by redefining how content is created, styled, and delivered. Previous image-based streaming diffusion models have powered efficient and creative live streaming products but have hit limits on temporal consistency due to the foundation of image-based designs. Recent advances in video diffusion have markedly improved temporal consistency and sampling efficiency for offline generation. However, offline generation systems primarily optimize throughput by batching large workloads. In contrast, live online streaming operates under strict service-level objectives (SLOs): time-to-first-frame must be minimal, and every frame must meet a per-frame deadline with low jitter. Besides, scalable multi-GPU serving for real-time streams remains largely unresolved so far. To address this, we present StreamDiffusionV2, a training-free pipeline for interactive live streaming with video diffusion models. StreamDiffusionV2 integrates an SLO-aware batching scheduler and a block scheduler, together with a sink-token--guided rolling KV cache, a motion-aware noise controller, and other system-level optimizations. Moreover, we introduce a scalable pipeline orchestration that parallelizes the diffusion process across denoising steps and network layers, achieving near-linear FPS scaling without violating latency guarantees. The system scales seamlessly across heterogeneous GPU environments and supports flexible denoising steps (e.g., 1--4), enabling both ultra-low-latency and higher-quality modes. Without TensorRT or quantization, StreamDiffusionV2 renders the first frame within 0.5s and attains 58.28 FPS with a 14B-parameter model and 64.52 FPS with a 1.3B-parameter model on four H100 GPUs, making state-of-the-art generative live streaming practical and accessible--from individual creators to enterprise-scale platforms.
Hollywood Town: Long-Video Generation via Cross-Modal Multi-Agent Orchestration
Oct 25, 2025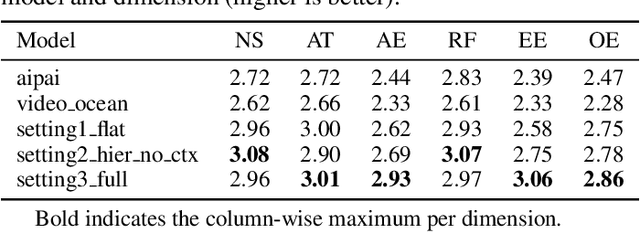
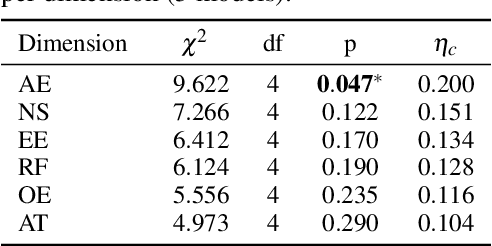
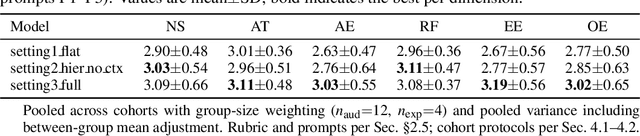
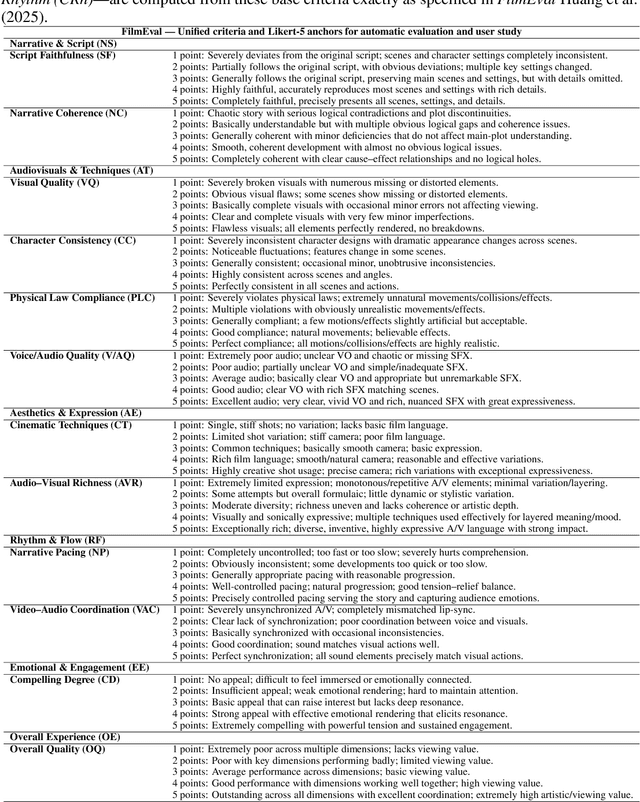
Recent advancements in multi-agent systems have demonstrated significant potential for enhancing creative task performance, such as long video generation. This study introduces three innovations to improve multi-agent collaboration. First, we propose OmniAgent, a hierarchical, graph-based multi-agent framework for long video generation that leverages a film-production-inspired architecture to enable modular specialization and scalable inter-agent collaboration. Second, inspired by context engineering, we propose hypergraph nodes that enable temporary group discussions among agents lacking sufficient context, reducing individual memory requirements while ensuring adequate contextual information. Third, we transition from directed acyclic graphs (DAGs) to directed cyclic graphs with limited retries, allowing agents to reflect and refine outputs iteratively, thereby improving earlier stages through feedback from subsequent nodes. These contributions lay the groundwork for developing more robust multi-agent systems in creative tasks.
Taming Flow-based I2V Models for Creative Video Editing
Sep 26, 2025Although image editing techniques have advanced significantly, video editing, which aims to manipulate videos according to user intent, remains an emerging challenge. Most existing image-conditioned video editing methods either require inversion with model-specific design or need extensive optimization, limiting their capability of leveraging up-to-date image-to-video (I2V) models to transfer the editing capability of image editing models to the video domain. To this end, we propose IF-V2V, an Inversion-Free method that can adapt off-the-shelf flow-matching-based I2V models for video editing without significant computational overhead. To circumvent inversion, we devise Vector Field Rectification with Sample Deviation to incorporate information from the source video into the denoising process by introducing a deviation term into the denoising vector field. To further ensure consistency with the source video in a model-agnostic way, we introduce Structure-and-Motion-Preserving Initialization to generate motion-aware temporally correlated noise with structural information embedded. We also present a Deviation Caching mechanism to minimize the additional computational cost for denoising vector rectification without significantly impacting editing quality. Evaluations demonstrate that our method achieves superior editing quality and consistency over existing approaches, offering a lightweight plug-and-play solution to realize visual creativity.
Mixture of Contexts for Long Video Generation
Aug 28, 2025Long video generation is fundamentally a long context memory problem: models must retain and retrieve salient events across a long range without collapsing or drifting. However, scaling diffusion transformers to generate long-context videos is fundamentally limited by the quadratic cost of self-attention, which makes memory and computation intractable and difficult to optimize for long sequences. We recast long-context video generation as an internal information retrieval task and propose a simple, learnable sparse attention routing module, Mixture of Contexts (MoC), as an effective long-term memory retrieval engine. In MoC, each query dynamically selects a few informative chunks plus mandatory anchors (caption, local windows) to attend to, with causal routing that prevents loop closures. As we scale the data and gradually sparsify the routing, the model allocates compute to salient history, preserving identities, actions, and scenes over minutes of content. Efficiency follows as a byproduct of retrieval (near-linear scaling), which enables practical training and synthesis, and the emergence of memory and consistency at the scale of minutes.
Captain Cinema: Towards Short Movie Generation
Jul 24, 2025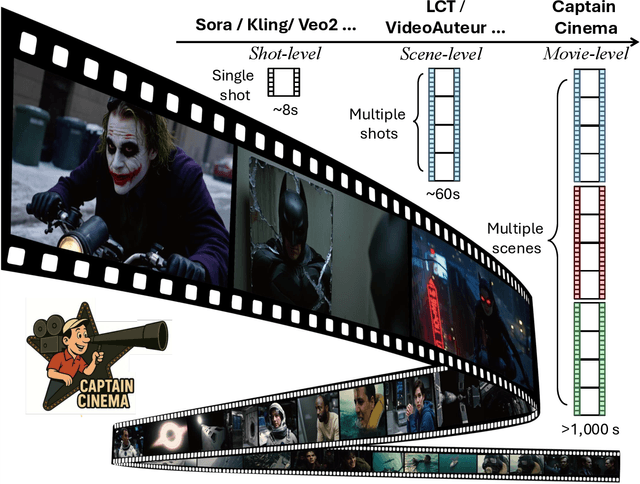
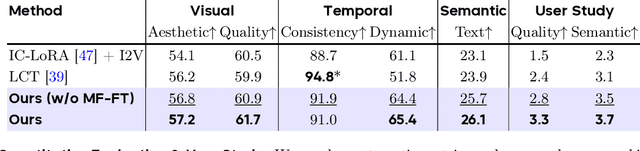

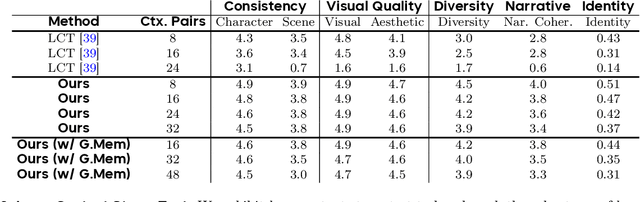
We present Captain Cinema, a generation framework for short movie generation. Given a detailed textual description of a movie storyline, our approach firstly generates a sequence of keyframes that outline the entire narrative, which ensures long-range coherence in both the storyline and visual appearance (e.g., scenes and characters). We refer to this step as top-down keyframe planning. These keyframes then serve as conditioning signals for a video synthesis model, which supports long context learning, to produce the spatio-temporal dynamics between them. This step is referred to as bottom-up video synthesis. To support stable and efficient generation of multi-scene long narrative cinematic works, we introduce an interleaved training strategy for Multimodal Diffusion Transformers (MM-DiT), specifically adapted for long-context video data. Our model is trained on a specially curated cinematic dataset consisting of interleaved data pairs. Our experiments demonstrate that Captain Cinema performs favorably in the automated creation of visually coherent and narrative consistent short movies in high quality and efficiency. Project page: https://thecinema.ai