 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeriving Hyperparameter Scaling Laws via Modern Optimization Theory
Mar 16, 2026Hyperparameter transfer has become an important component of modern large-scale training recipes. Existing methods, such as muP, primarily focus on transfer between model sizes, with transfer across batch sizes and training horizons often relying on empirical scaling rules informed by insights from timescale preservation, quadratic proxies, and continuous-time approximations. We study hyperparameter scaling laws for modern first-order optimizers through the lens of recent convergence bounds for methods based on the Linear Minimization Oracle (LMO), a framework that includes normalized SGD, signSGD (approximating Adam), and Muon. Treating bounds in recent literature as a proxy and minimizing them across different tuning regimes yields closed-form power-law schedules for learning rate, momentum, and batch size as functions of the iteration or token budget. Our analysis, holding model size fixed, recovers most insights and observations from the literature under a unified and principled perspective, with clear directions open for future research. Our results draw particular attention to the interaction between momentum and batch-size scaling, suggesting that optimal performance may be achieved with several scaling strategies.
Scaling Behavior of Discrete Diffusion Language Models
Dec 11, 2025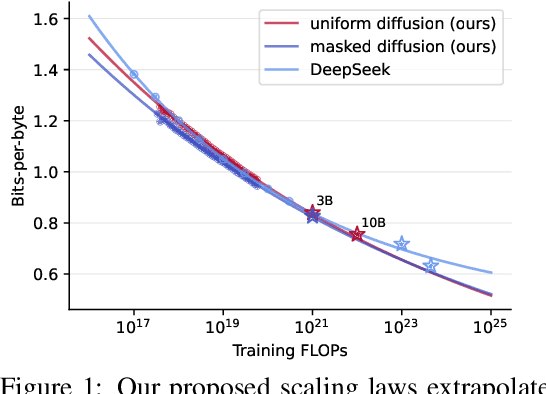
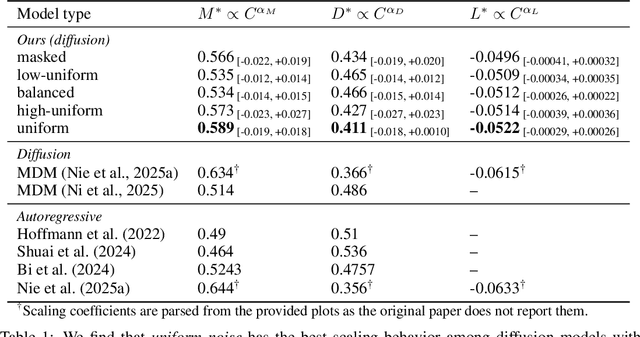
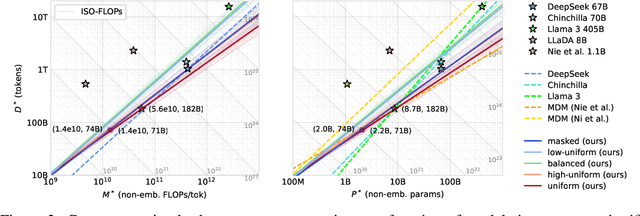
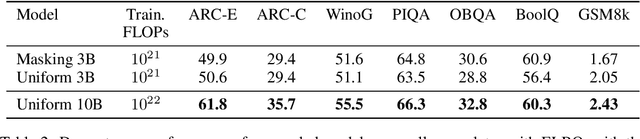
Modern LLM pre-training consumes vast amounts of compute and training data, making the scaling behavior, or scaling laws, of different models a key distinguishing factor. Discrete diffusion language models (DLMs) have been proposed as an alternative to autoregressive language models (ALMs). However, their scaling behavior has not yet been fully explored, with prior work suggesting that they require more data and compute to match the performance of ALMs. We study the scaling behavior of DLMs on different noise types by smoothly interpolating between masked and uniform diffusion while paying close attention to crucial hyperparameters such as batch size and learning rate. Our experiments reveal that the scaling behavior of DLMs strongly depends on the noise type and is considerably different from ALMs. While all noise types converge to similar loss values in compute-bound scaling, we find that uniform diffusion requires more parameters and less data for compute-efficient training compared to masked diffusion, making them a promising candidate in data-bound settings. We scale our uniform diffusion model up to 10B parameters trained for $10^{22}$ FLOPs, confirming the predicted scaling behavior and making it the largest publicly known uniform diffusion model to date.
Exploring Magnitude Preservation and Rotation Modulation in Diffusion Transformers
May 25, 2025



Denoising diffusion models exhibit remarkable generative capabilities, but remain challenging to train due to their inherent stochasticity, where high-variance gradient estimates lead to slow convergence. Previous works have shown that magnitude preservation helps with stabilizing training in the U-net architecture. This work explores whether this effect extends to the Diffusion Transformer (DiT) architecture. As such, we propose a magnitude-preserving design that stabilizes training without normalization layers. Motivated by the goal of maintaining activation magnitudes, we additionally introduce rotation modulation, which is a novel conditioning method using learned rotations instead of traditional scaling or shifting. Through empirical evaluations and ablation studies on small-scale models, we show that magnitude-preserving strategies significantly improve performance, notably reducing FID scores by $\sim$12.8%. Further, we show that rotation modulation combined with scaling is competitive with AdaLN, while requiring $\sim$5.4% fewer parameters. This work provides insights into conditioning strategies and magnitude control. We will publicly release the implementation of our method.
Generalized Interpolating Discrete Diffusion
Mar 06, 2025



While state-of-the-art language models achieve impressive results through next-token prediction, they have inherent limitations such as the inability to revise already generated tokens. This has prompted exploration of alternative approaches such as discrete diffusion. However, masked diffusion, which has emerged as a popular choice due to its simplicity and effectiveness, reintroduces this inability to revise words. To overcome this, we generalize masked diffusion and derive the theoretical backbone of a family of general interpolating discrete diffusion (GIDD) processes offering greater flexibility in the design of the noising processes. Leveraging a novel diffusion ELBO, we achieve compute-matched state-of-the-art performance in diffusion language modeling. Exploiting GIDD's flexibility, we explore a hybrid approach combining masking and uniform noise, leading to improved sample quality and unlocking the ability for the model to correct its own mistakes, an area where autoregressive models notoriously have struggled. Our code and models are open-source: https://github.com/dvruette/gidd/
A Language Model's Guide Through Latent Space
Feb 22, 2024Concept guidance has emerged as a cheap and simple way to control the behavior of language models by probing their hidden representations for concept vectors and using them to perturb activations at inference time. While the focus of previous work has largely been on truthfulness, in this paper we extend this framework to a richer set of concepts such as appropriateness, humor, creativity and quality, and explore to what degree current detection and guidance strategies work in these challenging settings. To facilitate evaluation, we develop a novel metric for concept guidance that takes into account both the success of concept elicitation as well as the potential degradation in fluency of the guided model. Our extensive experiments reveal that while some concepts such as truthfulness more easily allow for guidance with current techniques, novel concepts such as appropriateness or humor either remain difficult to elicit, need extensive tuning to work, or even experience confusion. Moreover, we find that probes with optimal detection accuracies do not necessarily make for the optimal guides, contradicting previous observations for truthfulness. Our work warrants a deeper investigation into the interplay between detectability, guidability, and the nature of the concept, and we hope that our rich experimental test-bed for guidance research inspires stronger follow-up approaches.
FABRIC: Personalizing Diffusion Models with Iterative Feedback
Jul 19, 2023In an era where visual content generation is increasingly driven by machine learning, the integration of human feedback into generative models presents significant opportunities for enhancing user experience and output quality. This study explores strategies for incorporating iterative human feedback into the generative process of diffusion-based text-to-image models. We propose FABRIC, a training-free approach applicable to a wide range of popular diffusion models, which exploits the self-attention layer present in the most widely used architectures to condition the diffusion process on a set of feedback images. To ensure a rigorous assessment of our approach, we introduce a comprehensive evaluation methodology, offering a robust mechanism to quantify the performance of generative visual models that integrate human feedback. We show that generation results improve over multiple rounds of iterative feedback through exhaustive analysis, implicitly optimizing arbitrary user preferences. The potential applications of these findings extend to fields such as personalized content creation and customization.
OpenAssistant Conversations -- Democratizing Large Language Model Alignment
Apr 14, 2023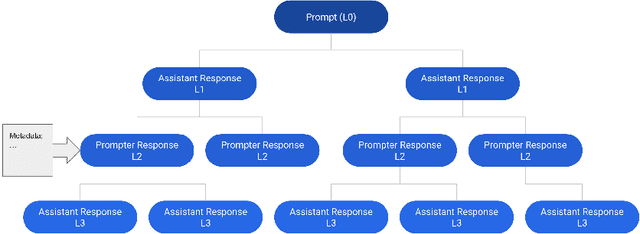
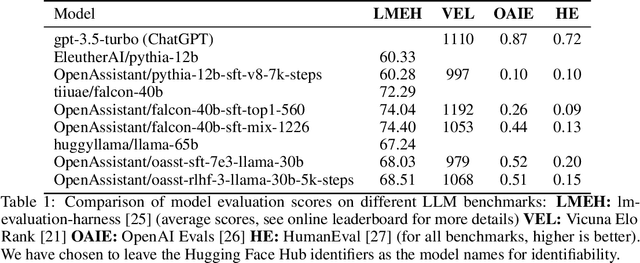
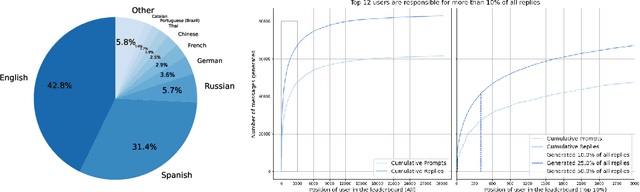

Aligning large language models (LLMs) with human preferences has proven to drastically improve usability and has driven rapid adoption as demonstrated by ChatGPT. Alignment techniques such as supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) greatly reduce the required skill and domain knowledge to effectively harness the capabilities of LLMs, increasing their accessibility and utility across various domains. However, state-of-the-art alignment techniques like RLHF rely on high-quality human feedback data, which is expensive to create and often remains proprietary. In an effort to democratize research on large-scale alignment, we release OpenAssistant Conversations, a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages distributed across 66,497 conversation trees, in 35 different languages, annotated with 461,292 quality ratings. The corpus is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers. To demonstrate the OpenAssistant Conversations dataset's effectiveness, we present OpenAssistant, the first fully open-source large-scale instruction-tuned model to be trained on human data. A preference study revealed that OpenAssistant replies are comparably preferred to GPT-3.5-turbo (ChatGPT) with a relative winrate of 48.3% vs. 51.7% respectively. We release our code and data under fully permissive licenses.
FIGARO: Generating Symbolic Music with Fine-Grained Artistic Control
Feb 01, 2022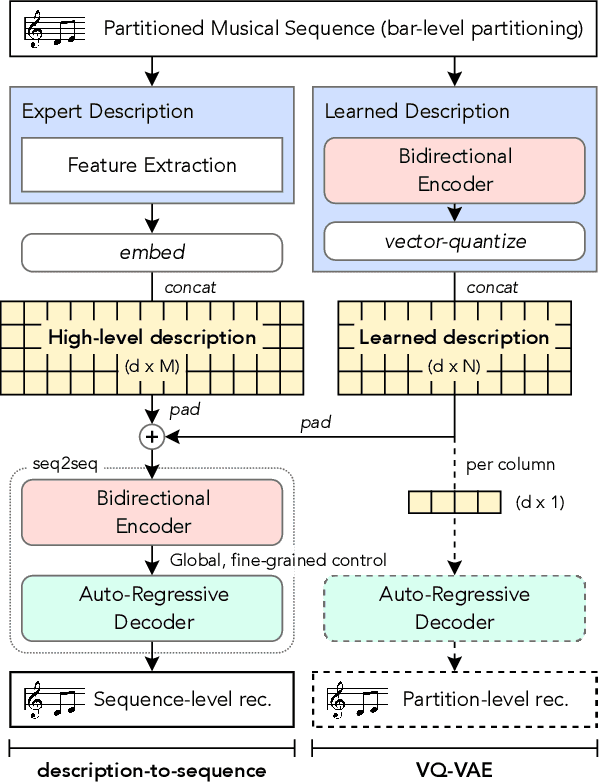

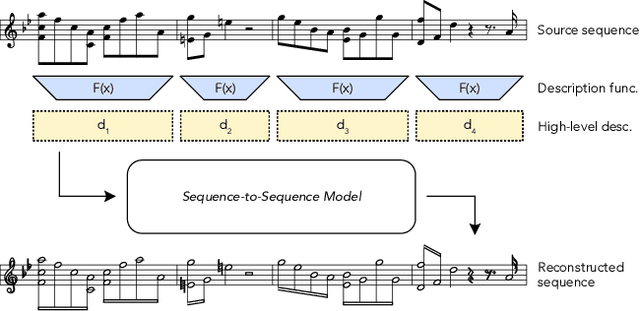
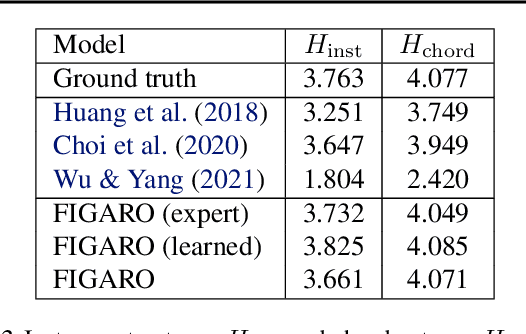
Generating music with deep neural networks has been an area of active research in recent years. While the quality of generated samples has been steadily increasing, most methods are only able to exert minimal control over the generated sequence, if any. We propose the self-supervised description-to-sequence task, which allows for fine-grained controllable generation on a global level. We do so by extracting high-level features about the target sequence and learning the conditional distribution of sequences given the corresponding high-level description in a sequence-to-sequence modelling setup. We train FIGARO (FIne-grained music Generation via Attention-based, RObust control) by applying description-to-sequence modelling to symbolic music. By combining learned high level features with domain knowledge, which acts as a strong inductive bias, the model achieves state-of-the-art results in controllable symbolic music generation and generalizes well beyond the training distribution.