 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved Traditional Chinese Evaluation Suite for Foundation Model
Mar 04, 2024



We present TMMLU+, a comprehensive dataset designed for the Traditional Chinese massive multitask language understanding dataset. TMMLU+ is a multiple-choice question-answering dataset with 66 subjects from elementary to professional level. Compared to its predecessor, TMMLU, TMMLU+ is six times larger and boasts a more balanced subject distribution. We included benchmark results in TMMLU+ from closed-source models and 24 open-weight Chinese large language models of parameters ranging from 1.8B to 72B. Our findings reveal that Traditional Chinese models still trail behind their Simplified Chinese counterparts. Additionally, current large language models have yet to outperform human performance in average scores. We publicly release our dataset and the corresponding benchmark source code.
OpenAssistant Conversations -- Democratizing Large Language Model Alignment
Apr 14, 2023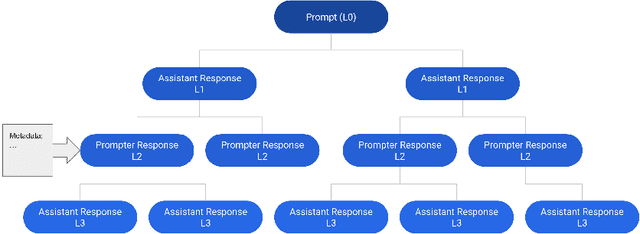
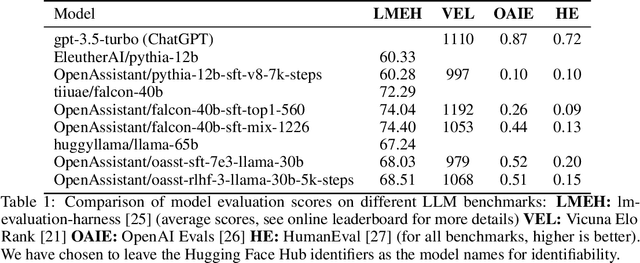
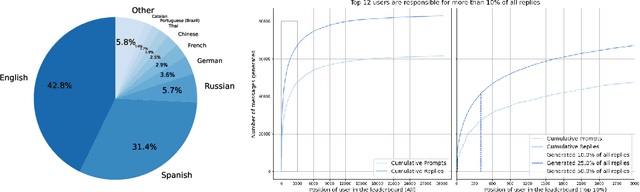

Aligning large language models (LLMs) with human preferences has proven to drastically improve usability and has driven rapid adoption as demonstrated by ChatGPT. Alignment techniques such as supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) greatly reduce the required skill and domain knowledge to effectively harness the capabilities of LLMs, increasing their accessibility and utility across various domains. However, state-of-the-art alignment techniques like RLHF rely on high-quality human feedback data, which is expensive to create and often remains proprietary. In an effort to democratize research on large-scale alignment, we release OpenAssistant Conversations, a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages distributed across 66,497 conversation trees, in 35 different languages, annotated with 461,292 quality ratings. The corpus is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers. To demonstrate the OpenAssistant Conversations dataset's effectiveness, we present OpenAssistant, the first fully open-source large-scale instruction-tuned model to be trained on human data. A preference study revealed that OpenAssistant replies are comparably preferred to GPT-3.5-turbo (ChatGPT) with a relative winrate of 48.3% vs. 51.7% respectively. We release our code and data under fully permissive licenses.
Gradient Normalization for Generative Adversarial Networks
Sep 06, 2021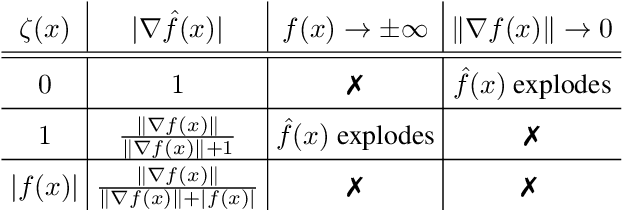

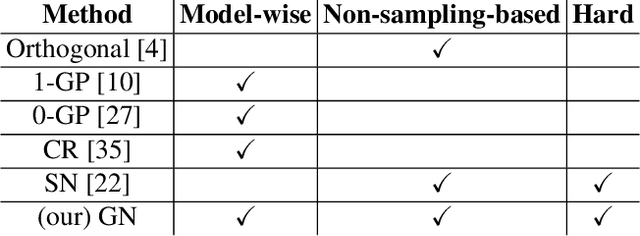

In this paper, we propose a novel normalization method called gradient normalization (GN) to tackle the training instability of Generative Adversarial Networks (GANs) caused by the sharp gradient space. Unlike existing work such as gradient penalty and spectral normalization, the proposed GN only imposes a hard 1-Lipschitz constraint on the discriminator function, which increases the capacity of the discriminator. Moreover, the proposed gradient normalization can be applied to different GAN architectures with little modification. Extensive experiments on four datasets show that GANs trained with gradient normalization outperform existing methods in terms of both Frechet Inception Distance and Inception Score.