 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTF-TI2I: Training-Free Text-and-Image-to-Image Generation via Multi-Modal Implicit-Context Learning in Text-to-Image Models
Mar 19, 2025Text-and-Image-To-Image (TI2I), an extension of Text-To-Image (T2I), integrates image inputs with textual instructions to enhance image generation. Existing methods often partially utilize image inputs, focusing on specific elements like objects or styles, or they experience a decline in generation quality with complex, multi-image instructions. To overcome these challenges, we introduce Training-Free Text-and-Image-to-Image (TF-TI2I), which adapts cutting-edge T2I models such as SD3 without the need for additional training. Our method capitalizes on the MM-DiT architecture, in which we point out that textual tokens can implicitly learn visual information from vision tokens. We enhance this interaction by extracting a condensed visual representation from reference images, facilitating selective information sharing through Reference Contextual Masking -- this technique confines the usage of contextual tokens to instruction-relevant visual information. Additionally, our Winner-Takes-All module mitigates distribution shifts by prioritizing the most pertinent references for each vision token. Addressing the gap in TI2I evaluation, we also introduce the FG-TI2I Bench, a comprehensive benchmark tailored for TI2I and compatible with existing T2I methods. Our approach shows robust performance across various benchmarks, confirming its effectiveness in handling complex image-generation tasks.
FreeCond: Free Lunch in the Input Conditions of Text-Guided Inpainting
Nov 30, 2024In this study, we aim to determine and solve the deficiency of Stable Diffusion Inpainting (SDI) in following the instruction of both prompt and mask. Due to the training bias from masking, the inpainting quality is hindered when the prompt instruction and image condition are not related. Therefore, we conduct a detailed analysis of the internal representations learned by SDI, focusing on how the mask input influences the cross-attention layer. We observe that adapting text key tokens toward the input mask enables the model to selectively paint within the given area. Leveraging these insights, we propose FreeCond, which adjusts only the input mask condition and image condition. By increasing the latent mask value and modifying the frequency of image condition, we align the cross-attention features with the model's training bias to improve generation quality without additional computation, particularly when user inputs are complicated and deviate from the training setup. Extensive experiments demonstrate that FreeCond can enhance any SDI-based model, e.g., yielding up to a 60% and 58% improvement of SDI and SDXLI in the CLIP score.
Gradient Normalization for Generative Adversarial Networks
Sep 06, 2021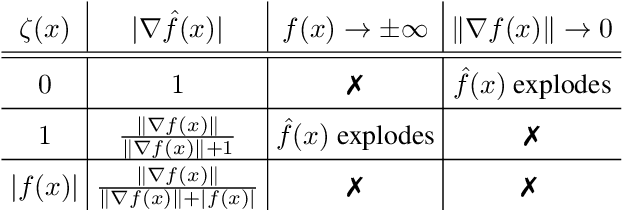

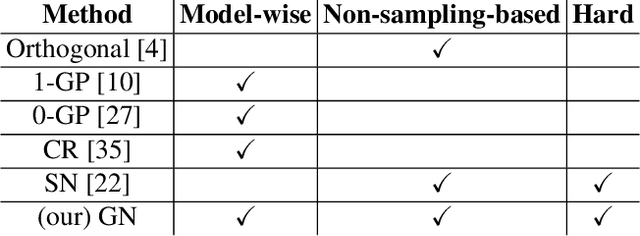

In this paper, we propose a novel normalization method called gradient normalization (GN) to tackle the training instability of Generative Adversarial Networks (GANs) caused by the sharp gradient space. Unlike existing work such as gradient penalty and spectral normalization, the proposed GN only imposes a hard 1-Lipschitz constraint on the discriminator function, which increases the capacity of the discriminator. Moreover, the proposed gradient normalization can be applied to different GAN architectures with little modification. Extensive experiments on four datasets show that GANs trained with gradient normalization outperform existing methods in terms of both Frechet Inception Distance and Inception Score.
Attractive or Faithful? Popularity-Reinforced Learning for Inspired Headline Generation
Feb 06, 2020
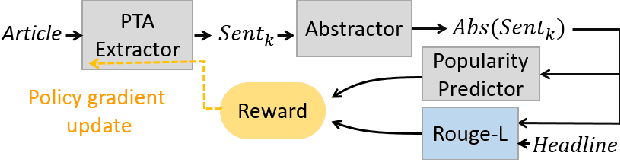


With the rapid proliferation of online media sources and published news, headlines have become increasingly important for attracting readers to news articles, since users may be overwhelmed with the massive information. In this paper, we generate inspired headlines that preserve the nature of news articles and catch the eye of the reader simultaneously. The task of inspired headline generation can be viewed as a specific form of Headline Generation (HG) task, with the emphasis on creating an attractive headline from a given news article. To generate inspired headlines, we propose a novel framework called POpularity-Reinforced Learning for inspired Headline Generation (PORL-HG). PORL-HG exploits the extractive-abstractive architecture with 1) Popular Topic Attention (PTA) for guiding the extractor to select the attractive sentence from the article and 2) a popularity predictor for guiding the abstractor to rewrite the attractive sentence. Moreover, since the sentence selection of the extractor is not differentiable, techniques of reinforcement learning (RL) are utilized to bridge the gap with rewards obtained from a popularity score predictor. Through quantitative and qualitative experiments, we show that the proposed PORL-HG significantly outperforms the state-of-the-art headline generation models in terms of attractiveness evaluated by both human (71.03%) and the predictor (at least 27.60%), while the faithfulness of PORL-HG is also comparable to the state-of-the-art generation model.