 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICo3D: An Interactive Conversational 3D Virtual Human
Jan 19, 2026This work presents Interactive Conversational 3D Virtual Human (ICo3D), a method for generating an interactive, conversational, and photorealistic 3D human avatar. Based on multi-view captures of a subject, we create an animatable 3D face model and a dynamic 3D body model, both rendered by splatting Gaussian primitives. Once merged together, they represent a lifelike virtual human avatar suitable for real-time user interactions. We equip our avatar with an LLM for conversational ability. During conversation, the audio speech of the avatar is used as a driving signal to animate the face model, enabling precise synchronization. We describe improvements to our dynamic Gaussian models that enhance photorealism: SWinGS++ for body reconstruction and HeadGaS++ for face reconstruction, and provide as well a solution to merge the separate face and body models without artifacts. We also present a demo of the complete system, showcasing several use cases of real-time conversation with the 3D avatar. Our approach offers a fully integrated virtual avatar experience, supporting both oral and written form interactions in immersive environments. ICo3D is applicable to a wide range of fields, including gaming, virtual assistance, and personalized education, among others. Project page: https://ico3d.github.io/
GASPACHO: Gaussian Splatting for Controllable Humans and Objects
Mar 12, 2025We present GASPACHO: a method for generating photorealistic controllable renderings of human-object interactions. Given a set of multi-view RGB images of human-object interactions, our method reconstructs animatable templates of the human and object as separate sets of Gaussians simultaneously. Different from existing work, which focuses on human reconstruction and ignores objects as background, our method explicitly reconstructs both humans and objects, thereby allowing for controllable renderings of novel human object interactions in different poses from novel-camera viewpoints. During reconstruction, we constrain the Gaussians that generate rendered images to be a linear function of a set of canonical Gaussians. By simply changing the parameters of the linear deformation functions after training, our method can generate renderings of novel human-object interaction in novel poses from novel camera viewpoints. We learn the 3D Gaussian properties of the canonical Gaussians on the underlying 2D manifold of the canonical human and object templates. This in turns requires a canonical object template with a fixed UV unwrapping. To define such an object template, we use a feature based representation to track the object across the multi-view sequence. We further propose an occlusion aware photometric loss that allows for reconstructions under significant occlusions. Several experiments on two human-object datasets - BEHAVE and DNA-Rendering - demonstrate that our method allows for high-quality reconstruction of human and object templates under significant occlusion and the synthesis of controllable renderings of novel human-object interactions in novel human poses from novel camera views.
FORCE: Dataset and Method for Intuitive Physics Guided Human-object Interaction
Mar 17, 2024

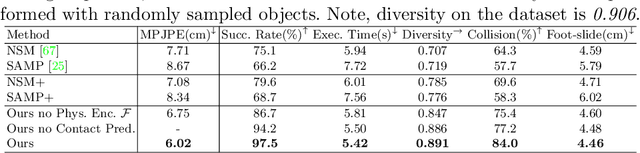
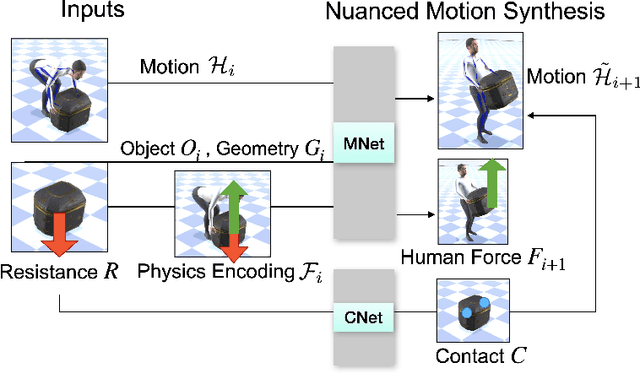
Interactions between human and objects are influenced not only by the object's pose and shape, but also by physical attributes such as object mass and surface friction. They introduce important motion nuances that are essential for diversity and realism. Despite advancements in recent kinematics-based methods, this aspect has been overlooked. Generating nuanced human motion presents two challenges. First, it is non-trivial to learn from multi-modal human and object information derived from both the physical and non-physical attributes. Second, there exists no dataset capturing nuanced human interactions with objects of varying physical properties, hampering model development. This work addresses the gap by introducing the FORCE model, a kinematic approach for synthesizing diverse, nuanced human-object interactions by modeling physical attributes. Our key insight is that human motion is dictated by the interrelation between the force exerted by the human and the perceived resistance. Guided by a novel intuitive physics encoding, the model captures the interplay between human force and resistance. Experiments also demonstrate incorporating human force facilitates learning multi-class motion. Accompanying our model, we contribute the FORCE dataset. It features diverse, different-styled motion through interactions with varying resistances.
SWAGS: Sampling Windows Adaptively for Dynamic 3D Gaussian Splatting
Dec 20, 2023Novel view synthesis has shown rapid progress recently, with methods capable of producing evermore photo-realistic results. 3D Gaussian Splatting has emerged as a particularly promising method, producing high-quality renderings of static scenes and enabling interactive viewing at real-time frame rates. However, it is currently limited to static scenes only. In this work, we extend 3D Gaussian Splatting to reconstruct dynamic scenes. We model the dynamics of a scene using a tunable MLP, which learns the deformation field from a canonical space to a set of 3D Gaussians per frame. To disentangle the static and dynamic parts of the scene, we learn a tuneable parameter for each Gaussian, which weighs the respective MLP parameters to focus attention on the dynamic parts. This improves the model's ability to capture dynamics in scenes with an imbalance of static to dynamic regions. To handle scenes of arbitrary length whilst maintaining high rendering quality, we introduce an adaptive window sampling strategy to partition the sequence into windows based on the amount of movement in the sequence. We train a separate dynamic Gaussian Splatting model for each window, allowing the canonical representation to change, thus enabling the reconstruction of scenes with significant geometric or topological changes. Temporal consistency is enforced using a fine-tuning step with self-supervising consistency loss on randomly sampled novel views. As a result, our method produces high-quality renderings of general dynamic scenes with competitive quantitative performance, which can be viewed in real-time with our dynamic interactive viewer.
HeadGaS: Real-Time Animatable Head Avatars via 3D Gaussian Splatting
Dec 05, 2023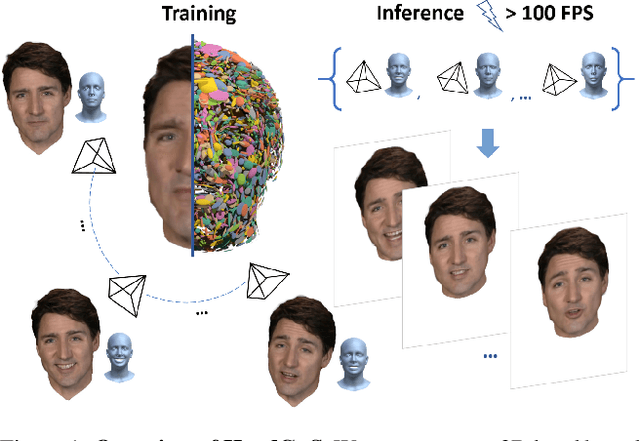
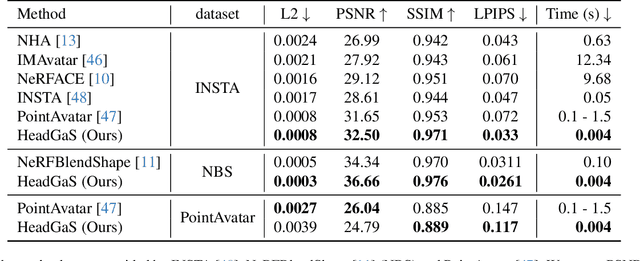
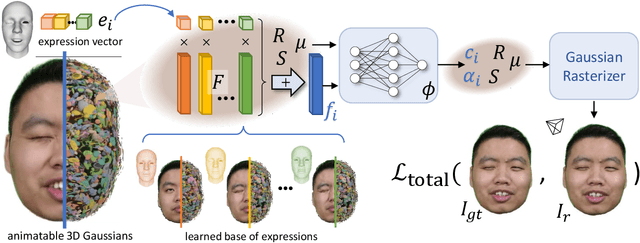
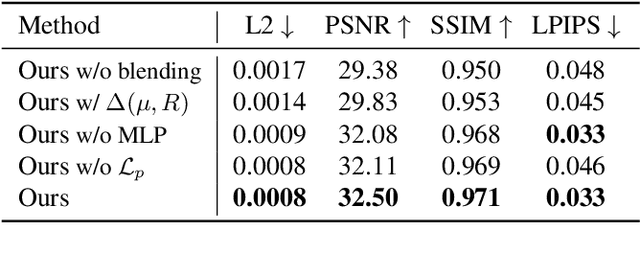
3D head animation has seen major quality and runtime improvements over the last few years, particularly empowered by the advances in differentiable rendering and neural radiance fields. Real-time rendering is a highly desirable goal for real-world applications. We propose HeadGaS, the first model to use 3D Gaussian Splats (3DGS) for 3D head reconstruction and animation. In this paper we introduce a hybrid model that extends the explicit representation from 3DGS with a base of learnable latent features, which can be linearly blended with low-dimensional parameters from parametric head models to obtain expression-dependent final color and opacity values. We demonstrate that HeadGaS delivers state-of-the-art results in real-time inference frame rates, which surpasses baselines by up to ~2dB, while accelerating rendering speed by over x10.
Human Gaussian Splatting: Real-time Rendering of Animatable Avatars
Nov 28, 2023



This work addresses the problem of real-time rendering of photorealistic human body avatars learned from multi-view videos. While the classical approaches to model and render virtual humans generally use a textured mesh, recent research has developed neural body representations that achieve impressive visual quality. However, these models are difficult to render in real-time and their quality degrades when the character is animated with body poses different than the training observations. We propose the first animatable human model based on 3D Gaussian Splatting, that has recently emerged as a very efficient alternative to neural radiance fields. Our body is represented by a set of gaussian primitives in a canonical space which are deformed in a coarse to fine approach that combines forward skinning and local non-rigid refinement. We describe how to learn our Human Gaussian Splatting (\OURS) model in an end-to-end fashion from multi-view observations, and evaluate it against the state-of-the-art approaches for novel pose synthesis of clothed body. Our method presents a PSNR 1.5dbB better than the state-of-the-art on THuman4 dataset while being able to render at 20fps or more.
DisPositioNet: Disentangled Pose and Identity in Semantic Image Manipulation
Nov 10, 2022



Graph representation of objects and their relations in a scene, known as a scene graph, provides a precise and discernible interface to manipulate a scene by modifying the nodes or the edges in the graph. Although existing works have shown promising results in modifying the placement and pose of objects, scene manipulation often leads to losing some visual characteristics like the appearance or identity of objects. In this work, we propose DisPositioNet, a model that learns a disentangled representation for each object for the task of image manipulation using scene graphs in a self-supervised manner. Our framework enables the disentanglement of the variational latent embeddings as well as the feature representation in the graph. In addition to producing more realistic images due to the decomposition of features like pose and identity, our method takes advantage of the probabilistic sampling in the intermediate features to generate more diverse images in object replacement or addition tasks. The results of our experiments show that disentangling the feature representations in the latent manifold of the model outperforms the previous works qualitatively and quantitatively on two public benchmarks. Project Page: https://scenegenie.github.io/DispositioNet/
Object-aware Monocular Depth Prediction with Instance Convolutions
Dec 02, 2021



With the advent of deep learning, estimating depth from a single RGB image has recently received a lot of attention, being capable of empowering many different applications ranging from path planning for robotics to computational cinematography. Nevertheless, while the depth maps are in their entirety fairly reliable, the estimates around object discontinuities are still far from satisfactory. This can be contributed to the fact that the convolutional operator naturally aggregates features across object discontinuities, resulting in smooth transitions rather than clear boundaries. Therefore, in order to circumvent this issue, we propose a novel convolutional operator which is explicitly tailored to avoid feature aggregation of different object parts. In particular, our method is based on estimating per-part depth values by means of superpixels. The proposed convolutional operator, which we dub "Instance Convolution", then only considers each object part individually on the basis of the estimated superpixels. Our evaluation with respect to the NYUv2 as well as the iBims dataset clearly demonstrates the superiority of Instance Convolutions over the classical convolution at estimating depth around occlusion boundaries, while producing comparable results elsewhere. Code will be made publicly available upon acceptance.
MIGS: Meta Image Generation from Scene Graphs
Oct 22, 2021
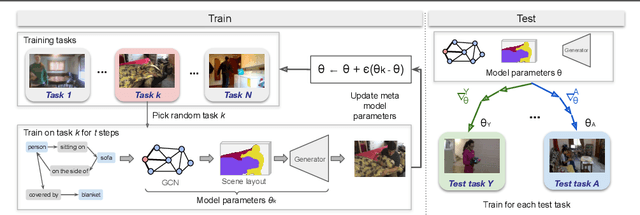


Generation of images from scene graphs is a promising direction towards explicit scene generation and manipulation. However, the images generated from the scene graphs lack quality, which in part comes due to high difficulty and diversity in the data. We propose MIGS (Meta Image Generation from Scene Graphs), a meta-learning based approach for few-shot image generation from graphs that enables adapting the model to different scenes and increases the image quality by training on diverse sets of tasks. By sampling the data in a task-driven fashion, we train the generator using meta-learning on different sets of tasks that are categorized based on the scene attributes. Our results show that using this meta-learning approach for the generation of images from scene graphs achieves state-of-the-art performance in terms of image quality and capturing the semantic relationships in the scene. Project Website: https://migs2021.github.io/
Graph-to-3D: End-to-End Generation and Manipulation of 3D Scenes Using Scene Graphs
Aug 19, 2021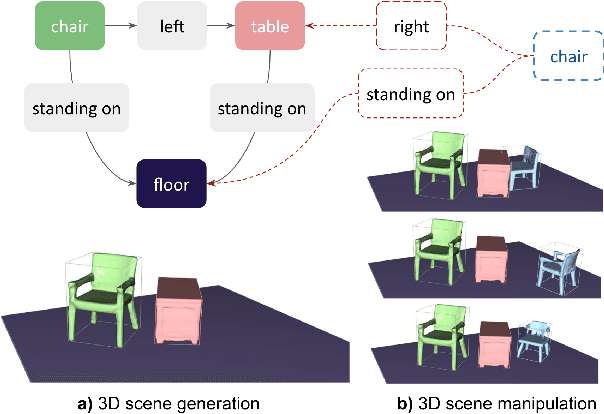
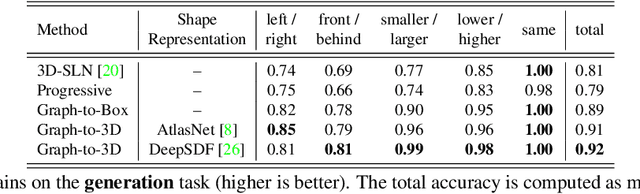
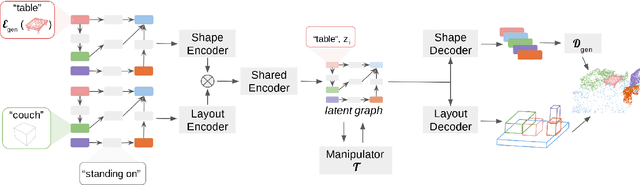
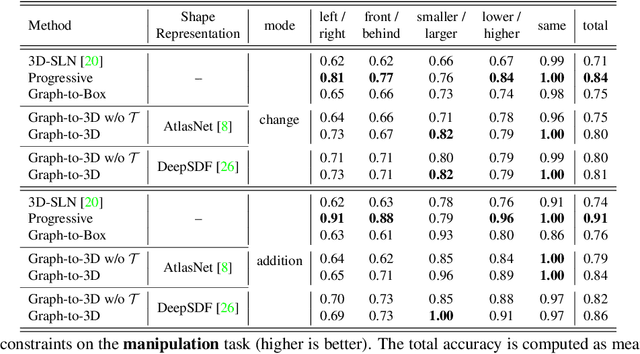
Controllable scene synthesis consists of generating 3D information that satisfy underlying specifications. Thereby, these specifications should be abstract, i.e. allowing easy user interaction, whilst providing enough interface for detailed control. Scene graphs are representations of a scene, composed of objects (nodes) and inter-object relationships (edges), proven to be particularly suited for this task, as they allow for semantic control on the generated content. Previous works tackling this task often rely on synthetic data, and retrieve object meshes, which naturally limits the generation capabilities. To circumvent this issue, we instead propose the first work that directly generates shapes from a scene graph in an end-to-end manner. In addition, we show that the same model supports scene modification, using the respective scene graph as interface. Leveraging Graph Convolutional Networks (GCN) we train a variational Auto-Encoder on top of the object and edge categories, as well as 3D shapes and scene layouts, allowing latter sampling of new scenes and shapes.