 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINTERACT-CMIL: Multi-Task Shared Learning and Inter-Task Consistency for Conjunctival Melanocytic Intraepithelial Lesion Grading
Dec 27, 2025Accurate grading of Conjunctival Melanocytic Intraepithelial Lesions (CMIL) is essential for treatment and melanoma prediction but remains difficult due to subtle morphological cues and interrelated diagnostic criteria. We introduce INTERACT-CMIL, a multi-head deep learning framework that jointly predicts five histopathological axes; WHO4, WHO5, horizontal spread, vertical spread, and cytologic atypia, through Shared Feature Learning with Combinatorial Partial Supervision and an Inter-Dependence Loss enforcing cross-task consistency. Trained and evaluated on a newly curated, multi-center dataset of 486 expert-annotated conjunctival biopsy patches from three university hospitals, INTERACT-CMIL achieves consistent improvements over CNN and foundation-model (FM) baselines, with relative macro F1 gains up to 55.1% (WHO4) and 25.0% (vertical spread). The framework provides coherent, interpretable multi-criteria predictions aligned with expert grading, offering a reproducible computational benchmark for CMIL diagnosis and a step toward standardized digital ocular pathology.
Stress-Aware Resilient Neural Training
Jul 31, 2025This paper introduces Stress-Aware Learning, a resilient neural training paradigm in which deep neural networks dynamically adjust their optimization behavior - whether under stable training regimes or in settings with uncertain dynamics - based on the concept of Temporary (Elastic) and Permanent (Plastic) Deformation, inspired by structural fatigue in materials science. To instantiate this concept, we propose Plastic Deformation Optimizer, a stress-aware mechanism that injects adaptive noise into model parameters whenever an internal stress signal - reflecting stagnation in training loss and accuracy - indicates persistent optimization difficulty. This enables the model to escape sharp minima and converge toward flatter, more generalizable regions of the loss landscape. Experiments across six architectures, four optimizers, and seven vision benchmarks demonstrate improved robustness and generalization with minimal computational overhead. The code and 3D visuals will be available on GitHub: https://github.com/Stress-Aware-Learning/SAL.
Unit-Based Histopathology Tissue Segmentation via Multi-Level Feature Representation
Jul 16, 2025We propose UTS, a unit-based tissue segmentation framework for histopathology that classifies each fixed-size 32 * 32 tile, rather than each pixel, as the segmentation unit. This approach reduces annotation effort and improves computational efficiency without compromising accuracy. To implement this approach, we introduce a Multi-Level Vision Transformer (L-ViT), which benefits the multi-level feature representation to capture both fine-grained morphology and global tissue context. Trained to segment breast tissue into three categories (infiltrating tumor, non-neoplastic stroma, and fat), UTS supports clinically relevant tasks such as tumor-stroma quantification and surgical margin assessment. Evaluated on 386,371 tiles from 459 H&E-stained regions, it outperforms U-Net variants and transformer-based baselines. Code and Dataset will be available at GitHub.
VeLU: Variance-enhanced Learning Unit for Deep Neural Networks
Apr 21, 2025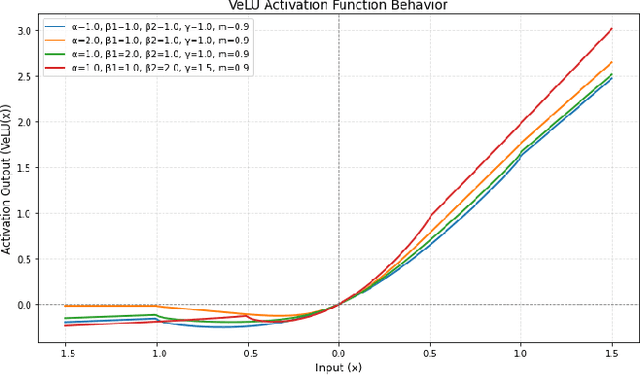
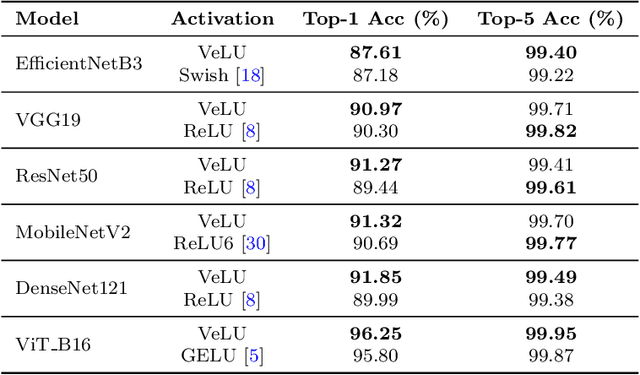
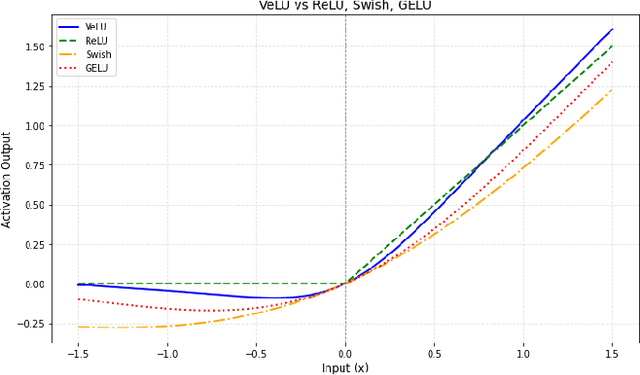
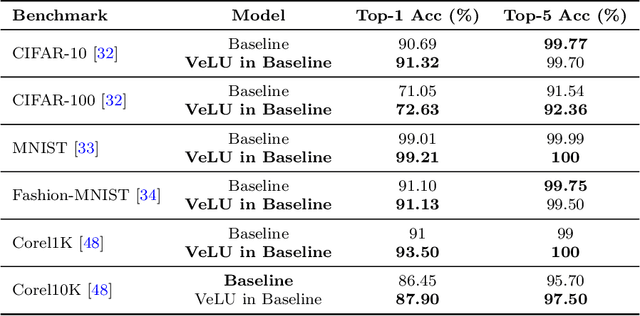
Activation functions are fundamental in deep neural networks and directly impact gradient flow, optimization stability, and generalization. Although ReLU remains standard because of its simplicity, it suffers from vanishing gradients and lacks adaptability. Alternatives like Swish and GELU introduce smooth transitions, but fail to dynamically adjust to input statistics. We propose VeLU, a Variance-enhanced Learning Unit as an activation function that dynamically scales based on input variance by integrating ArcTan-Sin transformations and Wasserstein-2 regularization, effectively mitigating covariate shifts and stabilizing optimization. Extensive experiments on ViT_B16, VGG19, ResNet50, DenseNet121, MobileNetV2, and EfficientNetB3 confirm VeLU's superiority over ReLU, ReLU6, Swish, and GELU on six vision benchmarks. The codes of VeLU are publicly available on GitHub.
Latent Drifting in Diffusion Models for Counterfactual Medical Image Synthesis
Dec 30, 2024



Scaling by training on large datasets has been shown to enhance the quality and fidelity of image generation and manipulation with diffusion models; however, such large datasets are not always accessible in medical imaging due to cost and privacy issues, which contradicts one of the main applications of such models to produce synthetic samples where real data is scarce. Also, finetuning on pre-trained general models has been a challenge due to the distribution shift between the medical domain and the pre-trained models. Here, we propose Latent Drift (LD) for diffusion models that can be adopted for any fine-tuning method to mitigate the issues faced by the distribution shift or employed in inference time as a condition. Latent Drifting enables diffusion models to be conditioned for medical images fitted for the complex task of counterfactual image generation, which is crucial to investigate how parameters such as gender, age, and adding or removing diseases in a patient would alter the medical images. We evaluate our method on three public longitudinal benchmark datasets of brain MRI and chest X-rays for counterfactual image generation. Our results demonstrate significant performance gains in various scenarios when combined with different fine-tuning schemes. The source code of this work will be publicly released upon its acceptance.
Conformable Convolution for Topologically Aware Learning of Complex Anatomical Structures
Dec 29, 2024While conventional computer vision emphasizes pixel-level and feature-based objectives, medical image analysis of intricate biological structures necessitates explicit representation of their complex topological properties. Despite their successes, deep learning models often struggle to accurately capture the connectivity and continuity of fine, sometimes pixel-thin, yet critical structures due to their reliance on implicit learning from data. Such shortcomings can significantly impact the reliability of analysis results and hinder clinical decision-making. To address this challenge, we introduce Conformable Convolution, a novel convolutional layer designed to explicitly enforce topological consistency. Conformable Convolution learns adaptive kernel offsets that preferentially focus on regions of high topological significance within an image. This prioritization is guided by our proposed Topological Posterior Generator (TPG) module, which leverages persistent homology. The TPG module identifies key topological features and guides the convolutional layers by applying persistent homology to feature maps transformed into cubical complexes. Our proposed modules are architecture-agnostic, enabling them to be integrated seamlessly into various architectures. We showcase the effectiveness of our framework in the segmentation task, where preserving the interconnectedness of structures is critical. Experimental results on three diverse datasets demonstrate that our framework effectively preserves the topology in the segmentation downstream task, both quantitatively and qualitatively.
VISAGE: Video Synthesis using Action Graphs for Surgery
Oct 23, 2024



Surgical data science (SDS) is a field that analyzes patient data before, during, and after surgery to improve surgical outcomes and skills. However, surgical data is scarce, heterogeneous, and complex, which limits the applicability of existing machine learning methods. In this work, we introduce the novel task of future video generation in laparoscopic surgery. This task can augment and enrich the existing surgical data and enable various applications, such as simulation, analysis, and robot-aided surgery. Ultimately, it involves not only understanding the current state of the operation but also accurately predicting the dynamic and often unpredictable nature of surgical procedures. Our proposed method, VISAGE (VIdeo Synthesis using Action Graphs for Surgery), leverages the power of action scene graphs to capture the sequential nature of laparoscopic procedures and utilizes diffusion models to synthesize temporally coherent video sequences. VISAGE predicts the future frames given only a single initial frame, and the action graph triplets. By incorporating domain-specific knowledge through the action graph, VISAGE ensures the generated videos adhere to the expected visual and motion patterns observed in real laparoscopic procedures. The results of our experiments demonstrate high-fidelity video generation for laparoscopy procedures, which enables various applications in SDS.
PRISM: Progressive Restoration for Scene Graph-based Image Manipulation
Nov 03, 2023
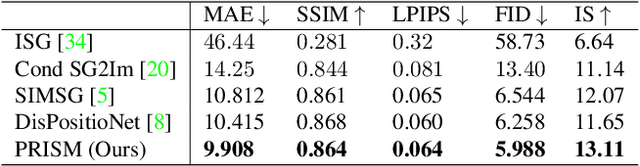
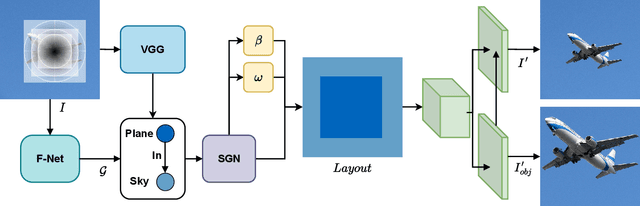

Scene graphs have emerged as accurate descriptive priors for image generation and manipulation tasks, however, their complexity and diversity of the shapes and relations of objects in data make it challenging to incorporate them into the models and generate high-quality results. To address these challenges, we propose PRISM, a novel progressive multi-head image manipulation approach to improve the accuracy and quality of the manipulated regions in the scene. Our image manipulation framework is trained using an end-to-end denoising masked reconstruction proxy task, where the masked regions are progressively unmasked from the outer regions to the inner part. We take advantage of the outer part of the masked area as they have a direct correlation with the context of the scene. Moreover, our multi-head architecture simultaneously generates detailed object-specific regions in addition to the entire image to produce higher-quality images. Our model outperforms the state-of-the-art methods in the semantic image manipulation task on the CLEVR and Visual Genome datasets. Our results demonstrate the potential of our approach for enhancing the quality and precision of scene graph-based image manipulation.
AutoPaint: A Self-Inpainting Method for Unsupervised Anomaly Detection
May 21, 2023Robust and accurate detection and segmentation of heterogenous tumors appearing in different anatomical organs with supervised methods require large-scale labeled datasets covering all possible types of diseases. Due to the unavailability of such rich datasets and the high cost of annotations, unsupervised anomaly detection (UAD) methods have been developed aiming to detect the pathologies as deviation from the normality by utilizing the unlabeled healthy image data. However, developed UAD models are often trained with an incomplete distribution of healthy anatomies and have difficulties in preserving anatomical constraints. This work intends to, first, propose a robust inpainting model to learn the details of healthy anatomies and reconstruct high-resolution images by preserving anatomical constraints. Second, we propose an autoinpainting pipeline to automatically detect tumors, replace their appearance with the learned healthy anatomies, and based on that segment the tumoral volumes in a purely unsupervised fashion. Three imaging datasets, including PET, CT, and PET-CT scans of lung tumors and head and neck tumors, are studied as benchmarks for evaluation. Experimental results demonstrate the significant superiority of the proposed method over a wide range of state-of-the-art UAD methods. Moreover, the unsupervised method we propose produces comparable results to a robust supervised segmentation method when applied to multimodal images.
DIAMANT: Dual Image-Attention Map Encoders For Medical Image Segmentation
Apr 28, 2023



Although purely transformer-based architectures showed promising performance in many computer vision tasks, many hybrid models consisting of CNN and transformer blocks are introduced to fit more specialized tasks. Nevertheless, despite the performance gain of both pure and hybrid transformer-based architectures compared to CNNs in medical imaging segmentation, their high training cost and complexity make it challenging to use them in real scenarios. In this work, we propose simple architectures based on purely convolutional layers, and show that by just taking advantage of the attention map visualizations obtained from a self-supervised pretrained vision transformer network (e.g., DINO) one can outperform complex transformer-based networks with much less computation costs. The proposed architecture is composed of two encoder branches with the original image as input in one branch and the attention map visualizations of the same image from multiple self-attention heads from a pre-trained DINO model (as multiple channels) in the other branch. The results of our experiments on two publicly available medical imaging datasets show that the proposed pipeline outperforms U-Net and the state-of-the-art medical image segmentation models.