 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasetNeRF: Efficient 3D-aware Data Factory with Generative Radiance Fields
Nov 18, 2023
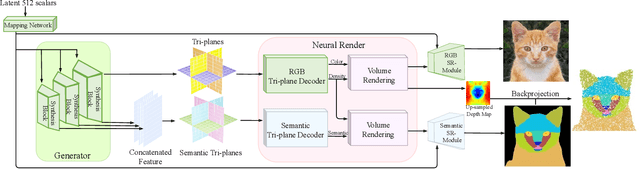

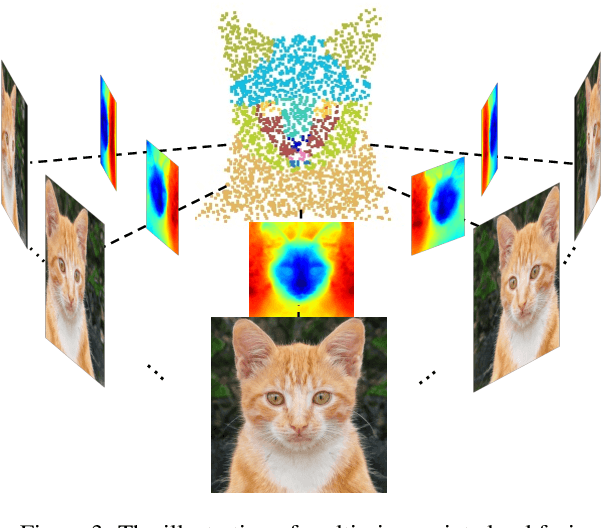
Progress in 3D computer vision tasks demands a huge amount of data, yet annotating multi-view images with 3D-consistent annotations, or point clouds with part segmentation is both time-consuming and challenging. This paper introduces DatasetNeRF, a novel approach capable of generating infinite, high-quality 3D-consistent 2D annotations alongside 3D point cloud segmentations, while utilizing minimal 2D human-labeled annotations. Specifically, we leverage the strong semantic prior within a 3D generative model to train a semantic decoder, requiring only a handful of fine-grained labeled samples. Once trained, the decoder efficiently generalizes across the latent space, enabling the generation of infinite data. The generated data is applicable across various computer vision tasks, including video segmentation and 3D point cloud segmentation. Our approach not only surpasses baseline models in segmentation quality, achieving superior 3D consistency and segmentation precision on individual images, but also demonstrates versatility by being applicable to both articulated and non-articulated generative models. Furthermore, we explore applications stemming from our approach, such as 3D-aware semantic editing and 3D inversion.
SceneGenie: Scene Graph Guided Diffusion Models for Image Synthesis
Apr 28, 2023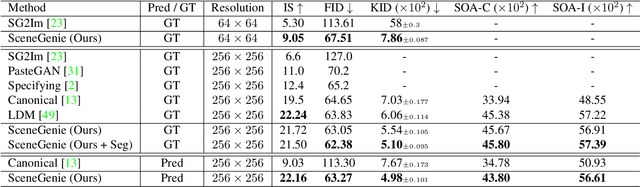
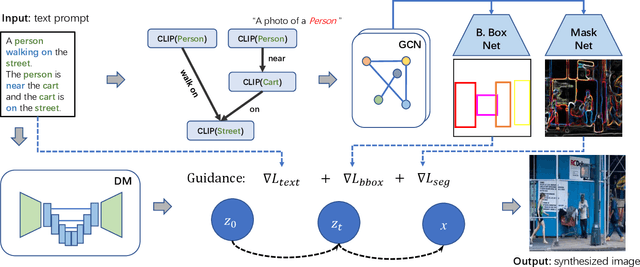
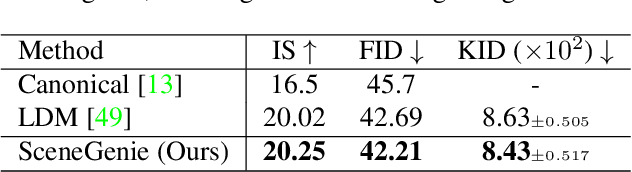
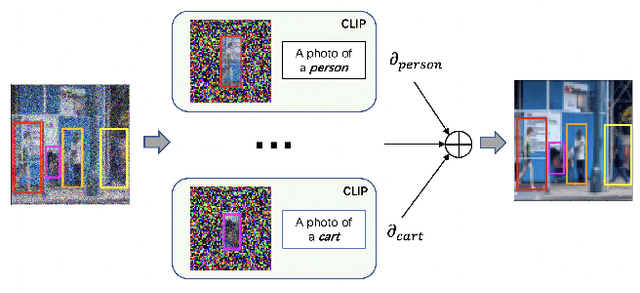
Text-conditioned image generation has made significant progress in recent years with generative adversarial networks and more recently, diffusion models. While diffusion models conditioned on text prompts have produced impressive and high-quality images, accurately representing complex text prompts such as the number of instances of a specific object remains challenging. To address this limitation, we propose a novel guidance approach for the sampling process in the diffusion model that leverages bounding box and segmentation map information at inference time without additional training data. Through a novel loss in the sampling process, our approach guides the model with semantic features from CLIP embeddings and enforces geometric constraints, leading to high-resolution images that accurately represent the scene. To obtain bounding box and segmentation map information, we structure the text prompt as a scene graph and enrich the nodes with CLIP embeddings. Our proposed model achieves state-of-the-art performance on two public benchmarks for image generation from scene graphs, surpassing both scene graph to image and text-based diffusion models in various metrics. Our results demonstrate the effectiveness of incorporating bounding box and segmentation map guidance in the diffusion model sampling process for more accurate text-to-image generation.
Deep Keyphrase Generation
Sep 18, 2018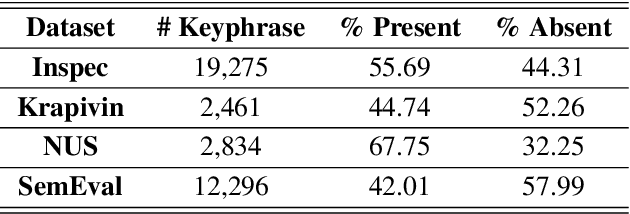

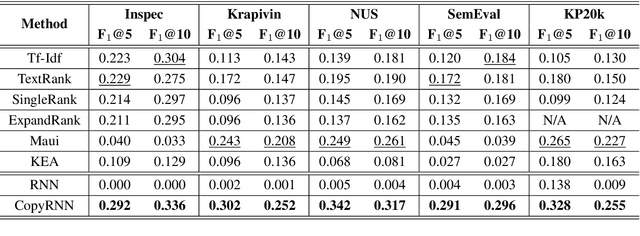
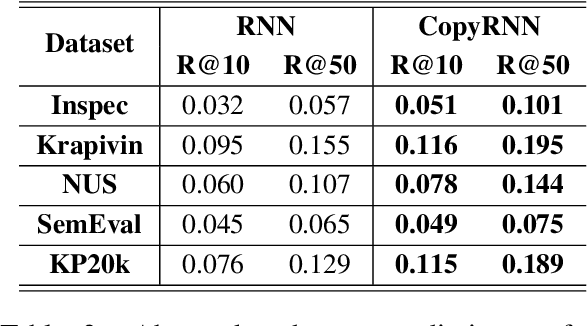
Keyphrase provides highly-summative information that can be effectively used for understanding, organizing and retrieving text content. Though previous studies have provided many workable solutions for automated keyphrase extraction, they commonly divided the to-be-summarized content into multiple text chunks, then ranked and selected the most meaningful ones. These approaches could neither identify keyphrases that do not appear in the text, nor capture the real semantic meaning behind the text. We propose a generative model for keyphrase prediction with an encoder-decoder framework, which can effectively overcome the above drawbacks. We name it as deep keyphrase generation since it attempts to capture the deep semantic meaning of the content with a deep learning method. Empirical analysis on six datasets demonstrates that our proposed model not only achieves a significant performance boost on extracting keyphrases that appear in the source text, but also can generate absent keyphrases based on the semantic meaning of the text. Code and dataset are available at https://github.com/memray/seq2seq-keyphrase.