 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAHOY! Animatable Humans under Occlusion from YouTube Videos with Gaussian Splatting and Video Diffusion Priors
Mar 18, 2026We present AHOY, a method for reconstructing complete, animatable 3D Gaussian avatars from in-the-wild monocular video despite heavy occlusion. Existing methods assume unoccluded input-a fully visible subject, often in a canonical pose-excluding the vast majority of real-world footage where people are routinely occluded by furniture, objects, or other people. Reconstructing from such footage poses fundamental challenges: large body regions may never be observed, and multi-view supervision per pose is unavailable. We address these challenges with four contributions: (i) a hallucination-as-supervision pipeline that uses identity-finetuned diffusion models to generate dense supervision for previously unobserved body regions; (ii) a two-stage canonical-to-pose-dependent architecture that bootstraps from sparse observations to full pose-dependent Gaussian maps; (iii) a map-pose/LBS-pose decoupling that absorbs multi-view inconsistencies from the generated data; (iv) a head/body split supervision strategy that preserves facial identity. We evaluate on YouTube videos and on multi-view capture data with significant occlusion and demonstrate state-of-the-art reconstruction quality. We also demonstrate that the resulting avatars are robust enough to be animated with novel poses and composited into 3DGS scenes captured using cell-phone video. Our project page is available at https://miraymen.github.io/ahoy/
Animated 3DGS Avatars in Diverse Scenes with Consistent Lighting and Shadows
Jan 04, 2026We present a method for consistent lighting and shadows when animated 3D Gaussian Splatting (3DGS) avatars interact with 3DGS scenes or with dynamic objects inserted into otherwise static scenes. Our key contribution is Deep Gaussian Shadow Maps (DGSM), a modern analogue of the classical shadow mapping algorithm tailored to the volumetric 3DGS representation. Building on the classic deep shadow mapping idea, we show that 3DGS admits closed form light accumulation along light rays, enabling volumetric shadow computation without meshing. For each estimated light, we tabulate transmittance over concentric radial shells and store them in octahedral atlases, which modern GPUs can sample in real time per query to attenuate affected scene Gaussians and thus cast and receive shadows consistently. To relight moving avatars, we approximate the local environment illumination with HDRI probes represented in a spherical harmonic (SH) basis and apply a fast per Gaussian radiance transfer, avoiding explicit BRDF estimation or offline optimization. We demonstrate environment consistent lighting for avatars from AvatarX and ActorsHQ, composited into ScanNet++, DL3DV, and SuperSplat scenes, and show interactions with inserted objects. Across single and multi avatar settings, DGSM and SH relighting operate fully in the volumetric 3DGS representation, yielding coherent shadows and relighting while avoiding meshing.
AHA! Animating Human Avatars in Diverse Scenes with Gaussian Splatting
Nov 13, 2025We present a novel framework for animating humans in 3D scenes using 3D Gaussian Splatting (3DGS), a neural scene representation that has recently achieved state-of-the-art photorealistic results for novel-view synthesis but remains under-explored for human-scene animation and interaction. Unlike existing animation pipelines that use meshes or point clouds as the underlying 3D representation, our approach introduces the use of 3DGS as the 3D representation to the problem of animating humans in scenes. By representing humans and scenes as Gaussians, our approach allows for geometry-consistent free-viewpoint rendering of humans interacting with 3D scenes. Our key insight is that the rendering can be decoupled from the motion synthesis and each sub-problem can be addressed independently, without the need for paired human-scene data. Central to our method is a Gaussian-aligned motion module that synthesizes motion without explicit scene geometry, using opacity-based cues and projected Gaussian structures to guide human placement and pose alignment. To ensure natural interactions, we further propose a human-scene Gaussian refinement optimization that enforces realistic contact and navigation. We evaluate our approach on scenes from Scannet++ and the SuperSplat library, and on avatars reconstructed from sparse and dense multi-view human capture. Finally, we demonstrate that our framework allows for novel applications such as geometry-consistent free-viewpoint rendering of edited monocular RGB videos with new animated humans, showcasing the unique advantage of 3DGS for monocular video-based human animation.
GASPACHO: Gaussian Splatting for Controllable Humans and Objects
Mar 12, 2025We present GASPACHO: a method for generating photorealistic controllable renderings of human-object interactions. Given a set of multi-view RGB images of human-object interactions, our method reconstructs animatable templates of the human and object as separate sets of Gaussians simultaneously. Different from existing work, which focuses on human reconstruction and ignores objects as background, our method explicitly reconstructs both humans and objects, thereby allowing for controllable renderings of novel human object interactions in different poses from novel-camera viewpoints. During reconstruction, we constrain the Gaussians that generate rendered images to be a linear function of a set of canonical Gaussians. By simply changing the parameters of the linear deformation functions after training, our method can generate renderings of novel human-object interaction in novel poses from novel camera viewpoints. We learn the 3D Gaussian properties of the canonical Gaussians on the underlying 2D manifold of the canonical human and object templates. This in turns requires a canonical object template with a fixed UV unwrapping. To define such an object template, we use a feature based representation to track the object across the multi-view sequence. We further propose an occlusion aware photometric loss that allows for reconstructions under significant occlusions. Several experiments on two human-object datasets - BEHAVE and DNA-Rendering - demonstrate that our method allows for high-quality reconstruction of human and object templates under significant occlusion and the synthesis of controllable renderings of novel human-object interactions in novel human poses from novel camera views.
Generating Continual Human Motion in Diverse 3D Scenes
Apr 11, 2023We introduce a method to synthesize animator guided human motion across 3D scenes. Given a set of sparse (3 or 4) joint locations (such as the location of a person's hand and two feet) and a seed motion sequence in a 3D scene, our method generates a plausible motion sequence starting from the seed motion while satisfying the constraints imposed by the provided keypoints. We decompose the continual motion synthesis problem into walking along paths and transitioning in and out of the actions specified by the keypoints, which enables long generation of motions that satisfy scene constraints without explicitly incorporating scene information. Our method is trained only using scene agnostic mocap data. As a result, our approach is deployable across 3D scenes with various geometries. For achieving plausible continual motion synthesis without drift, our key contribution is to generate motion in a goal-centric canonical coordinate frame where the next immediate target is situated at the origin. Our model can generate long sequences of diverse actions such as grabbing, sitting and leaning chained together in arbitrary order, demonstrated on scenes of varying geometry: HPS, Replica, Matterport, ScanNet and scenes represented using NeRFs. Several experiments demonstrate that our method outperforms existing methods that navigate paths in 3D scenes.
Human POSEitioning System (HPS): 3D Human Pose Estimation and Self-localization in Large Scenes from Body-Mounted Sensors
Mar 31, 2021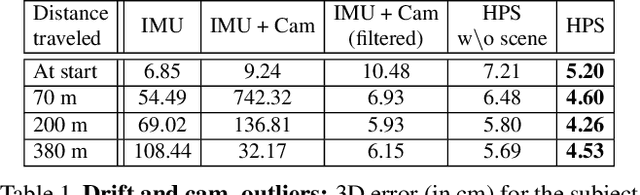
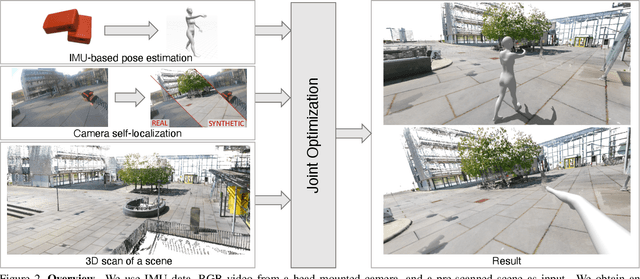
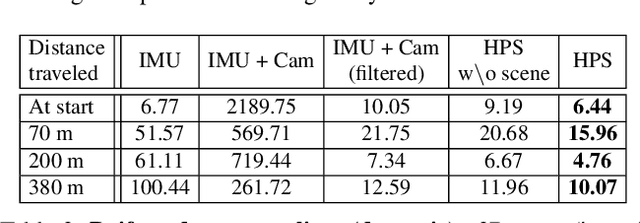
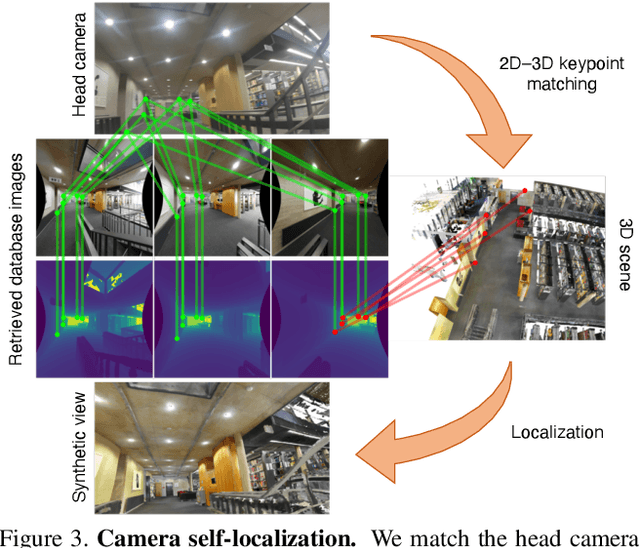
We introduce (HPS) Human POSEitioning System, a method to recover the full 3D pose of a human registered with a 3D scan of the surrounding environment using wearable sensors. Using IMUs attached at the body limbs and a head mounted camera looking outwards, HPS fuses camera based self-localization with IMU-based human body tracking. The former provides drift-free but noisy position and orientation estimates while the latter is accurate in the short-term but subject to drift over longer periods of time. We show that our optimization-based integration exploits the benefits of the two, resulting in pose accuracy free of drift. Furthermore, we integrate 3D scene constraints into our optimization, such as foot contact with the ground, resulting in physically plausible motion. HPS complements more common third-person-based 3D pose estimation methods. It allows capturing larger recording volumes and longer periods of motion, and could be used for VR/AR applications where humans interact with the scene without requiring direct line of sight with an external camera, or to train agents that navigate and interact with the environment based on first-person visual input, like real humans. With HPS, we recorded a dataset of humans interacting with large 3D scenes (300-1000 sq.m) consisting of 7 subjects and more than 3 hours of diverse motion. The dataset, code and video will be available on the project page: http://virtualhumans.mpi-inf.mpg.de/hps/ .
Neural Unsigned Distance Fields for Implicit Function Learning
Oct 26, 2020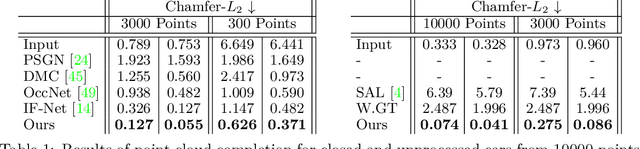
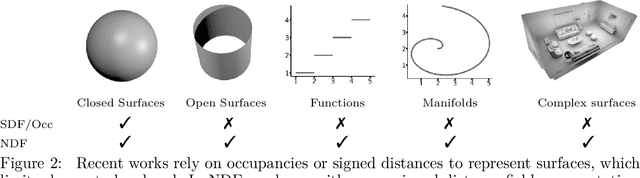
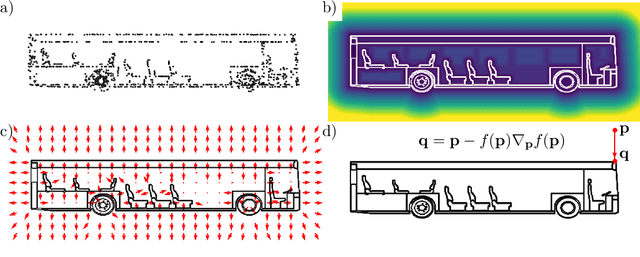

In this work we target a learnable output representation that allows continuous, high resolution outputs of arbitrary shape. Recent works represent 3D surfaces implicitly with a Neural Network, thereby breaking previous barriers in resolution, and ability to represent diverse topologies. However, neural implicit representations are limited to closed surfaces, which divide the space into inside and outside. Many real world objects such as walls of a scene scanned by a sensor, clothing, or a car with inner structures are not closed. This constitutes a significant barrier, in terms of data pre-processing (objects need to be artificially closed creating artifacts), and the ability to output open surfaces. In this work, we propose Neural Distance Fields (NDF), a neural network based model which predicts the unsigned distance field for arbitrary 3D shapes given sparse point clouds. NDF represent surfaces at high resolutions as prior implicit models, but do not require closed surface data, and significantly broaden the class of representable shapes in the output. NDF allow to extract the surface as very dense point clouds and as meshes. We also show that NDF allow for surface normal calculation and can be rendered using a slight modification of sphere tracing. We find NDF can be used for multi-target regression (multiple outputs for one input) with techniques that have been exclusively used for rendering in graphics. Experiments on ShapeNet show that NDF, while simple, is the state-of-the art, and allows to reconstruct shapes with inner structures, such as the chairs inside a bus. Notably, we show that NDF are not restricted to 3D shapes, and can approximate more general open surfaces such as curves, manifolds, and functions. Code is available for research at https://virtualhumans.mpi-inf.mpg.de/ndf/.
* Neural Information Processing Systems (NeurIPS) 2020
Learning to Transfer Texture from Clothing Images to 3D Humans
Mar 30, 2020
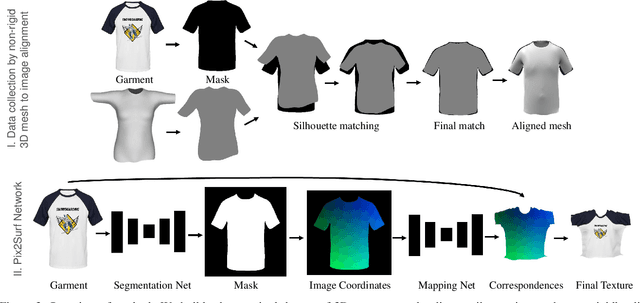


In this paper, we present a simple yet effective method to automatically transfer textures of clothing images (front and back) to 3D garments worn on top SMPL, in real time. We first automatically compute training pairs of images with aligned 3D garments using a custom non-rigid 3D to 2D registration method, which is accurate but slow. Using these pairs, we learn a mapping from pixels to the 3D garment surface. Our idea is to learn dense correspondences from garment image silhouettes to a 2D-UV map of a 3D garment surface using shape information alone, completely ignoring texture, which allows us to generalize to the wide range of web images. Several experiments demonstrate that our model is more accurate than widely used baselines such as thin-plate-spline warping and image-to-image translation networks while being orders of magnitude faster. Our model opens the door for applications such as virtual try-on, and allows for generation of 3D humans with varied textures which is necessary for learning.