 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2P-Bridge: Diffusion Bridges for 3D Point Cloud Denoising
Aug 29, 2024



In this work, we tackle the task of point cloud denoising through a novel framework that adapts Diffusion Schr\"odinger bridges to points clouds. Unlike previous approaches that predict point-wise displacements from point features or learned noise distributions, our method learns an optimal transport plan between paired point clouds. Experiments on object datasets like PU-Net and real-world datasets such as ScanNet++ and ARKitScenes show that P2P-Bridge achieves significant improvements over existing methods. While our approach demonstrates strong results using only point coordinates, we also show that incorporating additional features, such as color information or point-wise DINOv2 features, further enhances the performance. Code and pretrained models are available at https://p2p-bridge.github.io.
Splat-SLAM: Globally Optimized RGB-only SLAM with 3D Gaussians
May 26, 2024



3D Gaussian Splatting has emerged as a powerful representation of geometry and appearance for RGB-only dense Simultaneous Localization and Mapping (SLAM), as it provides a compact dense map representation while enabling efficient and high-quality map rendering. However, existing methods show significantly worse reconstruction quality than competing methods using other 3D representations, e.g. neural points clouds, since they either do not employ global map and pose optimization or make use of monocular depth. In response, we propose the first RGB-only SLAM system with a dense 3D Gaussian map representation that utilizes all benefits of globally optimized tracking by adapting dynamically to keyframe pose and depth updates by actively deforming the 3D Gaussian map. Moreover, we find that refining the depth updates in inaccurate areas with a monocular depth estimator further improves the accuracy of the 3D reconstruction. Our experiments on the Replica, TUM-RGBD, and ScanNet datasets indicate the effectiveness of globally optimized 3D Gaussians, as the approach achieves superior or on par performance with existing RGB-only SLAM methods methods in tracking, mapping and rendering accuracy while yielding small map sizes and fast runtimes. The source code is available at https://github.com/eriksandstroem/Splat-SLAM.
OpenNeRF: Open Set 3D Neural Scene Segmentation with Pixel-Wise Features and Rendered Novel Views
Apr 04, 2024
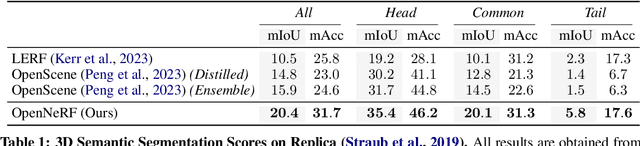
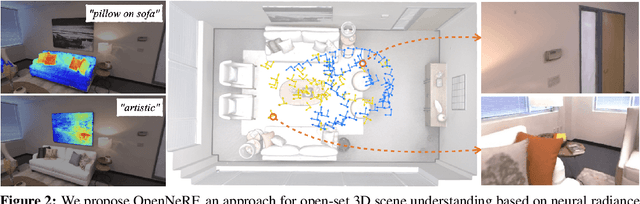
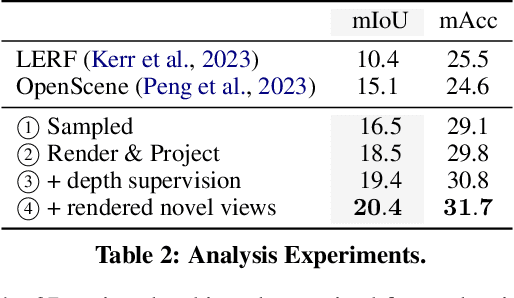
Large visual-language models (VLMs), like CLIP, enable open-set image segmentation to segment arbitrary concepts from an image in a zero-shot manner. This goes beyond the traditional closed-set assumption, i.e., where models can only segment classes from a pre-defined training set. More recently, first works on open-set segmentation in 3D scenes have appeared in the literature. These methods are heavily influenced by closed-set 3D convolutional approaches that process point clouds or polygon meshes. However, these 3D scene representations do not align well with the image-based nature of the visual-language models. Indeed, point cloud and 3D meshes typically have a lower resolution than images and the reconstructed 3D scene geometry might not project well to the underlying 2D image sequences used to compute pixel-aligned CLIP features. To address these challenges, we propose OpenNeRF which naturally operates on posed images and directly encodes the VLM features within the NeRF. This is similar in spirit to LERF, however our work shows that using pixel-wise VLM features (instead of global CLIP features) results in an overall less complex architecture without the need for additional DINO regularization. Our OpenNeRF further leverages NeRF's ability to render novel views and extract open-set VLM features from areas that are not well observed in the initial posed images. For 3D point cloud segmentation on the Replica dataset, OpenNeRF outperforms recent open-vocabulary methods such as LERF and OpenScene by at least +4.9 mIoU.
* ICLR 2024, Project page: https://opennerf.github.io
RadSplat: Radiance Field-Informed Gaussian Splatting for Robust Real-Time Rendering with 900+ FPS
Mar 20, 2024



Recent advances in view synthesis and real-time rendering have achieved photorealistic quality at impressive rendering speeds. While Radiance Field-based methods achieve state-of-the-art quality in challenging scenarios such as in-the-wild captures and large-scale scenes, they often suffer from excessively high compute requirements linked to volumetric rendering. Gaussian Splatting-based methods, on the other hand, rely on rasterization and naturally achieve real-time rendering but suffer from brittle optimization heuristics that underperform on more challenging scenes. In this work, we present RadSplat, a lightweight method for robust real-time rendering of complex scenes. Our main contributions are threefold. First, we use radiance fields as a prior and supervision signal for optimizing point-based scene representations, leading to improved quality and more robust optimization. Next, we develop a novel pruning technique reducing the overall point count while maintaining high quality, leading to smaller and more compact scene representations with faster inference speeds. Finally, we propose a novel test-time filtering approach that further accelerates rendering and allows to scale to larger, house-sized scenes. We find that our method enables state-of-the-art synthesis of complex captures at 900+ FPS.
Incremental 3D Semantic Scene Graph Prediction from RGB Sequences
May 06, 2023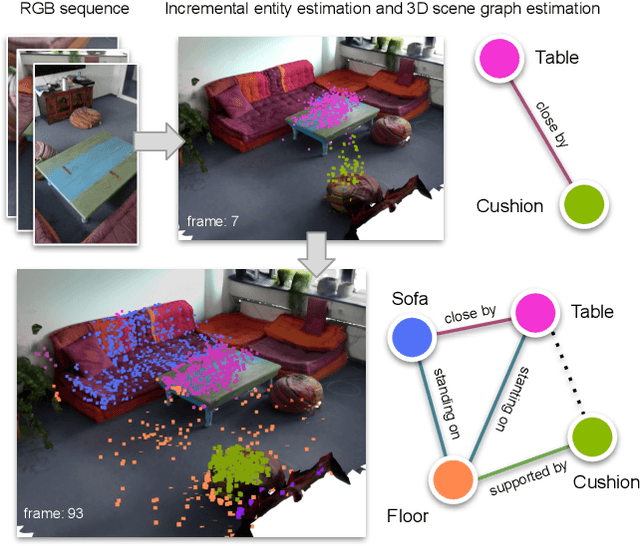
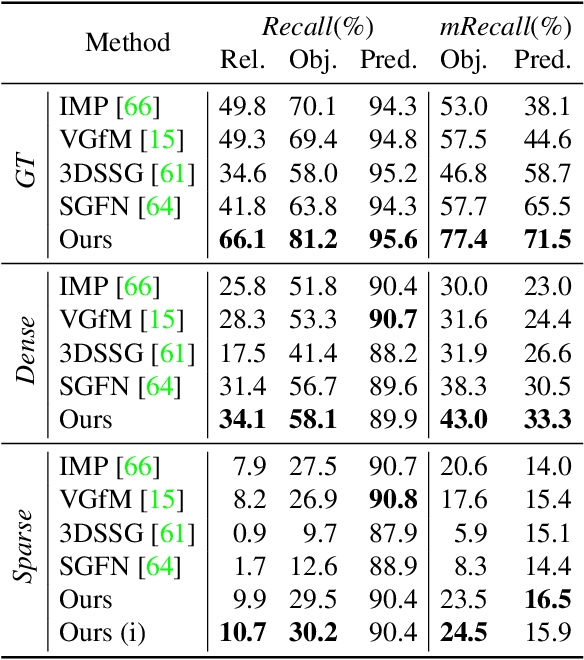

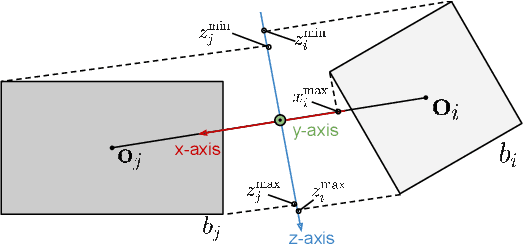
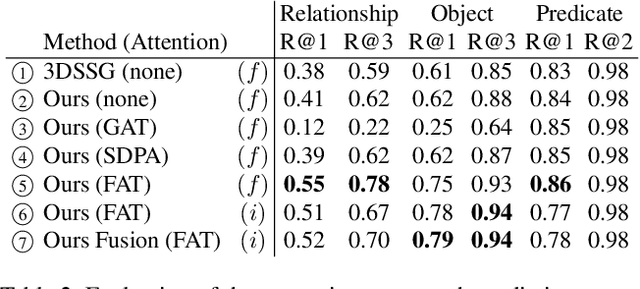
3D semantic scene graphs are a powerful holistic representation as they describe the individual objects and depict the relation between them. They are compact high-level graphs that enable many tasks requiring scene reasoning. In real-world settings, existing 3D estimation methods produce robust predictions that mostly rely on dense inputs. In this work, we propose a real-time framework that incrementally builds a consistent 3D semantic scene graph of a scene given an RGB image sequence. Our method consists of a novel incremental entity estimation pipeline and a scene graph prediction network. The proposed pipeline simultaneously reconstructs a sparse point map and fuses entity estimation from the input images. The proposed network estimates 3D semantic scene graphs with iterative message passing using multi-view and geometric features extracted from the scene entities. Extensive experiments on the 3RScan dataset show the effectiveness of the proposed method in this challenging task, outperforming state-of-the-art approaches.
NEWTON: Neural View-Centric Mapping for On-the-Fly Large-Scale SLAM
Mar 29, 2023



Neural field-based 3D representations have recently been adopted in many areas including SLAM systems. Current neural SLAM or online mapping systems lead to impressive results in the presence of simple captures, but they rely on a world-centric map representation as only a single neural field model is used. To define such a world-centric representation, accurate and static prior information about the scene, such as its boundaries and initial camera poses, are required. However, in real-time and on-the-fly scene capture applications, this prior knowledge cannot be assumed as fixed or static, since it dynamically changes and it is subject to significant updates based on run-time observations. Particularly in the context of large-scale mapping, significant camera pose drift is inevitable, necessitating the correction via loop closure. To overcome this limitation, we propose NEWTON, a view-centric mapping method that dynamically constructs neural fields based on run-time observation. In contrast to prior works, our method enables camera pose updates using loop closures and scene boundary updates by representing the scene with multiple neural fields, where each is defined in a local coordinate system of a selected keyframe. The experimental results demonstrate the superior performance of our method over existing world-centric neural field-based SLAM systems, in particular for large-scale scenes subject to camera pose updates.
SceneGraphFusion: Incremental 3D Scene Graph Prediction from RGB-D Sequences
Mar 31, 2021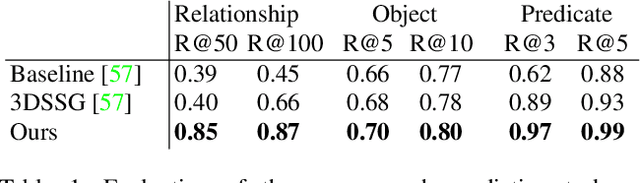
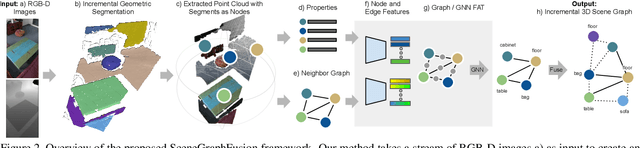
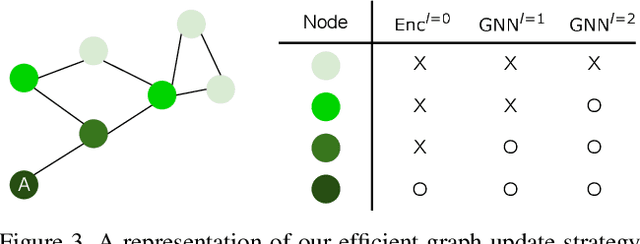
Scene graphs are a compact and explicit representation successfully used in a variety of 2D scene understanding tasks. This work proposes a method to incrementally build up semantic scene graphs from a 3D environment given a sequence of RGB-D frames. To this end, we aggregate PointNet features from primitive scene components by means of a graph neural network. We also propose a novel attention mechanism well suited for partial and missing graph data present in such an incremental reconstruction scenario. Although our proposed method is designed to run on submaps of the scene, we show it also transfers to entire 3D scenes. Experiments show that our approach outperforms 3D scene graph prediction methods by a large margin and its accuracy is on par with other 3D semantic and panoptic segmentation methods while running at 35 Hz.
A Divide et Impera Approach for 3D Shape Reconstruction from Multiple Views
Nov 18, 2020
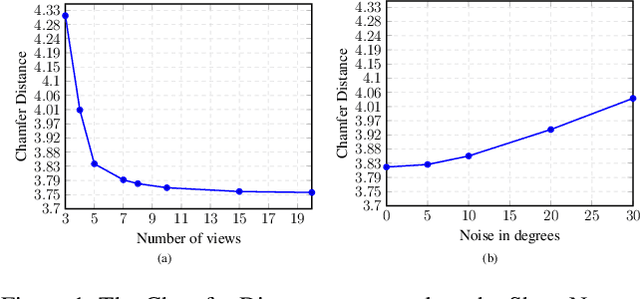
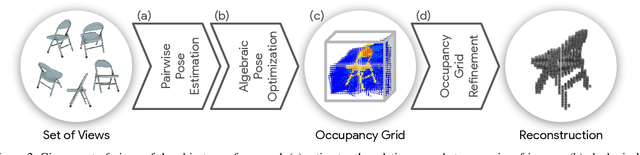

Estimating the 3D shape of an object from a single or multiple images has gained popularity thanks to the recent breakthroughs powered by deep learning. Most approaches regress the full object shape in a canonical pose, possibly extrapolating the occluded parts based on the learned priors. However, their viewpoint invariant technique often discards the unique structures visible from the input images. In contrast, this paper proposes to rely on viewpoint variant reconstructions by merging the visible information from the given views. Our approach is divided into three steps. Starting from the sparse views of the object, we first align them into a common coordinate system by estimating the relative pose between all the pairs. Then, inspired by the traditional voxel carving, we generate an occupancy grid of the object taken from the silhouette on the images and their relative poses. Finally, we refine the initial reconstruction to build a clean 3D model which preserves the details from each viewpoint. To validate the proposed method, we perform a comprehensive evaluation on the ShapeNet reference benchmark in terms of relative pose estimation and 3D shape reconstruction.
SCFusion: Real-time Incremental Scene Reconstruction with Semantic Completion
Oct 26, 2020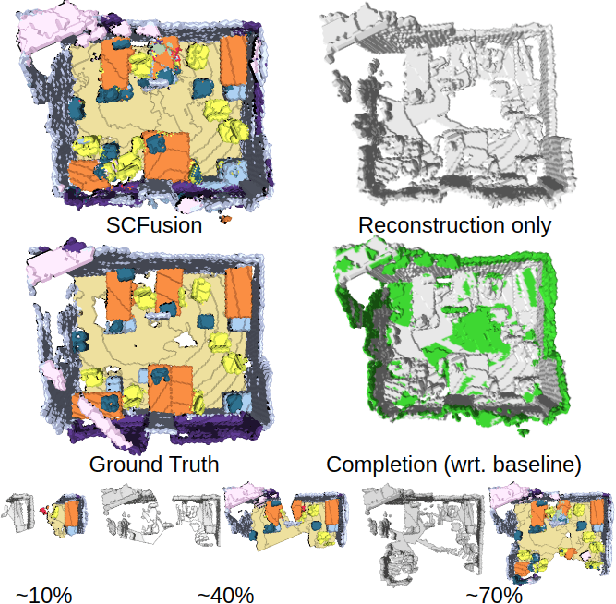
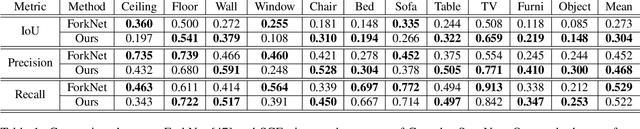
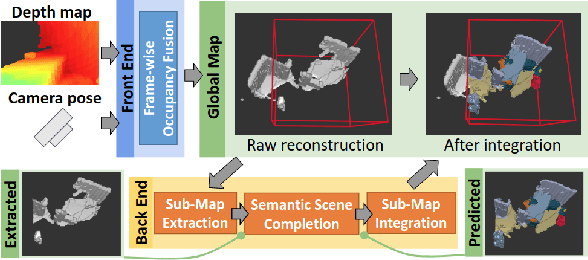

Real-time scene reconstruction from depth data inevitably suffers from occlusion, thus leading to incomplete 3D models. Partial reconstructions, in turn, limit the performance of algorithms that leverage them for applications in the context of, e.g., augmented reality, robotic navigation, and 3D mapping. Most methods address this issue by predicting the missing geometry as an offline optimization, thus being incompatible with real-time applications. We propose a framework that ameliorates this issue by performing scene reconstruction and semantic scene completion jointly in an incremental and real-time manner, based on an input sequence of depth maps. Our framework relies on a novel neural architecture designed to process occupancy maps and leverages voxel states to accurately and efficiently fuse semantic completion with the 3D global model. We evaluate the proposed approach quantitatively and qualitatively, demonstrating that our method can obtain accurate 3D semantic scene completion in real-time.
Peeking Behind Objects: Layered Depth Prediction from a Single Image
Jul 23, 2018
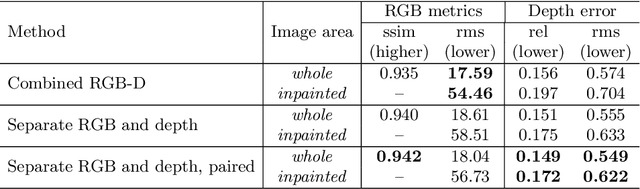
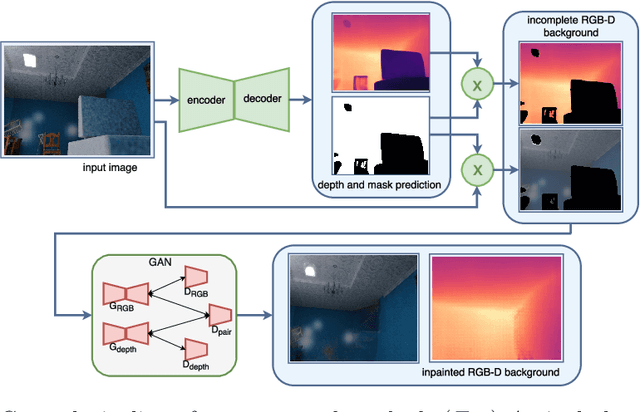
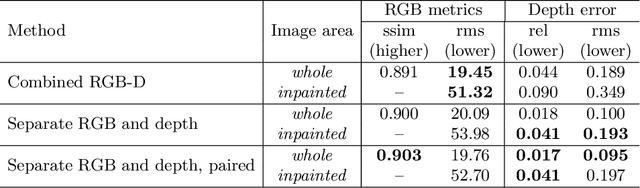
While conventional depth estimation can infer the geometry of a scene from a single RGB image, it fails to estimate scene regions that are occluded by foreground objects. This limits the use of depth prediction in augmented and virtual reality applications, that aim at scene exploration by synthesizing the scene from a different vantage point, or at diminished reality. To address this issue, we shift the focus from conventional depth map prediction to the regression of a specific data representation called Layered Depth Image (LDI), which contains information about the occluded regions in the reference frame and can fill in occlusion gaps in case of small view changes. We propose a novel approach based on Convolutional Neural Networks (CNNs) to jointly predict depth maps and foreground separation masks used to condition Generative Adversarial Networks (GANs) for hallucinating plausible color and depths in the initially occluded areas. We demonstrate the effectiveness of our approach for novel scene view synthesis from a single image.