 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionHarmonizer: Bridging Neural Reconstruction and Photorealistic Simulation with Online Diffusion Enhancer
Mar 05, 2026Simulation is essential to the development and evaluation of autonomous robots such as self-driving vehicles. Neural reconstruction is emerging as a promising solution as it enables simulating a wide variety of scenarios from real-world data alone in an automated and scalable way. However, while methods such as NeRF and 3D Gaussian Splatting can produce visually compelling results, they often exhibit artifacts particularly when rendering novel views, and fail to realistically integrate inserted dynamic objects, especially when they were captured from different scenes. To overcome these limitations, we introduce DiffusionHarmonizer, an online generative enhancement framework that transforms renderings from such imperfect scenes into temporally consistent outputs while improving their realism. At its core is a single-step temporally-conditioned enhancer that is converted from a pretrained multi-step image diffusion model, capable of running in online simulators on a single GPU. The key to training it effectively is a custom data curation pipeline that constructs synthetic-real pairs emphasizing appearance harmonization, artifact correction, and lighting realism. The result is a scalable system that significantly elevates simulation fidelity in both research and production environments.
ArtiFixer: Enhancing and Extending 3D Reconstruction with Auto-Regressive Diffusion Models
Feb 28, 2026Per-scene optimization methods such as 3D Gaussian Splatting provide state-of-the-art novel view synthesis quality but extrapolate poorly to under-observed areas. Methods that leverage generative priors to correct artifacts in these areas hold promise but currently suffer from two shortcomings. The first is scalability, as existing methods use image diffusion models or bidirectional video models that are limited in the number of views they can generate in a single pass (and thus require a costly iterative distillation process for consistency). The second is quality itself, as generators used in prior work tend to produce outputs that are inconsistent with existing scene content and fail entirely in completely unobserved regions. To solve these, we propose a two-stage pipeline that leverages two key insights. First, we train a powerful bidirectional generative model with a novel opacity mixing strategy that encourages consistency with existing observations while retaining the model's ability to extrapolate novel content in unseen areas. Second, we distill it into a causal auto-regressive model that generates hundreds of frames in a single pass. This model can directly produce novel views or serve as pseudo-supervision to improve the underlying 3D representation in a simple and highly efficient manner. We evaluate our method extensively and demonstrate that it can generate plausible reconstructions in scenarios where existing approaches fail completely. When measured on commonly benchmarked datasets, we outperform existing all existing baselines by a wide margin, exceeding prior state-of-the-art methods by 1-3 dB PSNR.
Towards Learning to Complete Anything in Lidar
Apr 16, 2025We propose CAL (Complete Anything in Lidar) for Lidar-based shape-completion in-the-wild. This is closely related to Lidar-based semantic/panoptic scene completion. However, contemporary methods can only complete and recognize objects from a closed vocabulary labeled in existing Lidar datasets. Different to that, our zero-shot approach leverages the temporal context from multi-modal sensor sequences to mine object shapes and semantic features of observed objects. These are then distilled into a Lidar-only instance-level completion and recognition model. Although we only mine partial shape completions, we find that our distilled model learns to infer full object shapes from multiple such partial observations across the dataset. We show that our model can be prompted on standard benchmarks for Semantic and Panoptic Scene Completion, localize objects as (amodal) 3D bounding boxes, and recognize objects beyond fixed class vocabularies. Our project page is https://research.nvidia.com/labs/dvl/projects/complete-anything-lidar
OmniRe: Omni Urban Scene Reconstruction
Aug 29, 2024We introduce OmniRe, a holistic approach for efficiently reconstructing high-fidelity dynamic urban scenes from on-device logs. Recent methods for modeling driving sequences using neural radiance fields or Gaussian Splatting have demonstrated the potential of reconstructing challenging dynamic scenes, but often overlook pedestrians and other non-vehicle dynamic actors, hindering a complete pipeline for dynamic urban scene reconstruction. To that end, we propose a comprehensive 3DGS framework for driving scenes, named OmniRe, that allows for accurate, full-length reconstruction of diverse dynamic objects in a driving log. OmniRe builds dynamic neural scene graphs based on Gaussian representations and constructs multiple local canonical spaces that model various dynamic actors, including vehicles, pedestrians, and cyclists, among many others. This capability is unmatched by existing methods. OmniRe allows us to holistically reconstruct different objects present in the scene, subsequently enabling the simulation of reconstructed scenarios with all actors participating in real-time (~60Hz). Extensive evaluations on the Waymo dataset show that our approach outperforms prior state-of-the-art methods quantitatively and qualitatively by a large margin. We believe our work fills a critical gap in driving reconstruction.
3D Gaussian Ray Tracing: Fast Tracing of Particle Scenes
Jul 10, 2024



Particle-based representations of radiance fields such as 3D Gaussian Splatting have found great success for reconstructing and re-rendering of complex scenes. Most existing methods render particles via rasterization, projecting them to screen space tiles for processing in a sorted order. This work instead considers ray tracing the particles, building a bounding volume hierarchy and casting a ray for each pixel using high-performance GPU ray tracing hardware. To efficiently handle large numbers of semi-transparent particles, we describe a specialized rendering algorithm which encapsulates particles with bounding meshes to leverage fast ray-triangle intersections, and shades batches of intersections in depth-order. The benefits of ray tracing are well-known in computer graphics: processing incoherent rays for secondary lighting effects such as shadows and reflections, rendering from highly-distorted cameras common in robotics, stochastically sampling rays, and more. With our renderer, this flexibility comes at little cost compared to rasterization. Experiments demonstrate the speed and accuracy of our approach, as well as several applications in computer graphics and vision. We further propose related improvements to the basic Gaussian representation, including a simple use of generalized kernel functions which significantly reduces particle hit counts.
Learning Graph Regularisation for Guided Super-Resolution
Mar 27, 2022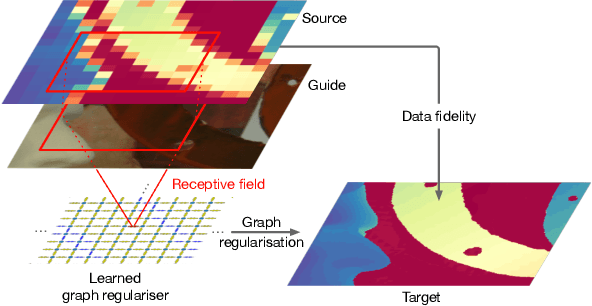

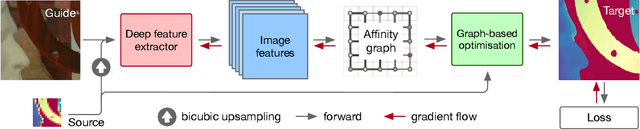

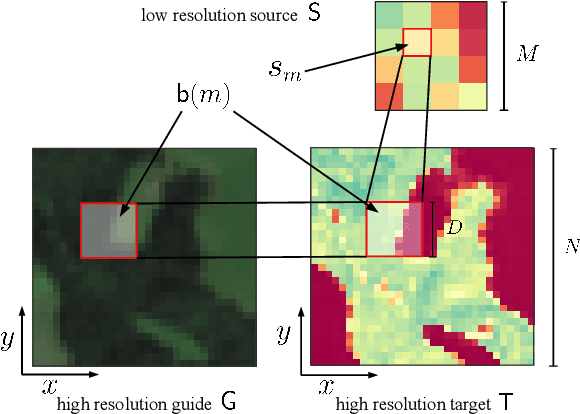
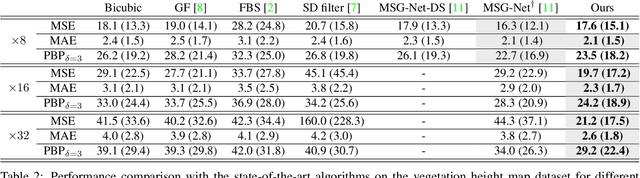
We introduce a novel formulation for guided super-resolution. Its core is a differentiable optimisation layer that operates on a learned affinity graph. The learned graph potentials make it possible to leverage rich contextual information from the guide image, while the explicit graph optimisation within the architecture guarantees rigorous fidelity of the high-resolution target to the low-resolution source. With the decision to employ the source as a constraint rather than only as an input to the prediction, our method differs from state-of-the-art deep architectures for guided super-resolution, which produce targets that, when downsampled, will only approximately reproduce the source. This is not only theoretically appealing, but also produces crisper, more natural-looking images. A key property of our method is that, although the graph connectivity is restricted to the pixel lattice, the associated edge potentials are learned with a deep feature extractor and can encode rich context information over large receptive fields. By taking advantage of the sparse graph connectivity, it becomes possible to propagate gradients through the optimisation layer and learn the edge potentials from data. We extensively evaluate our method on several datasets, and consistently outperform recent baselines in terms of quantitative reconstruction errors, while also delivering visually sharper outputs. Moreover, we demonstrate that our method generalises particularly well to new datasets not seen during training.
Digital Taxonomist: Identifying Plant Species in Citizen Scientists' Photographs
Jun 07, 2021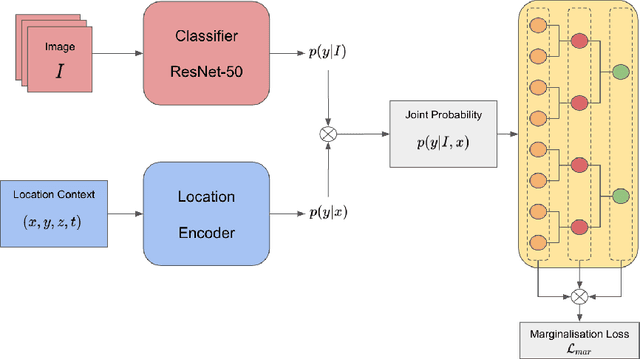


Automatic identification of plant specimens from amateur photographs could improve species range maps, thus supporting ecosystems research as well as conservation efforts. However, classifying plant specimens based on image data alone is challenging: some species exhibit large variations in visual appearance, while at the same time different species are often visually similar; additionally, species observations follow a highly imbalanced, long-tailed distribution due to differences in abundance as well as observer biases. On the other hand, most species observations are accompanied by side information about the spatial, temporal and ecological context. Moreover, biological species are not an unordered list of classes but embedded in a hierarchical taxonomic structure. We propose a machine learning model that takes into account these additional cues in a unified framework. Our Digital Taxonomist is able to identify plant species in photographs more correctly.
The Herbarium 2021 Half-Earth Challenge Dataset
May 28, 2021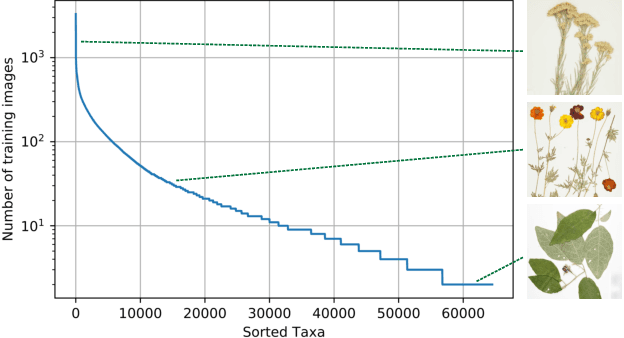
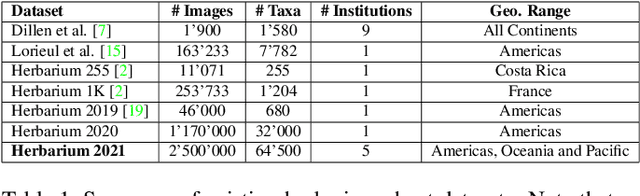

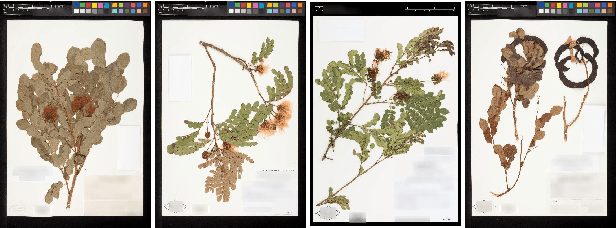
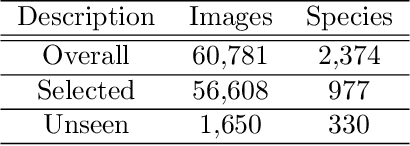
Herbarium sheets present a unique view of the world's botanical history, evolution, and diversity. This makes them an all-important data source for botanical research. With the increased digitisation of herbaria worldwide and the advances in the fine-grained classification domain that can facilitate automatic identification of herbarium specimens, there are a lot of opportunities for supporting research in this field. However, existing datasets are either too small, or not diverse enough, in terms of represented taxa, geographic distribution or host institutions. Furthermore, aggregating multiple datasets is difficult as taxa exist under a multitude of different names and the taxonomy requires alignment to a common reference. We present the Herbarium Half-Earth dataset, the largest and most diverse dataset of herbarium specimens to date for automatic taxon recognition.
Guided Super-Resolution as a Learned Pixel-to-Pixel Transformation
Apr 02, 2019
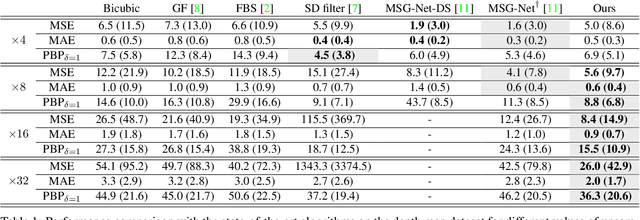
Guided super-resolution is a unifying framework for several computer vision tasks where the inputs are a low-resolution source image of some target quantity (e.g., perspective depth acquired with a time-of-flight camera) and a high-resolution guide image from a different domain (e.g., a gray-scale image from a conventional camera); and the target output is a high-resolution version of the source (in our example, a high-res depth map). The standard way of looking at this problem is to formulate it as a super-resolution task, i.e., the source image is upsampled to the target resolution, while transferring the missing high-frequency details from the guide. Here, we propose to turn that interpretation on its head and instead see it as a pixel-to-pixel mapping of the guide image to the domain of the source image. The pixel-wise mapping is parameterised as a multi-layer perceptron, whose weights are learned by minimising the discrepancies between the source image and the downsampled target image. Importantly, our formulation makes it possible to regularise only the mapping function, while avoiding regularisation of the outputs; Thus producing crisp, natural-looking images. The proposed method is unsupervised, using only the specific source and guide images to fit the mapping. We evaluate our method on two different tasks, super-resolution of depth maps and of tree height maps. In both cases we clearly outperform recent baselines in quantitative comparisons, while delivering visually much sharper outputs.