 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Herbarium 2021 Half-Earth Challenge Dataset
May 28, 2021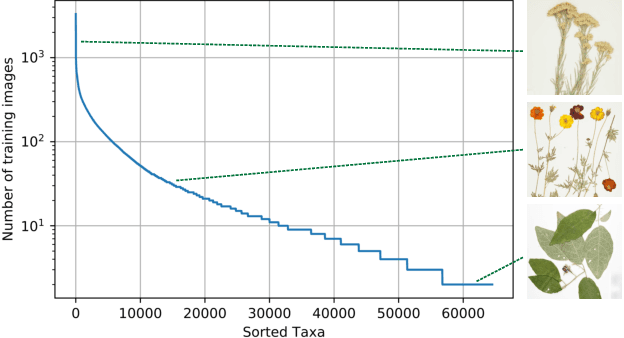
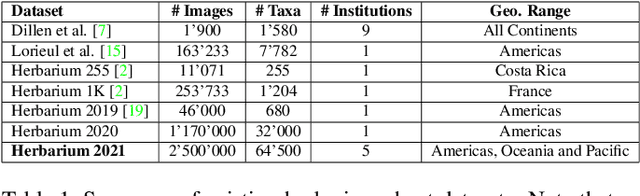

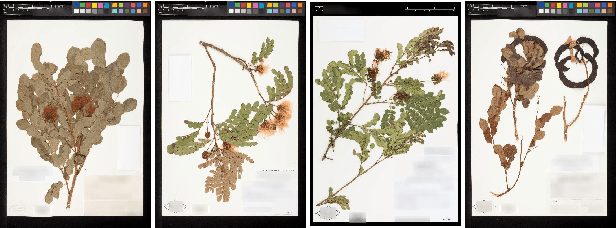
Herbarium sheets present a unique view of the world's botanical history, evolution, and diversity. This makes them an all-important data source for botanical research. With the increased digitisation of herbaria worldwide and the advances in the fine-grained classification domain that can facilitate automatic identification of herbarium specimens, there are a lot of opportunities for supporting research in this field. However, existing datasets are either too small, or not diverse enough, in terms of represented taxa, geographic distribution or host institutions. Furthermore, aggregating multiple datasets is difficult as taxa exist under a multitude of different names and the taxonomy requires alignment to a common reference. We present the Herbarium Half-Earth dataset, the largest and most diverse dataset of herbarium specimens to date for automatic taxon recognition.
The Herbarium Challenge 2019 Dataset
Jun 15, 2019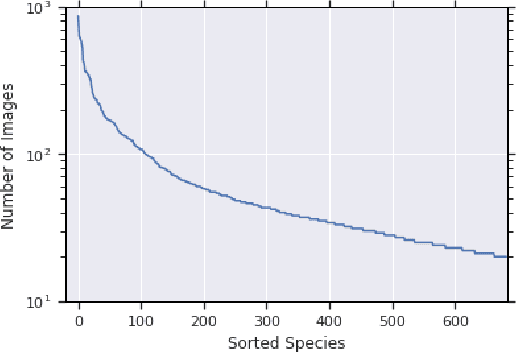



Herbarium sheets are invaluable for botanical research, and considerable time and effort is spent by experts to label and identify specimens on them. In view of recent advances in computer vision and deep learning, developing an automated approach to help experts identify specimens could significantly accelerate research in this area. Whereas most existing botanical datasets comprise photos of specimens in the wild, herbarium sheets exhibit dried specimens, which poses new challenges. We present a challenge dataset of herbarium sheet images labeled by experts, with the intent of facilitating the development of automated identification techniques for this challenging scenario.