 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multilingual Models with Language-Clustered Vocabularies
Oct 24, 2020
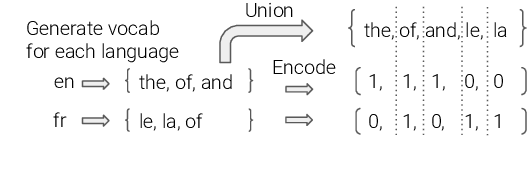
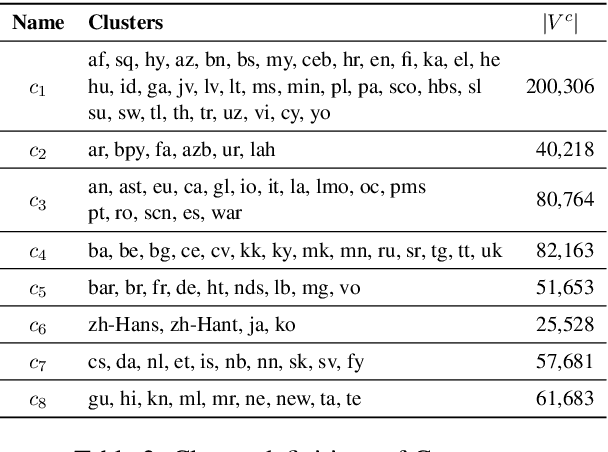
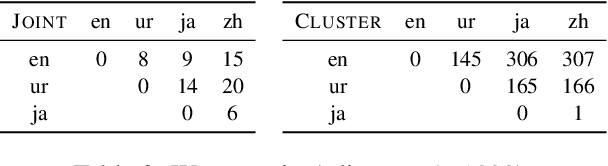
State-of-the-art multilingual models depend on vocabularies that cover all of the languages the model will expect to see at inference time, but the standard methods for generating those vocabularies are not ideal for massively multilingual applications. In this work, we introduce a novel procedure for multilingual vocabulary generation that combines the separately trained vocabularies of several automatically derived language clusters, thus balancing the trade-off between cross-lingual subword sharing and language-specific vocabularies. Our experiments show improvements across languages on key multilingual benchmark tasks TyDi QA (+2.9 F1), XNLI (+2.1\%), and WikiAnn NER (+2.8 F1) and factor of 8 reduction in out-of-vocabulary rate, all without increasing the size of the model or data.
The Herbarium Challenge 2019 Dataset
Jun 15, 2019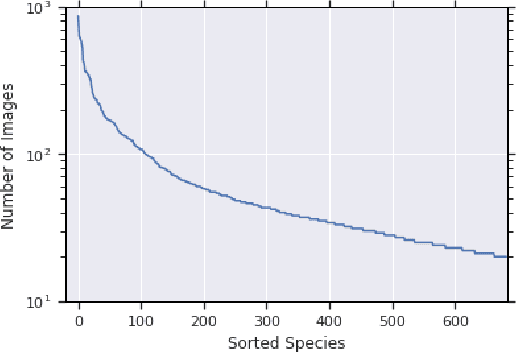



Herbarium sheets are invaluable for botanical research, and considerable time and effort is spent by experts to label and identify specimens on them. In view of recent advances in computer vision and deep learning, developing an automated approach to help experts identify specimens could significantly accelerate research in this area. Whereas most existing botanical datasets comprise photos of specimens in the wild, herbarium sheets exhibit dried specimens, which poses new challenges. We present a challenge dataset of herbarium sheet images labeled by experts, with the intent of facilitating the development of automated identification techniques for this challenging scenario.