Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Herbarium Challenge 2019 Dataset
Jun 15, 2019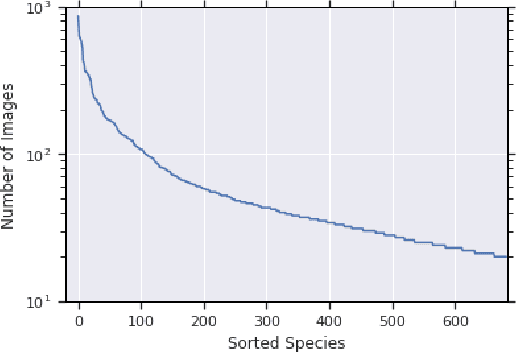



Herbarium sheets are invaluable for botanical research, and considerable time and effort is spent by experts to label and identify specimens on them. In view of recent advances in computer vision and deep learning, developing an automated approach to help experts identify specimens could significantly accelerate research in this area. Whereas most existing botanical datasets comprise photos of specimens in the wild, herbarium sheets exhibit dried specimens, which poses new challenges. We present a challenge dataset of herbarium sheet images labeled by experts, with the intent of facilitating the development of automated identification techniques for this challenging scenario.
* Part of the 6th Fine-Grained Visual Categorization Workshop (FGVC6)
at CVPR 2019. Dataset available at
https://github.com/visipedia/herbarium_comp
Via