 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Activity Recognition from Smartphone Sensor Data for Clinical Trials
Aug 07, 2025We developed a ResNet-based human activity recognition (HAR) model with minimal overhead to detect gait versus non-gait activities and everyday activities (walking, running, stairs, standing, sitting, lying, sit-to-stand transitions). The model was trained and evaluated using smartphone sensor data from adult healthy controls (HC) and people with multiple sclerosis (PwMS) with Expanded Disability Status Scale (EDSS) scores between 0.0-6.5. Datasets included the GaitLab study (ISRCTN15993728), an internal Roche dataset, and publicly available data sources (training only). Data from 34 HC and 68 PwMS (mean [SD] EDSS: 4.7 [1.5]) were included in the evaluation. The HAR model showed 98.4% and 99.6% accuracy in detecting gait versus non-gait activities in the GaitLab and Roche datasets, respectively, similar to a comparative state-of-the-art ResNet model (99.3% and 99.4%). For everyday activities, the proposed model not only demonstrated higher accuracy than the state-of-the-art model (96.2% vs 91.9%; internal Roche dataset) but also maintained high performance across 9 smartphone wear locations (handbag, shopping bag, crossbody bag, backpack, hoodie pocket, coat/jacket pocket, hand, neck, belt), outperforming the state-of-the-art model by 2.8% - 9.0%. In conclusion, the proposed HAR model accurately detects everyday activities and shows high robustness to various smartphone wear locations, demonstrating its practical applicability.
An evaluation of deep learning models for predicting water depth evolution in urban floods
Feb 20, 2023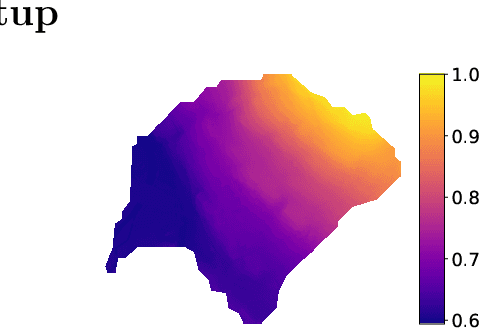

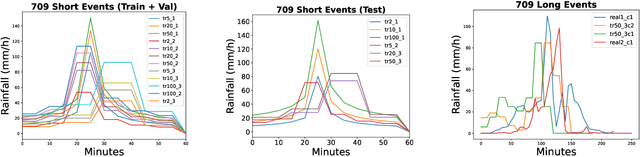

In this technical report we compare different deep learning models for prediction of water depth rasters at high spatial resolution. Efficient, accurate, and fast methods for water depth prediction are nowadays important as urban floods are increasing due to higher rainfall intensity caused by climate change, expansion of cities and changes in land use. While hydrodynamic models models can provide reliable forecasts by simulating water depth at every location of a catchment, they also have a high computational burden which jeopardizes their application to real-time prediction in large urban areas at high spatial resolution. Here, we propose to address this issue by using data-driven techniques. Specifically, we evaluate deep learning models which are trained to reproduce the data simulated by the CADDIES cellular-automata flood model, providing flood forecasts that can occur at different future time horizons. The advantage of using such models is that they can learn the underlying physical phenomena a priori, preventing manual parameter setting and computational burden. We perform experiments on a dataset consisting of two catchments areas within Switzerland with 18 simpler, short rainfall patterns and 4 long, more complex ones. Our results show that the deep learning models present in general lower errors compared to the other methods, especially for water depths $>0.5m$. However, when testing on more complex rainfall events or unseen catchment areas, the deep models do not show benefits over the simpler ones.
Learning Graph Regularisation for Guided Super-Resolution
Mar 27, 2022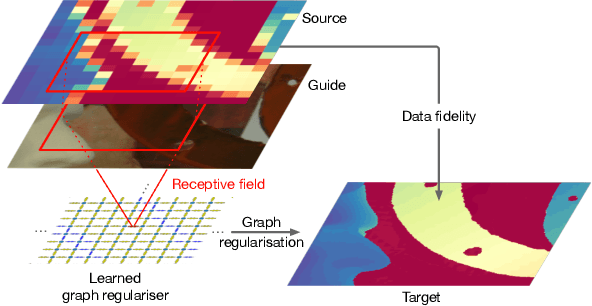

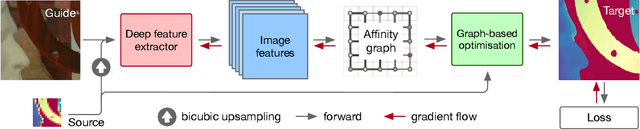

We introduce a novel formulation for guided super-resolution. Its core is a differentiable optimisation layer that operates on a learned affinity graph. The learned graph potentials make it possible to leverage rich contextual information from the guide image, while the explicit graph optimisation within the architecture guarantees rigorous fidelity of the high-resolution target to the low-resolution source. With the decision to employ the source as a constraint rather than only as an input to the prediction, our method differs from state-of-the-art deep architectures for guided super-resolution, which produce targets that, when downsampled, will only approximately reproduce the source. This is not only theoretically appealing, but also produces crisper, more natural-looking images. A key property of our method is that, although the graph connectivity is restricted to the pixel lattice, the associated edge potentials are learned with a deep feature extractor and can encode rich context information over large receptive fields. By taking advantage of the sparse graph connectivity, it becomes possible to propagate gradients through the optimisation layer and learn the edge potentials from data. We extensively evaluate our method on several datasets, and consistently outperform recent baselines in terms of quantitative reconstruction errors, while also delivering visually sharper outputs. Moreover, we demonstrate that our method generalises particularly well to new datasets not seen during training.
Country-wide Retrieval of Forest Structure From Optical and SAR Satellite Imagery With Bayesian Deep Learning
Nov 25, 2021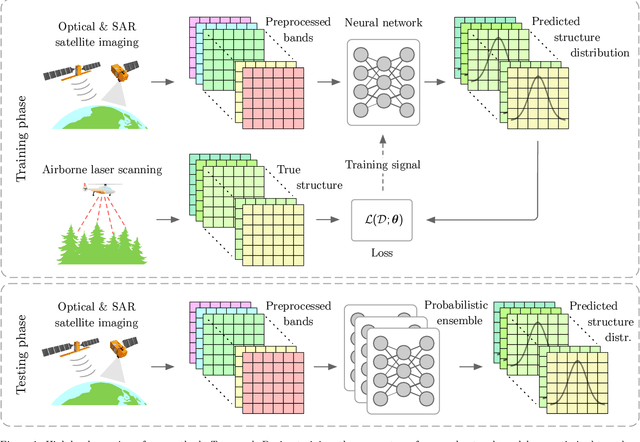
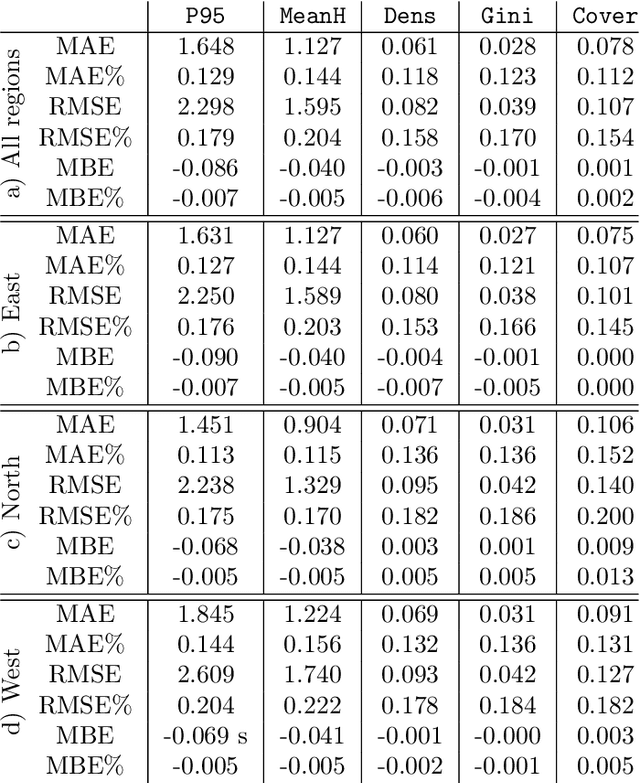
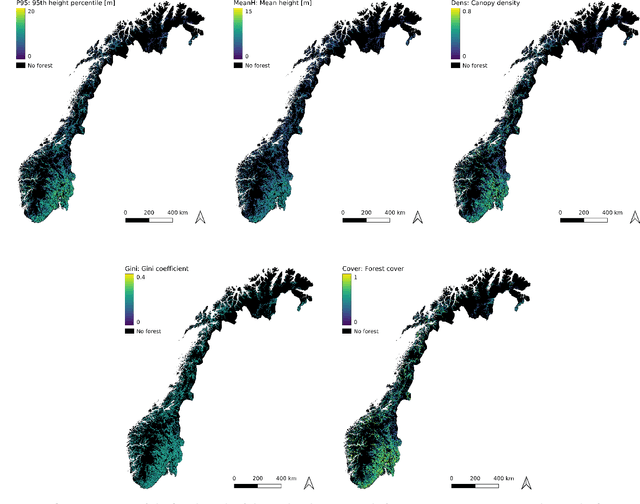
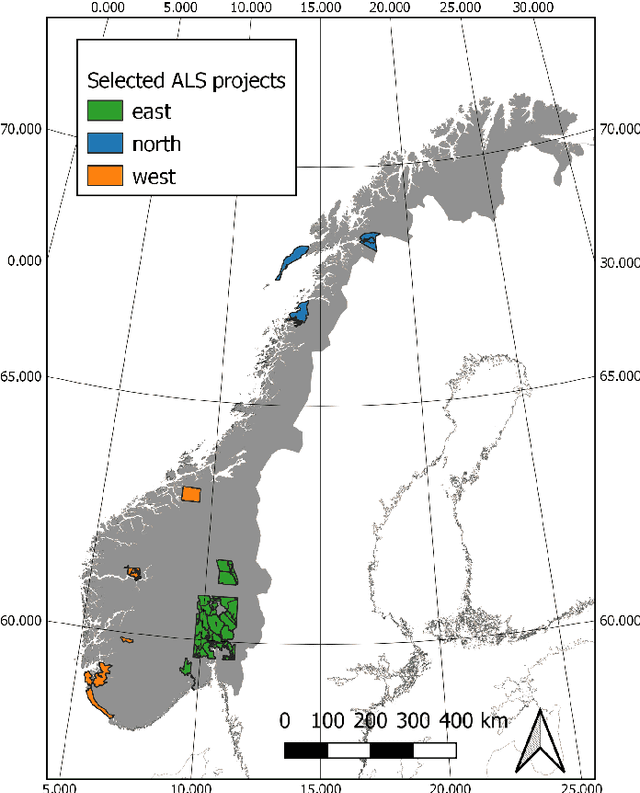
Monitoring and managing Earth's forests in an informed manner is an important requirement for addressing challenges like biodiversity loss and climate change. While traditional in situ or aerial campaigns for forest assessments provide accurate data for analysis at regional level, scaling them to entire countries and beyond with high temporal resolution is hardly possible. In this work, we propose a Bayesian deep learning approach to densely estimate forest structure variables at country-scale with 10-meter resolution, using freely available satellite imagery as input. Our method jointly transforms Sentinel-2 optical images and Sentinel-1 synthetic aperture radar images into maps of five different forest structure variables: 95th height percentile, mean height, density, Gini coefficient, and fractional cover. We train and test our model on reference data from 41 airborne laser scanning missions across Norway and demonstrate that it is able to generalize to unseen test regions, achieving normalized mean absolute errors between 11% and 15%, depending on the variable. Our work is also the first to propose a Bayesian deep learning approach so as to predict forest structure variables with well-calibrated uncertainty estimates. These increase the trustworthiness of the model and its suitability for downstream tasks that require reliable confidence estimates, such as informed decision making. We present an extensive set of experiments to validate the accuracy of the predicted maps as well as the quality of the predicted uncertainties. To demonstrate scalability, we provide Norway-wide maps for the five forest structure variables.
Digital Taxonomist: Identifying Plant Species in Citizen Scientists' Photographs
Jun 07, 2021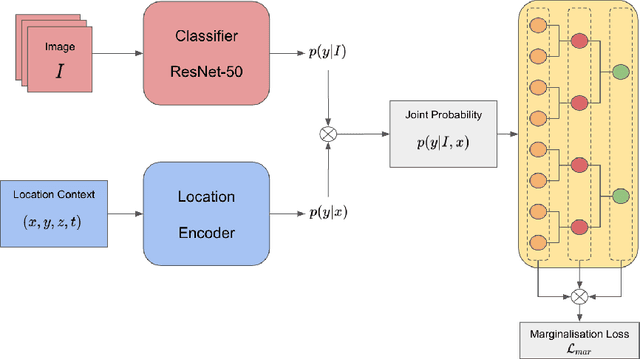


Automatic identification of plant specimens from amateur photographs could improve species range maps, thus supporting ecosystems research as well as conservation efforts. However, classifying plant specimens based on image data alone is challenging: some species exhibit large variations in visual appearance, while at the same time different species are often visually similar; additionally, species observations follow a highly imbalanced, long-tailed distribution due to differences in abundance as well as observer biases. On the other hand, most species observations are accompanied by side information about the spatial, temporal and ecological context. Moreover, biological species are not an unordered list of classes but embedded in a hierarchical taxonomic structure. We propose a machine learning model that takes into account these additional cues in a unified framework. Our Digital Taxonomist is able to identify plant species in photographs more correctly.
Anomaly Detection using Deep Autoencoders for in-situ Wastewater Systems Monitoring Data
Mar 06, 2020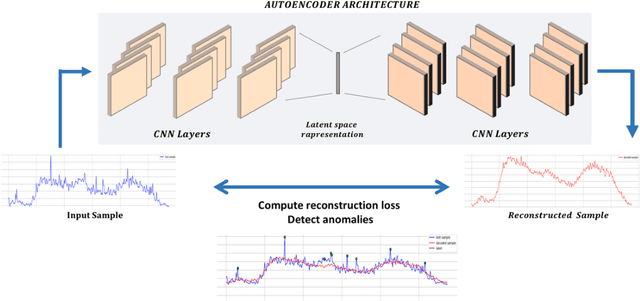

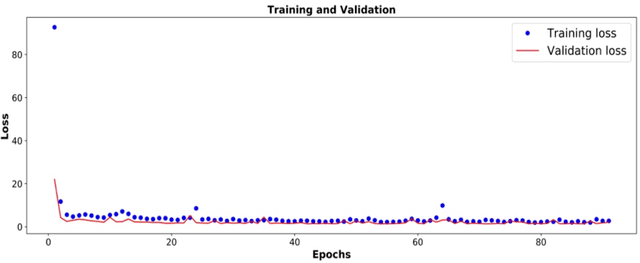

Due to the growing amount of data from in-situ sensors in wastewater systems, it becomes necessary to automatically identify abnormal behaviours and ensure high data quality. This paper proposes an anomaly detection method based on a deep autoencoder for in-situ wastewater systems monitoring data. The autoencoder architecture is based on 1D Convolutional Neural Network (CNN) layers where the convolutions are performed over the inputs across the temporal axis of the data. Anomaly detection is then performed based on the reconstruction error of the decoding stage. The approach is validated on multivariate time series from in-sewer process monitoring data. We discuss the results and the challenge of labelling anomalies in complex time series. We suggest that our proposed approach can support the domain experts in the identification of anomalies.
* 10th IWA Symposium on Modelling and Integrated Assessment (Watermatex 2019)