 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised learning unveils change in urban housing from street-level images
Sep 21, 2023



Cities around the world face a critical shortage of affordable and decent housing. Despite its critical importance for policy, our ability to effectively monitor and track progress in urban housing is limited. Deep learning-based computer vision methods applied to street-level images have been successful in the measurement of socioeconomic and environmental inequalities but did not fully utilize temporal images to track urban change as time-varying labels are often unavailable. We used self-supervised methods to measure change in London using 15 million street images taken between 2008 and 2021. Our novel adaptation of Barlow Twins, Street2Vec, embeds urban structure while being invariant to seasonal and daily changes without manual annotations. It outperformed generic embeddings, successfully identified point-level change in London's housing supply from street-level images, and distinguished between major and minor change. This capability can provide timely information for urban planning and policy decisions toward more liveable, equitable, and sustainable cities.
An evaluation of deep learning models for predicting water depth evolution in urban floods
Feb 20, 2023

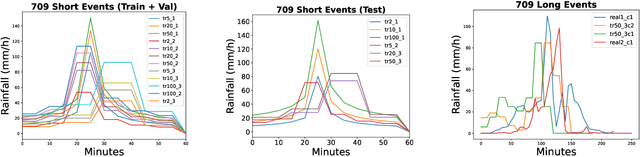

In this technical report we compare different deep learning models for prediction of water depth rasters at high spatial resolution. Efficient, accurate, and fast methods for water depth prediction are nowadays important as urban floods are increasing due to higher rainfall intensity caused by climate change, expansion of cities and changes in land use. While hydrodynamic models models can provide reliable forecasts by simulating water depth at every location of a catchment, they also have a high computational burden which jeopardizes their application to real-time prediction in large urban areas at high spatial resolution. Here, we propose to address this issue by using data-driven techniques. Specifically, we evaluate deep learning models which are trained to reproduce the data simulated by the CADDIES cellular-automata flood model, providing flood forecasts that can occur at different future time horizons. The advantage of using such models is that they can learn the underlying physical phenomena a priori, preventing manual parameter setting and computational burden. We perform experiments on a dataset consisting of two catchments areas within Switzerland with 18 simpler, short rainfall patterns and 4 long, more complex ones. Our results show that the deep learning models present in general lower errors compared to the other methods, especially for water depths $>0.5m$. However, when testing on more complex rainfall events or unseen catchment areas, the deep models do not show benefits over the simpler ones.
What You See is What You Classify: Black Box Attributions
May 23, 2022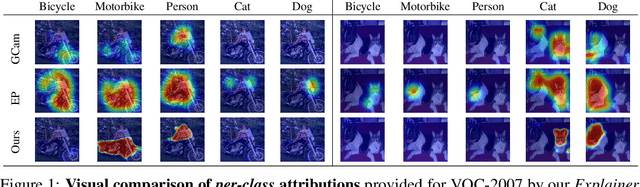
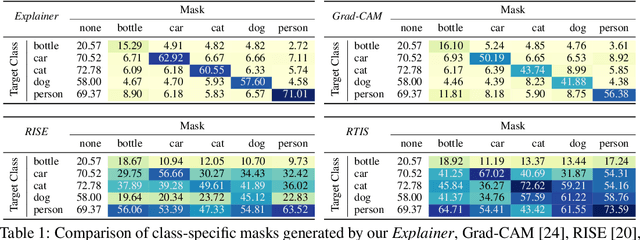
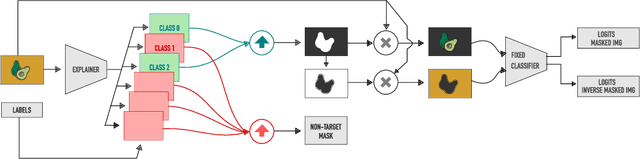
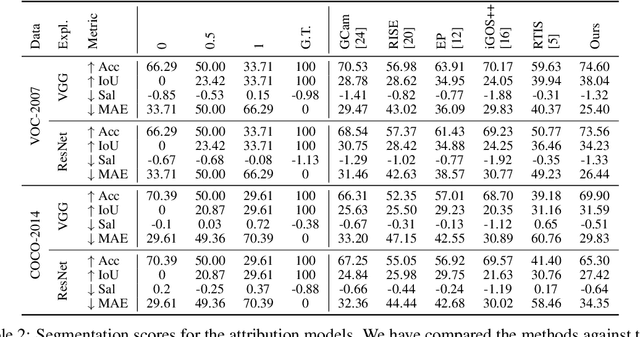
An important step towards explaining deep image classifiers lies in the identification of image regions that contribute to individual class scores in the model's output. However, doing this accurately is a difficult task due to the black-box nature of such networks. Most existing approaches find such attributions either using activations and gradients or by repeatedly perturbing the input. We instead address this challenge by training a second deep network, the Explainer, to predict attributions for a pre-trained black-box classifier, the Explanandum. These attributions are in the form of masks that only show the classifier-relevant parts of an image, masking out the rest. Our approach produces sharper and more boundary-precise masks when compared to the saliency maps generated by other methods. Moreover, unlike most existing approaches, ours is capable of directly generating very distinct class-specific masks. Finally, the proposed method is very efficient for inference since it only takes a single forward pass through the Explainer to generate all class-specific masks. We show that our attributions are superior to established methods both visually and quantitatively, by evaluating them on the PASCAL VOC-2007 and Microsoft COCO-2014 datasets.
Online Robustness Training for Deep Reinforcement Learning
Nov 22, 2019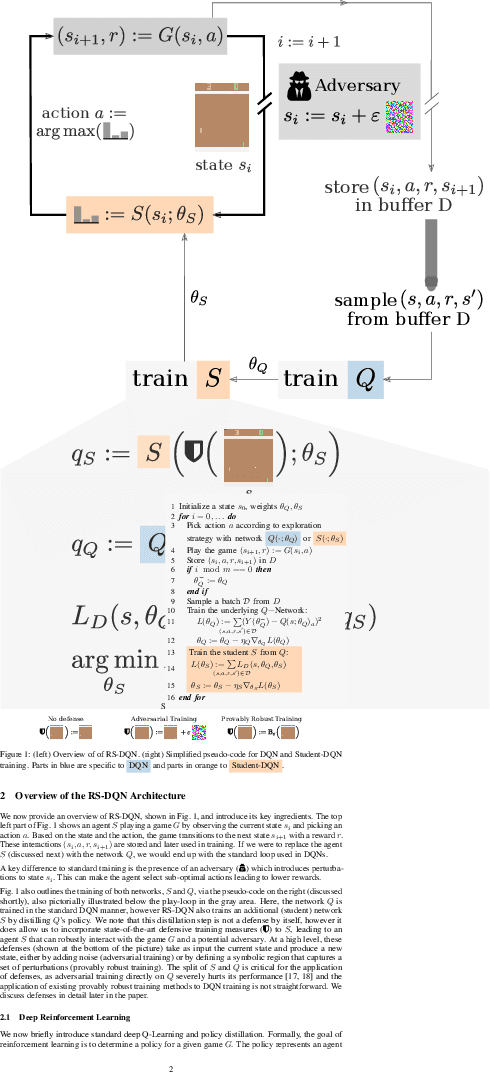
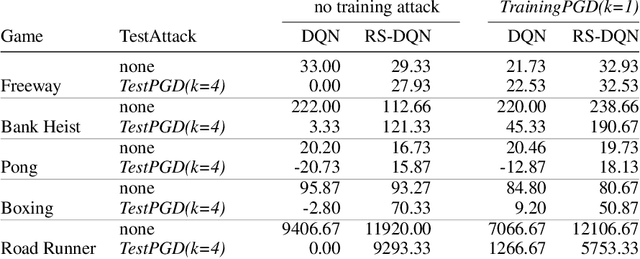
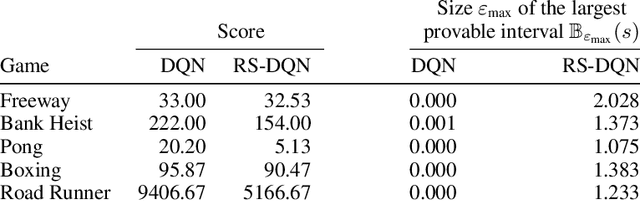
In deep reinforcement learning (RL), adversarial attacks can trick an agent into unwanted states and disrupt training. We propose a system called Robust Student-DQN (RS-DQN), which permits online robustness training alongside Q networks, while preserving competitive performance. We show that RS-DQN can be combined with (i) state-of-the-art adversarial training and (ii) provably robust training to obtain an agent that is resilient to strong attacks during training and evaluation.