 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting butterfly species presence from satellite imagery using soft contrastive regularisation
May 14, 2025The growing demand for scalable biodiversity monitoring methods has fuelled interest in remote sensing data, due to its widespread availability and extensive coverage. Traditionally, the application of remote sensing to biodiversity research has focused on mapping and monitoring habitats, but with increasing availability of large-scale citizen-science wildlife observation data, recent methods have started to explore predicting multi-species presence directly from satellite images. This paper presents a new data set for predicting butterfly species presence from satellite data in the United Kingdom. We experimentally optimise a Resnet-based model to predict multi-species presence from 4-band satellite images, and find that this model especially outperforms the mean rate baseline for locations with high species biodiversity. To improve performance, we develop a soft, supervised contrastive regularisation loss that is tailored to probabilistic labels (such as species-presence data), and demonstrate that this improves prediction accuracy. In summary, our new data set and contrastive regularisation method contribute to the open challenge of accurately predicting species biodiversity from remote sensing data, which is key for efficient biodiversity monitoring.
MedGNN: Capturing the Links Between Urban Characteristics and Medical Prescriptions
Apr 07, 2025Understanding how urban socio-demographic and environmental factors relate with health is essential for public health and urban planning. However, traditional statistical methods struggle with nonlinear effects, while machine learning models often fail to capture geographical (nearby areas being more similar) and topological (unequal connectivity between places) effects in an interpretable way. To address this, we propose MedGNN, a spatio-topologically explicit framework that constructs a 2-hop spatial graph, integrating positional and locational node embeddings with urban characteristics in a graph neural network. Applied to MEDSAT, a comprehensive dataset covering over 150 environmental and socio-demographic factors and six prescription outcomes (depression, anxiety, diabetes, hypertension, asthma, and opioids) across 4,835 Greater London neighborhoods, MedGNN improved predictions by over 25% on average compared to baseline methods. Using depression prescriptions as a case study, we analyzed graph embeddings via geographical principal component analysis, identifying findings that: align with prior research (e.g., higher antidepressant prescriptions among older and White populations), contribute to ongoing debates (e.g., greenery linked to higher and NO2 to lower prescriptions), and warrant further study (e.g., canopy evaporation correlated with fewer prescriptions). These results demonstrate MedGNN's potential, and more broadly, of carefully applied machine learning, to advance transdisciplinary public health research.
Multimodal Contrastive Learning of Urban Space Representations from POI Data
Nov 09, 2024Existing methods for learning urban space representations from Point-of-Interest (POI) data face several limitations, including issues with geographical delineation, inadequate spatial information modelling, underutilisation of POI semantic attributes, and computational inefficiencies. To address these issues, we propose CaLLiPer (Contrastive Language-Location Pre-training), a novel representation learning model that directly embeds continuous urban spaces into vector representations that can capture the spatial and semantic distribution of urban environment. This model leverages a multimodal contrastive learning objective, aligning location embeddings with textual POI descriptions, thereby bypassing the need for complex training corpus construction and negative sampling. We validate CaLLiPer's effectiveness by applying it to learning urban space representations in London, UK, where it demonstrates 5-15% improvement in predictive performance for land use classification and socioeconomic mapping tasks compared to state-of-the-art methods. Visualisations of the learned representations further illustrate our model's advantages in capturing spatial variations in urban semantics with high accuracy and fine resolution. Additionally, CaLLiPer achieves reduced training time, showcasing its efficiency and scalability. This work provides a promising pathway for scalable, semantically rich urban space representation learning that can support the development of geospatial foundation models. The implementation code is available at https://github.com/xlwang233/CaLLiPer.
Examining the Commitments and Difficulties Inherent in Multimodal Foundation Models for Street View Imagery
Aug 23, 2024



The emergence of Large Language Models (LLMs) and multimodal foundation models (FMs) has generated heightened interest in their applications that integrate vision and language. This paper investigates the capabilities of ChatGPT-4V and Gemini Pro for Street View Imagery, Built Environment, and Interior by evaluating their performance across various tasks. The assessments include street furniture identification, pedestrian and car counts, and road width measurement in Street View Imagery; building function classification, building age analysis, building height analysis, and building structure classification in the Built Environment; and interior room classification, interior design style analysis, interior furniture counts, and interior length measurement in Interior. The results reveal proficiency in length measurement, style analysis, question answering, and basic image understanding, but highlight limitations in detailed recognition and counting tasks. While zero-shot learning shows potential, performance varies depending on the problem domains and image complexities. This study provides new insights into the strengths and weaknesses of multimodal foundation models for practical challenges in Street View Imagery, Built Environment, and Interior. Overall, the findings demonstrate foundational multimodal intelligence, emphasizing the potential of FMs to drive forward interdisciplinary applications at the intersection of computer vision and language.
SMA-Hyper: Spatiotemporal Multi-View Fusion Hypergraph Learning for Traffic Accident Prediction
Jul 24, 2024
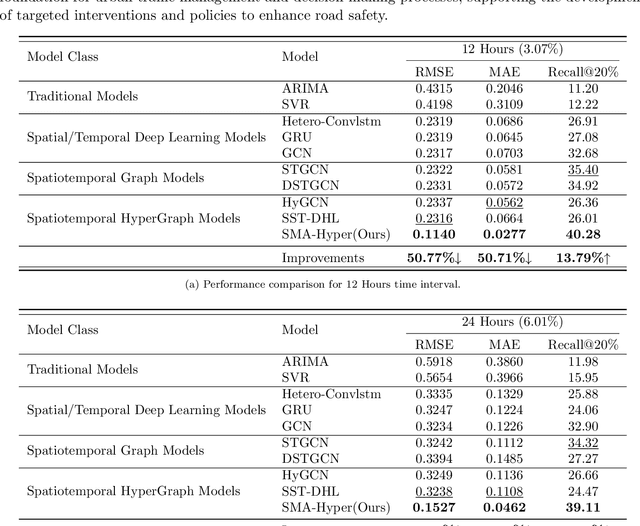

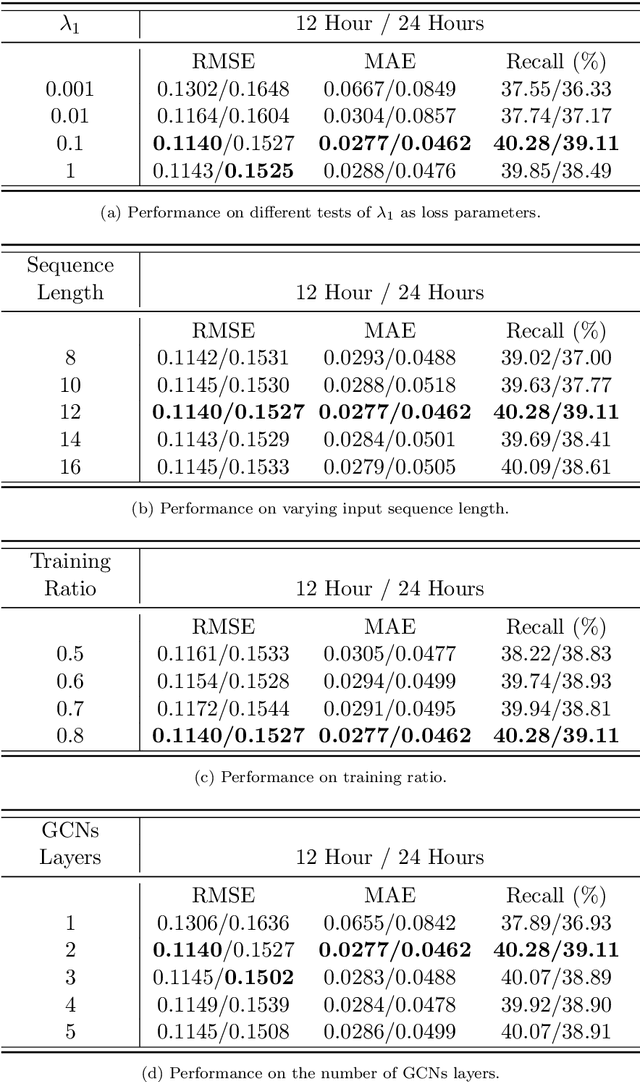
Predicting traffic accidents is the key to sustainable city management, which requires effective address of the dynamic and complex spatiotemporal characteristics of cities. Current data-driven models often struggle with data sparsity and typically overlook the integration of diverse urban data sources and the high-order dependencies within them. Additionally, they frequently rely on predefined topologies or weights, limiting their adaptability in spatiotemporal predictions. To address these issues, we introduce the Spatiotemporal Multiview Adaptive HyperGraph Learning (SMA-Hyper) model, a dynamic deep learning framework designed for traffic accident prediction. Building on previous research, this innovative model incorporates dual adaptive spatiotemporal graph learning mechanisms that enable high-order cross-regional learning through hypergraphs and dynamic adaptation to evolving urban data. It also utilises contrastive learning to enhance global and local data representations in sparse datasets and employs an advance attention mechanism to fuse multiple views of accident data and urban functional features, thereby enriching the contextual understanding of risk factors. Extensive testing on the London traffic accident dataset demonstrates that the SMA-Hyper model significantly outperforms baseline models across various temporal horizons and multistep outputs, affirming the effectiveness of its multiview fusion and adaptive learning strategies. The interpretability of the results further underscores its potential to improve urban traffic management and safety by leveraging complex spatiotemporal urban data, offering a scalable framework adaptable to diverse urban environments.
Exploring selective image matching methods for zero-shot and few-sample unsupervised domain adaptation of urban canopy prediction
Apr 16, 2024We explore simple methods for adapting a trained multi-task UNet which predicts canopy cover and height to a new geographic setting using remotely sensed data without the need of training a domain-adaptive classifier and extensive fine-tuning. Extending previous research, we followed a selective alignment process to identify similar images in the two geographical domains and then tested an array of data-based unsupervised domain adaptation approaches in a zero-shot setting as well as with a small amount of fine-tuning. We find that the selective aligned data-based image matching methods produce promising results in a zero-shot setting, and even more so with a small amount of fine-tuning. These methods outperform both an untransformed baseline and a popular data-based image-to-image translation model. The best performing methods were pixel distribution adaptation and fourier domain adaptation on the canopy cover and height tasks respectively.
Self-supervised learning unveils change in urban housing from street-level images
Sep 21, 2023



Cities around the world face a critical shortage of affordable and decent housing. Despite its critical importance for policy, our ability to effectively monitor and track progress in urban housing is limited. Deep learning-based computer vision methods applied to street-level images have been successful in the measurement of socioeconomic and environmental inequalities but did not fully utilize temporal images to track urban change as time-varying labels are often unavailable. We used self-supervised methods to measure change in London using 15 million street images taken between 2008 and 2021. Our novel adaptation of Barlow Twins, Street2Vec, embeds urban structure while being invariant to seasonal and daily changes without manual annotations. It outperformed generic embeddings, successfully identified point-level change in London's housing supply from street-level images, and distinguished between major and minor change. This capability can provide timely information for urban planning and policy decisions toward more liveable, equitable, and sustainable cities.
Estimating Chicago's tree cover and canopy height using multi-spectral satellite imagery
Dec 09, 2022Information on urban tree canopies is fundamental to mitigating climate change [1] as well as improving quality of life [2]. Urban tree planting initiatives face a lack of up-to-date data about the horizontal and vertical dimensions of the tree canopy in cities. We present a pipeline that utilizes LiDAR data as ground-truth and then trains a multi-task machine learning model to generate reliable estimates of tree cover and canopy height in urban areas using multi-source multi-spectral satellite imagery for the case study of Chicago.
Jane Jacobs in the Sky: Predicting Urban Vitality with Open Satellite Data
Jan 28, 2021

The presence of people in an urban area throughout the day -- often called 'urban vitality' -- is one of the qualities world-class cities aspire to the most, yet it is one of the hardest to achieve. Back in the 1970s, Jane Jacobs theorized urban vitality and found that there are four conditions required for the promotion of life in cities: diversity of land use, small block sizes, the mix of economic activities, and concentration of people. To build proxies for those four conditions and ultimately test Jane Jacobs's theory at scale, researchers have had to collect both private and public data from a variety of sources, and that took decades. Here we propose the use of one single source of data, which happens to be publicly available: Sentinel-2 satellite imagery. In particular, since the first two conditions (diversity of land use and small block sizes) are visible to the naked eye from satellite imagery, we tested whether we could automatically extract them with a state-of-the-art deep-learning framework and whether, in the end, the extracted features could predict vitality. In six Italian cities for which we had call data records, we found that our framework is able to explain on average 55% of the variance in urban vitality extracted from those records.
Adversarial Perturbations on the Perceptual Ball
Dec 19, 2019
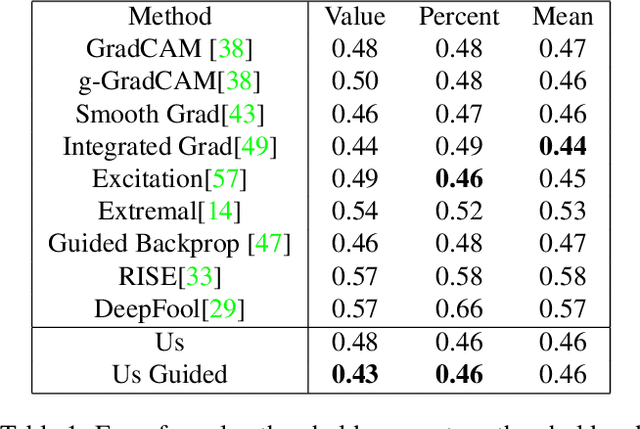

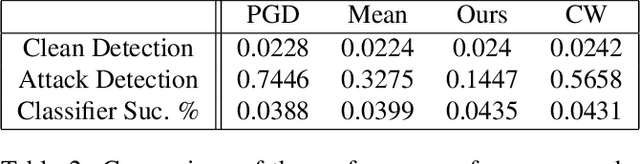
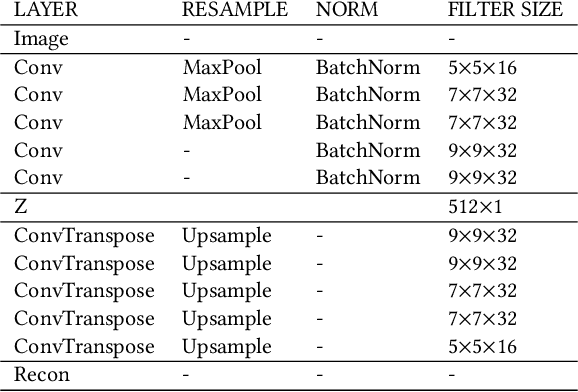
We present a simple regularisation of Adversarial Perturbations based upon the perceptual loss. While the resulting perturbations remain imperceptible to the human eye, they differ from existing adversarial perturbations in two important regards: (i) our resulting perturbations are semi-sparse,and typically make alterations to objects and regions of interest leaving the background static; (ii) our perturbations do not alter the distribution of data in the image and are undetectable by state-of-the-art-methods. As such this workreinforces the connection between explainable AI and adversarial perturbations. We show the merits of our approach by evaluating onstandard explainablity benchmarks and by defeating recenttests for detecting adversarial perturbations, substantially decreasing the effectiveness of detecting adversarial perturbations.