 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph-Based Context-Aware Model to Understand Online Conversations
Nov 16, 2022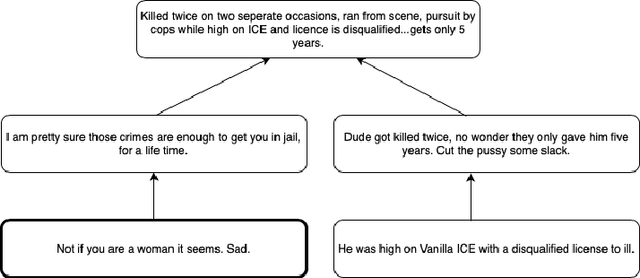
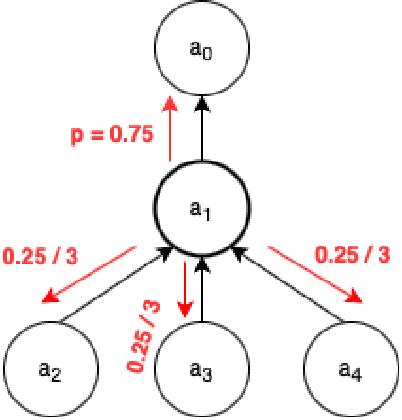
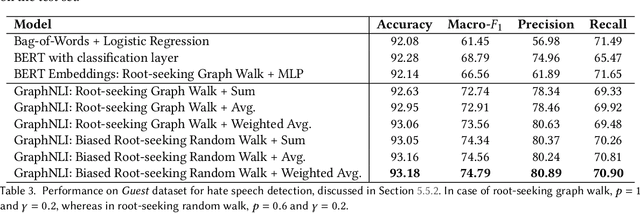
Online forums that allow for participatory engagement between users have been transformative for the public discussion of many important issues. However, such conversations can sometimes escalate into full-blown exchanges of hate and misinformation. Existing approaches in natural language processing (NLP), such as deep learning models for classification tasks, use as inputs only a single comment or a pair of comments depending upon whether the task concerns the inference of properties of the individual comments or the replies between pairs of comments, respectively. But in online conversations, comments and replies may be based on external context beyond the immediately relevant information that is input to the model. Therefore, being aware of the conversations' surrounding contexts should improve the model's performance for the inference task at hand. We propose GraphNLI, a novel graph-based deep learning architecture that uses graph walks to incorporate the wider context of a conversation in a principled manner. Specifically, a graph walk starts from a given comment and samples "nearby" comments in the same or parallel conversation threads, which results in additional embeddings that are aggregated together with the initial comment's embedding. We then use these enriched embeddings for downstream NLP prediction tasks that are important for online conversations. We evaluate GraphNLI on two such tasks - polarity prediction and misogynistic hate speech detection - and found that our model consistently outperforms all relevant baselines for both tasks. Specifically, GraphNLI with a biased root-seeking random walk performs with a macro-F1 score of 3 and 6 percentage points better than the best-performing BERT-based baselines for the polarity prediction and hate speech detection tasks, respectively.
GraphNLI: A Graph-based Natural Language Inference Model for Polarity Prediction in Online Debates
Feb 16, 2022



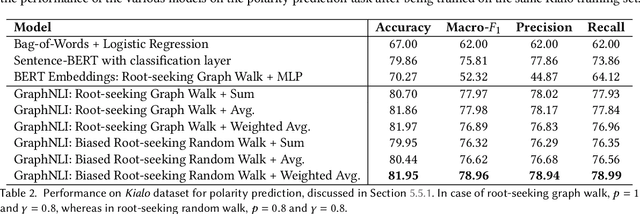
Online forums that allow participatory engagement between users have been transformative for public discussion of important issues. However, debates on such forums can sometimes escalate into full blown exchanges of hate or misinformation. An important tool in understanding and tackling such problems is to be able to infer the argumentative relation of whether a reply is supporting or attacking the post it is replying to. This so called polarity prediction task is difficult because replies may be based on external context beyond a post and the reply whose polarity is being predicted. We propose GraphNLI, a novel graph-based deep learning architecture that uses graph walk techniques to capture the wider context of a discussion thread in a principled fashion. Specifically, we propose methods to perform root-seeking graph walks that start from a post and captures its surrounding context to generate additional embeddings for the post. We then use these embeddings to predict the polarity relation between a reply and the post it is replying to. We evaluate the performance of our models on a curated debate dataset from Kialo, an online debating platform. Our model outperforms relevant baselines, including S-BERT, with an overall accuracy of 83%.
The Healthy States of America: Creating a Health Taxonomy with Social Media
Mar 01, 2021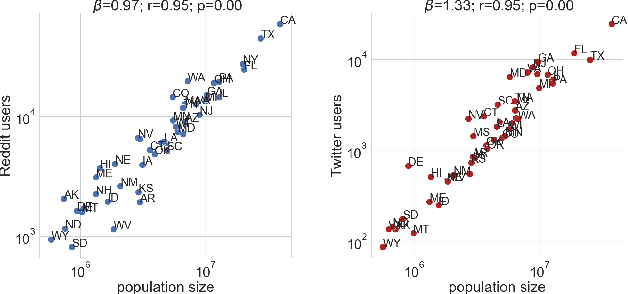
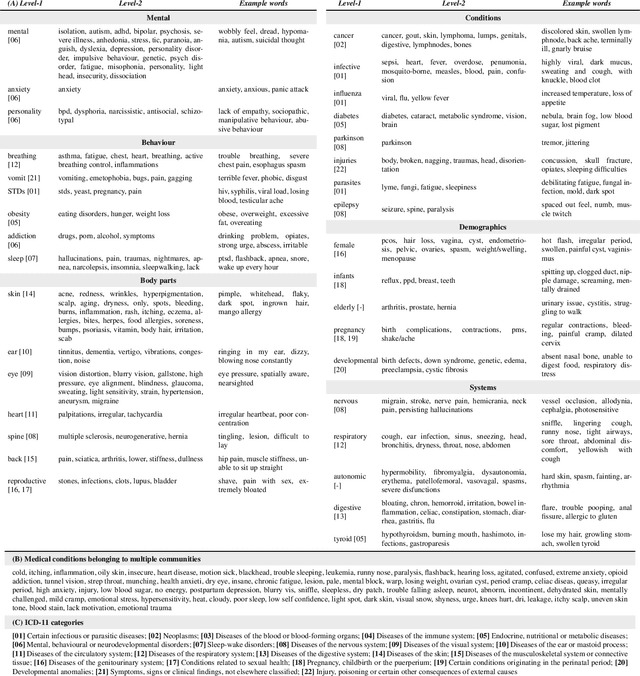
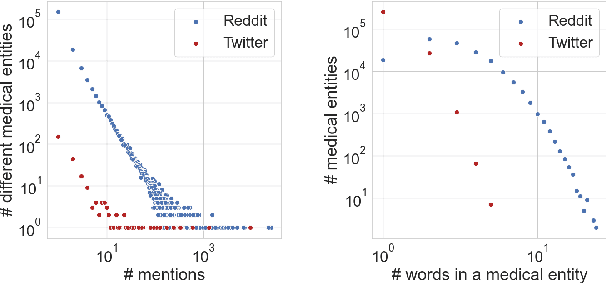
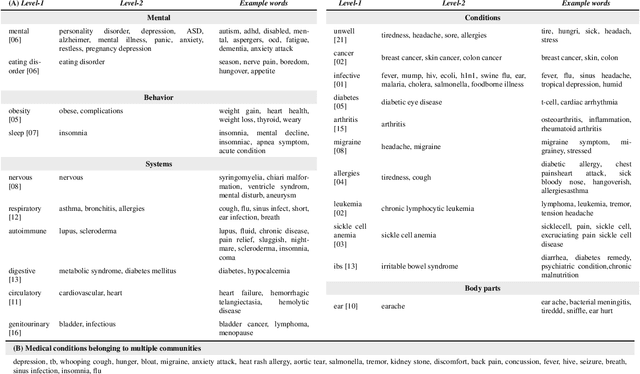
Since the uptake of social media, researchers have mined online discussions to track the outbreak and evolution of specific diseases or chronic conditions such as influenza or depression. To broaden the set of diseases under study, we developed a Deep Learning tool for Natural Language Processing that extracts mentions of virtually any medical condition or disease from unstructured social media text. With that tool at hand, we processed Reddit and Twitter posts, analyzed the clusters of the two resulting co-occurrence networks of conditions, and discovered that they correspond to well-defined categories of medical conditions. This resulted in the creation of the first comprehensive taxonomy of medical conditions automatically derived from online discussions. We validated the structure of our taxonomy against the official International Statistical Classification of Diseases and Related Health Problems (ICD-11), finding matches of our clusters with 20 official categories, out of 22. Based on the mentions of our taxonomy's sub-categories on Reddit posts geo-referenced in the U.S., we were then able to compute disease-specific health scores. As opposed to counts of disease mentions or counts with no knowledge of our taxonomy's structure, we found that our disease-specific health scores are causally linked with the officially reported prevalence of 18 conditions.
Jane Jacobs in the Sky: Predicting Urban Vitality with Open Satellite Data
Jan 28, 2021
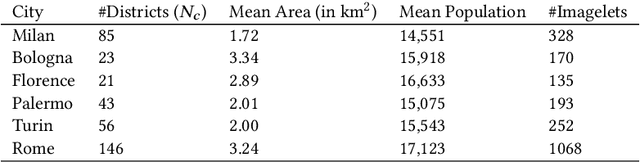

The presence of people in an urban area throughout the day -- often called 'urban vitality' -- is one of the qualities world-class cities aspire to the most, yet it is one of the hardest to achieve. Back in the 1970s, Jane Jacobs theorized urban vitality and found that there are four conditions required for the promotion of life in cities: diversity of land use, small block sizes, the mix of economic activities, and concentration of people. To build proxies for those four conditions and ultimately test Jane Jacobs's theory at scale, researchers have had to collect both private and public data from a variety of sources, and that took decades. Here we propose the use of one single source of data, which happens to be publicly available: Sentinel-2 satellite imagery. In particular, since the first two conditions (diversity of land use and small block sizes) are visible to the naked eye from satellite imagery, we tested whether we could automatically extract them with a state-of-the-art deep-learning framework and whether, in the end, the extracted features could predict vitality. In six Italian cities for which we had call data records, we found that our framework is able to explain on average 55% of the variance in urban vitality extracted from those records.
Characterising User Content on a Multi-lingual Social Network
Apr 23, 2020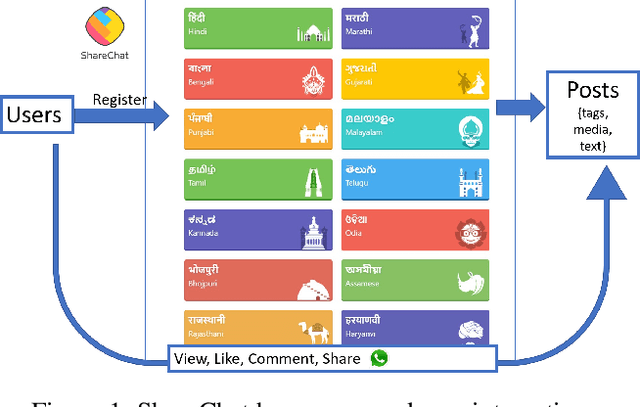
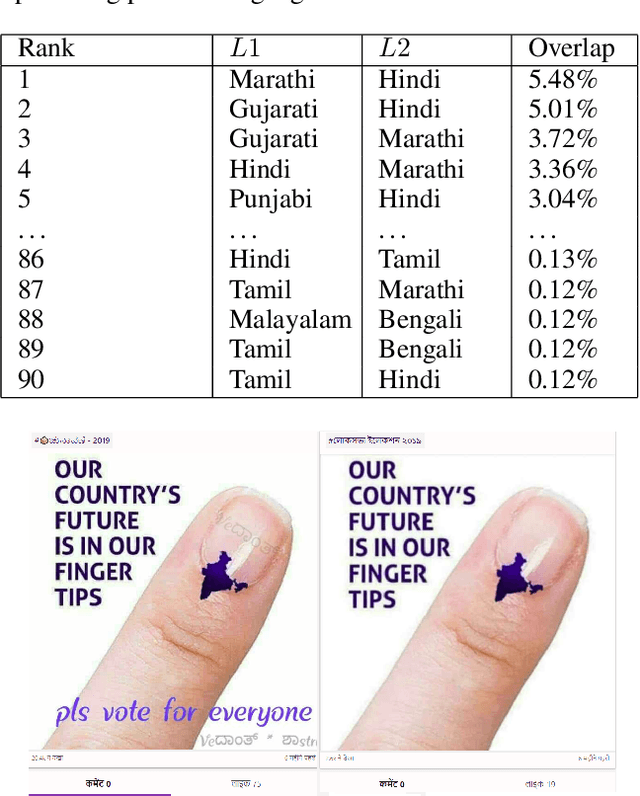

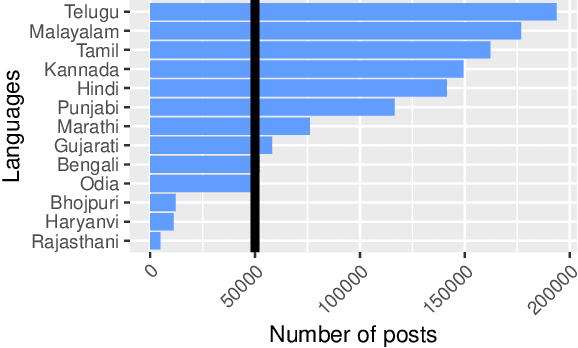
Social media has been on the vanguard of political information diffusion in the 21st century. Most studies that look into disinformation, political influence and fake-news focus on mainstream social media platforms. This has inevitably made English an important factor in our current understanding of political activity on social media. As a result, there has only been a limited number of studies into a large portion of the world, including the largest, multilingual and multi-cultural democracy: India. In this paper we present our characterisation of a multilingual social network in India called ShareChat. We collect an exhaustive dataset across 72 weeks before and during the Indian general elections of 2019, across 14 languages. We investigate the cross lingual dynamics by clustering visually similar images together, and exploring how they move across language barriers. We find that Telugu, Malayalam, Tamil and Kannada languages tend to be dominant in soliciting political images (often referred to as memes), and posts from Hindi have the largest cross-lingual diffusion across ShareChat (as well as images containing text in English). In the case of images containing text that cross language barriers, we see that language translation is used to widen the accessibility. That said, we find cases where the same image is associated with very different text (and therefore meanings). This initial characterisation paves the way for more advanced pipelines to understand the dynamics of fake and political content in a multi-lingual and non-textual setting.