 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Your Location Relates to Health: Variable Importance and Interpretable Machine Learning for Environmental and Sociodemographic Data
Jan 03, 2025



Health outcomes depend on complex environmental and sociodemographic factors whose effects change over location and time. Only recently has fine-grained spatial and temporal data become available to study these effects, namely the MEDSAT dataset of English health, environmental, and sociodemographic information. Leveraging this new resource, we use a variety of variable importance techniques to robustly identify the most informative predictors across multiple health outcomes. We then develop an interpretable machine learning framework based on Generalized Additive Models (GAMs) and Multiscale Geographically Weighted Regression (MGWR) to analyze both local and global spatial dependencies of each variable on various health outcomes. Our findings identify NO2 as a global predictor for asthma, hypertension, and anxiety, alongside other outcome-specific predictors related to occupation, marriage, and vegetation. Regional analyses reveal local variations with air pollution and solar radiation, with notable shifts during COVID. This comprehensive approach provides actionable insights for addressing health disparities, and advocates for the integration of interpretable machine learning in public health.
Co-designing an AI Impact Assessment Report Template with AI Practitioners and AI Compliance Experts
Jul 24, 2024



In the evolving landscape of AI regulation, it is crucial for companies to conduct impact assessments and document their compliance through comprehensive reports. However, current reports lack grounding in regulations and often focus on specific aspects like privacy in relation to AI systems, without addressing the real-world uses of these systems. Moreover, there is no systematic effort to design and evaluate these reports with both AI practitioners and AI compliance experts. To address this gap, we conducted an iterative co-design process with 14 AI practitioners and 6 AI compliance experts and proposed a template for impact assessment reports grounded in the EU AI Act, NIST's AI Risk Management Framework, and ISO 42001 AI Management System. We evaluated the template by producing an impact assessment report for an AI-based meeting companion at a major tech company. A user study with 8 AI practitioners from the same company and 5 AI compliance experts from industry and academia revealed that our template effectively provides necessary information for impact assessments and documents the broad impacts of AI systems. Participants envisioned using the template not only at the pre-deployment stage for compliance but also as a tool to guide the design stage of AI uses.
Dream Content Discovery from Reddit with an Unsupervised Mixed-Method Approach
Jul 09, 2023



Dreaming is a fundamental but not fully understood part of human experience that can shed light on our thought patterns. Traditional dream analysis practices, while popular and aided by over 130 unique scales and rating systems, have limitations. Mostly based on retrospective surveys or lab studies, they struggle to be applied on a large scale or to show the importance and connections between different dream themes. To overcome these issues, we developed a new, data-driven mixed-method approach for identifying topics in free-form dream reports through natural language processing. We tested this method on 44,213 dream reports from Reddit's r/Dreams subreddit, where we found 217 topics, grouped into 22 larger themes: the most extensive collection of dream topics to date. We validated our topics by comparing it to the widely-used Hall and van de Castle scale. Going beyond traditional scales, our method can find unique patterns in different dream types (like nightmares or recurring dreams), understand topic importance and connections, and observe changes in collective dream experiences over time and around major events, like the COVID-19 pandemic and the recent Russo-Ukrainian war. We envision that the applications of our method will provide valuable insights into the intricate nature of dreaming.
Epidemic Dreams: Dreaming about health during the COVID-19 pandemic
Feb 02, 2022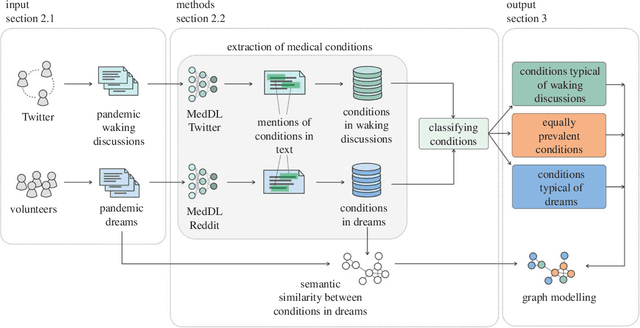
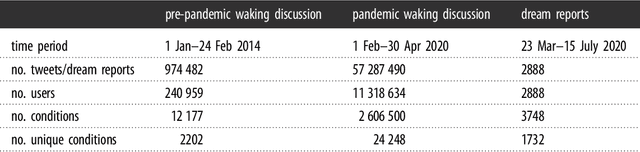
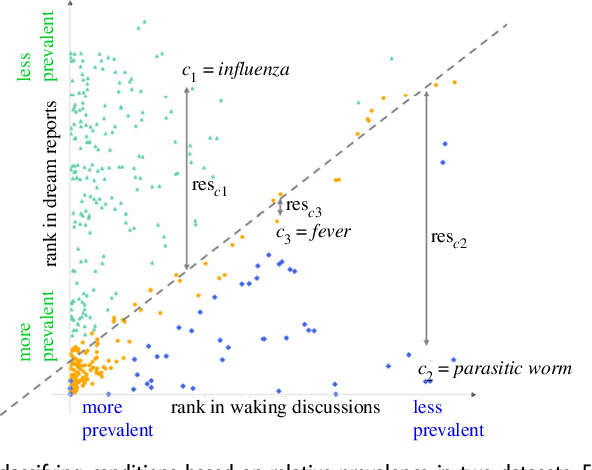
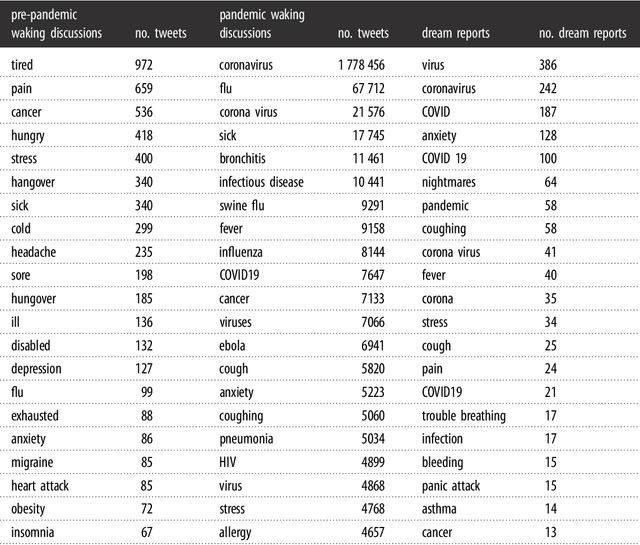
The continuity hypothesis of dreams suggests that the content of dreams is continuous with the dreamer's waking experiences. Given the unprecedented nature of the experiences during COVID-19, we studied the continuity hypothesis in the context of the pandemic. We implemented a deep-learning algorithm that can extract mentions of medical conditions from text and applied it to two datasets collected during the pandemic: 2,888 dream reports (dreaming life experiences), and 57M tweets mentioning the pandemic (waking life experiences). The health expressions common to both sets were typical COVID-19 symptoms (e.g., cough, fever, and anxiety), suggesting that dreams reflected people's real-world experiences. The health expressions that distinguished the two sets reflected differences in thought processes: expressions in waking life reflected a linear and logical thought process and, as such, described realistic symptoms or related disorders (e.g., nasal pain, SARS, H1N1); those in dreaming life reflected a thought process closer to the visual and emotional spheres and, as such, described either conditions unrelated to the virus (e.g., maggots, deformities, snakebites), or conditions of surreal nature (e.g., teeth falling out, body crumbling into sand). Our results confirm that dream reports represent an understudied yet valuable source of people's health experiences in the real world.
Jane Jacobs in the Sky: Predicting Urban Vitality with Open Satellite Data
Jan 28, 2021
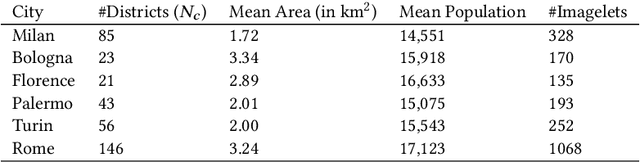

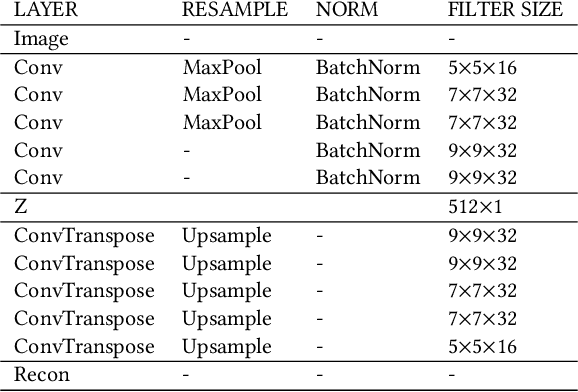
The presence of people in an urban area throughout the day -- often called 'urban vitality' -- is one of the qualities world-class cities aspire to the most, yet it is one of the hardest to achieve. Back in the 1970s, Jane Jacobs theorized urban vitality and found that there are four conditions required for the promotion of life in cities: diversity of land use, small block sizes, the mix of economic activities, and concentration of people. To build proxies for those four conditions and ultimately test Jane Jacobs's theory at scale, researchers have had to collect both private and public data from a variety of sources, and that took decades. Here we propose the use of one single source of data, which happens to be publicly available: Sentinel-2 satellite imagery. In particular, since the first two conditions (diversity of land use and small block sizes) are visible to the naked eye from satellite imagery, we tested whether we could automatically extract them with a state-of-the-art deep-learning framework and whether, in the end, the extracted features could predict vitality. In six Italian cities for which we had call data records, we found that our framework is able to explain on average 55% of the variance in urban vitality extracted from those records.
Wide-Area Land Cover Mapping with Sentinel-1 Imagery using Deep Learning Semantic Segmentation Models
Dec 11, 2019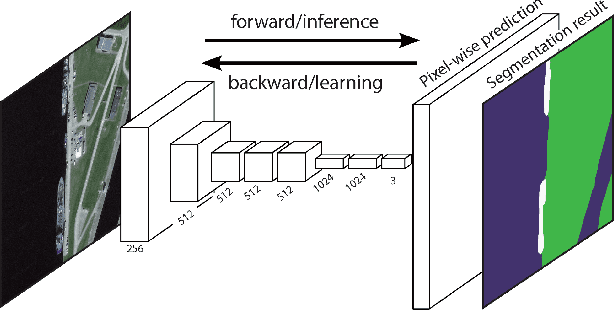
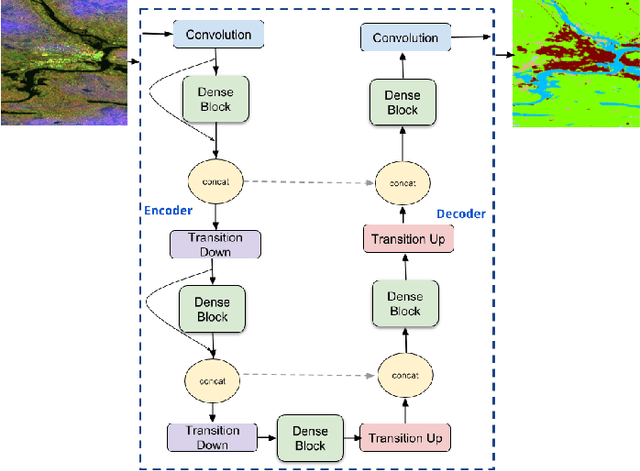
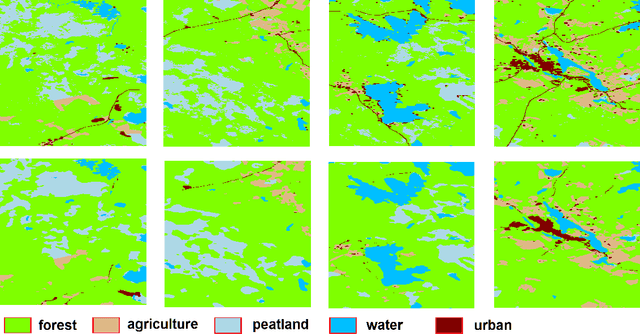
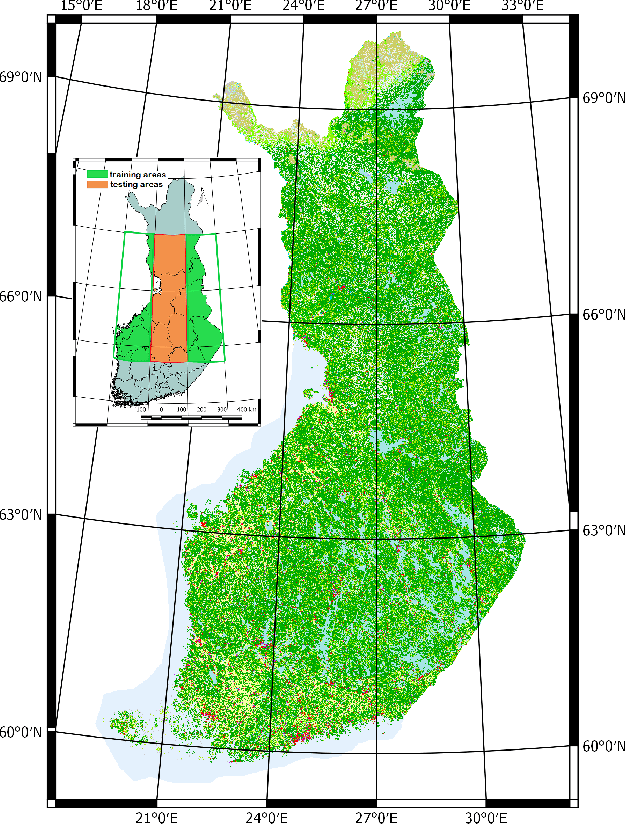
Land cover mapping and monitoring are essential for understanding the environment and the effects of human activities on it. The automatic approaches to land cover mapping are predominantly based on the traditional machine learning that requires heuristic feature design. Such approaches are relatively slow and often suitable only for a particular type of satellite sensor or geographical area. Recently, deep learning has outperformed traditional machine learning approaches on a range of image processing tasks including image classification and segmentation. In this study, we demonstrated the suitability of deep learning models for wide-area land cover mapping using satellite C-band SAR images. We used a set of 14 ESA Sentinel-1 scenes acquired during the summer season in Finland representative of the land cover in the country. These imageries were used as an input to seven state-of-the-art deep-learning models for semantic segmentation, namely U-Net, DeepLabV3+, PSPNet, BiSeNet, SegNet, FC-DenseNet, and FRRN-B. These models were pre-trained on the ImageNet dataset and further fine-tuned in this study. CORINE land cover map produced by the Finnish Environment Institute was used as a reference, and the models were trained to distinguish between 5 Level-1 CORINE classes. Upon the evaluation and benchmarking, we found that all the models demonstrated solid performance, with the top FC-DenseNet model achieving an overall accuracy of 90.7%. These results indicate the suitability of deep learning methods to support efficient wide-area mapping using satellite SAR imagery.
Semantic homophily in online communication: evidence from Twitter
Mar 20, 2017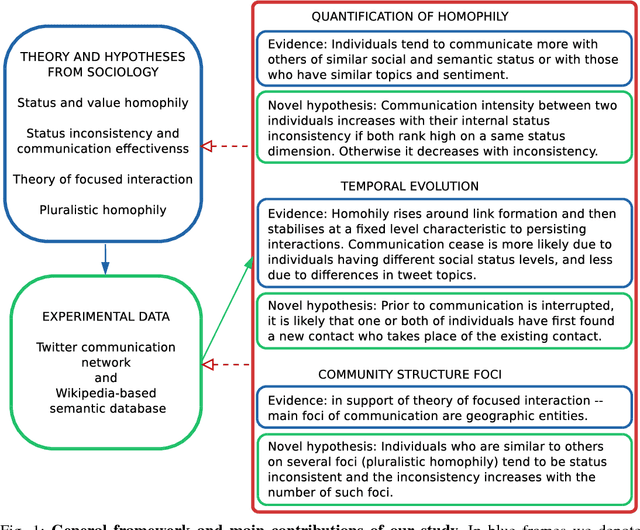

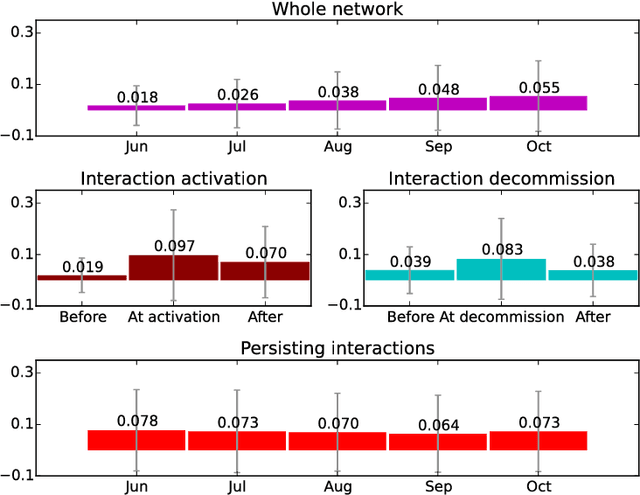
People are observed to assortatively connect on a set of traits. This phenomenon, termed assortative mixing or sometimes homophily, can be quantified through assortativity coefficient in social networks. Uncovering the exact causes of strong assortative mixing found in social networks has been a research challenge. Among the main suggested causes from sociology are the tendency of similar individuals to connect (often itself referred as homophily) and the social influence among already connected individuals. An important question to researchers and in practice can be tackled, as we present here: understanding the exact mechanisms of interplay between these tendencies and the underlying social network structure. Namely, in addition to the mentioned assortativity coefficient, there are several other static and temporal network properties and substructures that can be linked to the tendencies of homophily and social influence in the social network and we herein investigate those. Concretely, we tackle a computer-mediated \textit{communication network} (based on Twitter mentions) and a particular type of assortative mixing that can be inferred from the semantic features of communication content that we term \textit{semantic homophily}. Our work, to the best of our knowledge, is the first to offer an in-depth analysis on semantic homophily in a communication network and the interplay between them. We quantify diverse levels of semantic homophily, identify the semantic aspects that are the drivers of observed homophily, show insights in its temporal evolution and finally, we present its intricate interplay with the communication network on Twitter. By analyzing these mechanisms we increase understanding on what are the semantic aspects that shape and how they shape the human computer-mediated communication.