 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"If You're Very Clever, No One Knows You've Used It": The Social Dynamics of Developing Generative AI Literacy in the Workplace
Feb 01, 2026Generative AI (GenAI) tools are rapidly transforming knowledge work, making AI literacy a critical priority for organizations. However, research on AI literacy lacks empirical insight into how knowledge workers' beliefs around GenAI literacy are shaped by the social dynamics of the workplace, and how workers learn to apply GenAI tools in these environments. To address this gap, we conducted in-depth interviews with 19 knowledge workers across multiple sectors to examine how they develop GenAI competencies in real-world professional contexts. We found that, while knowledge sharing from colleagues supported learning, the ability to remove cues indicating GenAI use was perceived as validation of domain expertise. These behaviours ultimately reduced opportunities for learning via knowledge sharing and undermined transparency. To advance workplace AI literacy, we argue for fostering open dialogue, increasing visibility of user-generated knowledge, and greater emphasis on the benefits of collaborative learning for navigating rapid technological developments.
The Hall of AI Fears and Hopes: Comparing the Views of AI Influencers and those of Members of the U.S. Public Through an Interactive Platform
Apr 08, 2025AI development is shaped by academics and industry leaders - let us call them ``influencers'' - but it is unclear how their views align with those of the public. To address this gap, we developed an interactive platform that served as a data collection tool for exploring public views on AI, including their fears, hopes, and overall sense of hopefulness. We made the platform available to 330 participants representative of the U.S. population in terms of age, sex, ethnicity, and political leaning, and compared their views with those of 100 AI influencers identified by Time magazine. The public fears AI getting out of control, while influencers emphasize regulation, seemingly to deflect attention from their alleged focus on monetizing AI's potential. Interestingly, the views of AI influencers from underrepresented groups such as women and people of color often differ from the views of underrepresented groups in the public.
Co-designing an AI Impact Assessment Report Template with AI Practitioners and AI Compliance Experts
Jul 24, 2024



In the evolving landscape of AI regulation, it is crucial for companies to conduct impact assessments and document their compliance through comprehensive reports. However, current reports lack grounding in regulations and often focus on specific aspects like privacy in relation to AI systems, without addressing the real-world uses of these systems. Moreover, there is no systematic effort to design and evaluate these reports with both AI practitioners and AI compliance experts. To address this gap, we conducted an iterative co-design process with 14 AI practitioners and 6 AI compliance experts and proposed a template for impact assessment reports grounded in the EU AI Act, NIST's AI Risk Management Framework, and ISO 42001 AI Management System. We evaluated the template by producing an impact assessment report for an AI-based meeting companion at a major tech company. A user study with 8 AI practitioners from the same company and 5 AI compliance experts from industry and academia revealed that our template effectively provides necessary information for impact assessments and documents the broad impacts of AI systems. Participants envisioned using the template not only at the pre-deployment stage for compliance but also as a tool to guide the design stage of AI uses.
WEIRD ICWSM: How Western, Educated, Industrialized, Rich, and Democratic is Social Computing Research?
Jun 11, 2024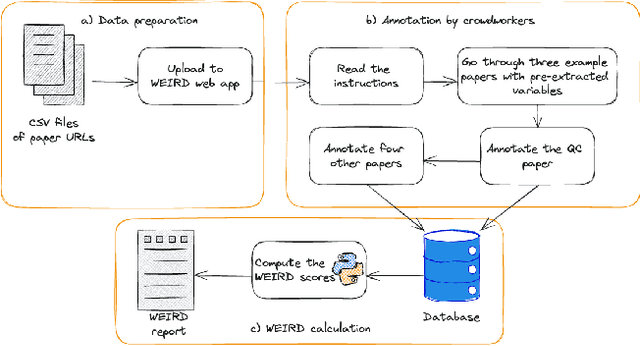


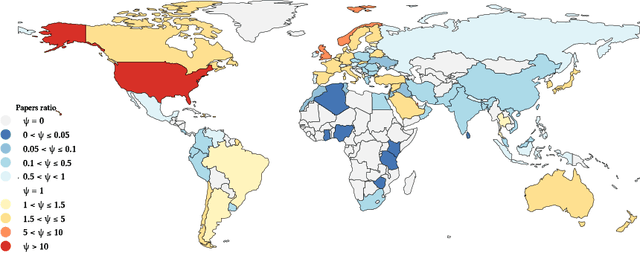
Much of the research in social computing analyzes data from social media platforms, which may inherently carry biases. An overlooked source of such bias is the over-representation of WEIRD (Western, Educated, Industrialized, Rich, and Democratic) populations, which might not accurately mirror the global demographic diversity. We evaluated the dependence on WEIRD populations in research presented at the AAAI ICWSM conference; the only venue whose proceedings are fully dedicated to social computing research. We did so by analyzing 494 papers published from 2018 to 2022, which included full research papers, dataset papers and posters. After filtering out papers that analyze synthetic datasets or those lacking clear country of origin, we were left with 420 papers from which 188 participants in a crowdsourcing study with full manual validation extracted data for the WEIRD scores computation. This data was then used to adapt existing WEIRD metrics to be applicable for social media data. We found that 37% of these papers focused solely on data from Western countries. This percentage is significantly less than the percentages observed in research from CHI (76%) and FAccT (84%) conferences, suggesting a greater diversity of dataset origins within ICWSM. However, the studies at ICWSM still predominantly examine populations from countries that are more Educated, Industrialized, and Rich in comparison to those in FAccT, with a special note on the 'Democratic' variable reflecting political freedoms and rights. This points out the utility of social media data in shedding light on findings from countries with restricted political freedoms. Based on these insights, we recommend extensions of current "paper checklists" to include considerations about the WEIRD bias and call for the community to broaden research inclusivity by encouraging the use of diverse datasets from underrepresented regions.
How Western, Educated, Industrialized, Rich, and Democratic is Social Computing Research?
Jun 04, 2024Much of the research in social computing analyzes data from social media platforms, which may inherently carry biases. An overlooked source of such bias is the over-representation of WEIRD (Western, Educated, Industrialized, Rich, and Democratic) populations, which might not accurately mirror the global demographic diversity. We evaluated the dependence on WEIRD populations in research presented at the AAAI ICWSM conference; the only venue whose proceedings are fully dedicated to social computing research. We did so by analyzing 494 papers published from 2018 to 2022, which included full research papers, dataset papers and posters. After filtering out papers that analyze synthetic datasets or those lacking clear country of origin, we were left with 420 papers from which 188 participants in a crowdsourcing study with full manual validation extracted data for the WEIRD scores computation. This data was then used to adapt existing WEIRD metrics to be applicable for social media data. We found that 37% of these papers focused solely on data from Western countries. This percentage is significantly less than the percentages observed in research from CHI (76%) and FAccT (84%) conferences, suggesting a greater diversity of dataset origins within ICWSM. However, the studies at ICWSM still predominantly examine populations from countries that are more Educated, Industrialized, and Rich in comparison to those in FAccT, with a special note on the 'Democratic' variable reflecting political freedoms and rights. This points out the utility of social media data in shedding light on findings from countries with restricted political freedoms. Based on these insights, we recommend extensions of current "paper checklists" to include considerations about the WEIRD bias and call for the community to broaden research inclusivity by encouraging the use of diverse datasets from underrepresented regions.
Evaluating Fairness in Self-supervised and Supervised Models for Sequential Data
Jan 03, 2024Self-supervised learning (SSL) has become the de facto training paradigm of large models where pre-training is followed by supervised fine-tuning using domain-specific data and labels. Hypothesizing that SSL models would learn more generic, hence less biased, representations, this study explores the impact of pre-training and fine-tuning strategies on fairness (i.e., performing equally on different demographic breakdowns). Motivated by human-centric applications on real-world timeseries data, we interpret inductive biases on the model, layer, and metric levels by systematically comparing SSL models to their supervised counterparts. Our findings demonstrate that SSL has the capacity to achieve performance on par with supervised methods while significantly enhancing fairness--exhibiting up to a 27% increase in fairness with a mere 1% loss in performance through self-supervision. Ultimately, this work underscores SSL's potential in human-centric computing, particularly high-stakes, data-scarce application domains like healthcare.
FairComp: Workshop on Fairness and Robustness in Machine Learning for Ubiquitous Computing
Sep 22, 2023How can we ensure that Ubiquitous Computing (UbiComp) research outcomes are both ethical and fair? While fairness in machine learning (ML) has gained traction in recent years, fairness in UbiComp remains unexplored. This workshop aims to discuss fairness in UbiComp research and its social, technical, and legal implications. From a social perspective, we will examine the relationship between fairness and UbiComp research and identify pathways to ensure that ubiquitous technologies do not cause harm or infringe on individual rights. From a technical perspective, we will initiate a discussion on data practices to develop bias mitigation approaches tailored to UbiComp research. From a legal perspective, we will examine how new policies shape our community's work and future research. We aim to foster a vibrant community centered around the topic of responsible UbiComp, while also charting a clear path for future research endeavours in this field.
Beyond Accuracy: A Critical Review of Fairness in Machine Learning for Mobile and Wearable Computing
Mar 27, 2023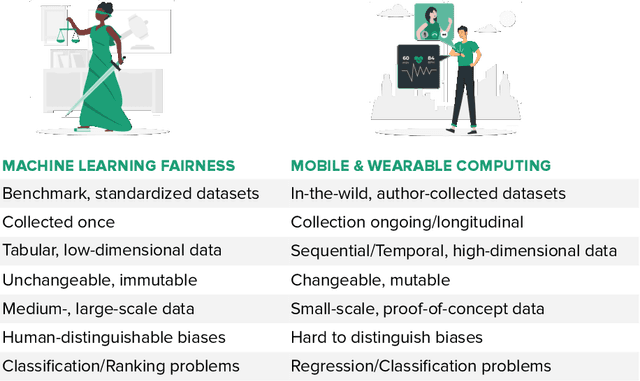
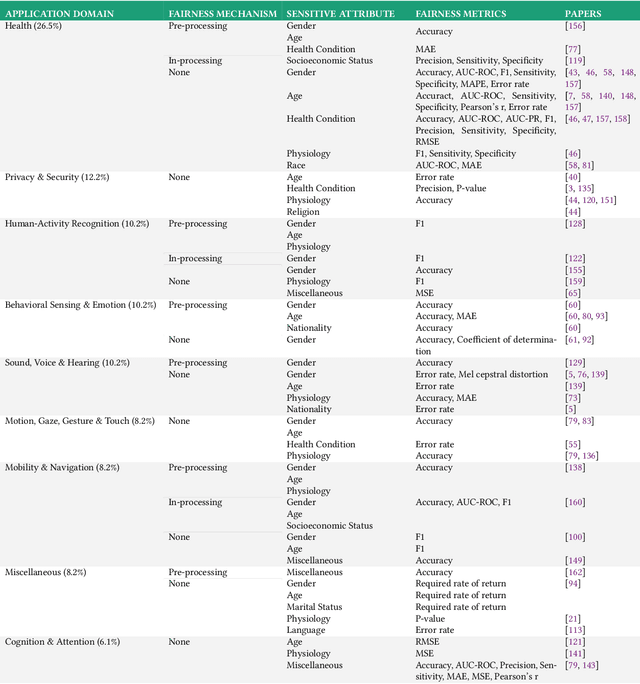
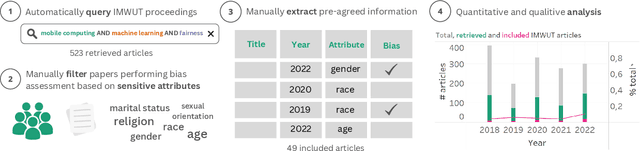
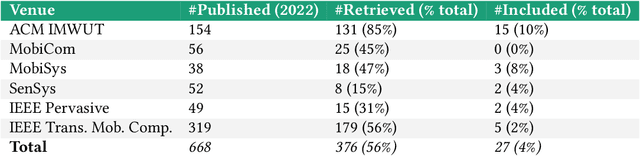
The field of mobile, wearable, and ubiquitous computing (UbiComp) is undergoing a revolutionary integration of machine learning. Devices can now diagnose diseases, predict heart irregularities, and unlock the full potential of human cognition. However, the underlying algorithms are not immune to biases with respect to sensitive attributes (e.g., gender, race), leading to discriminatory outcomes. The research communities of HCI and AI-Ethics have recently started to explore ways of reporting information about datasets to surface and, eventually, counter those biases. The goal of this work is to explore the extent to which the UbiComp community has adopted such ways of reporting and highlight potential shortcomings. Through a systematic review of papers published in the Proceedings of the ACM Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT) journal over the past 5 years (2018-2022), we found that progress on algorithmic fairness within the UbiComp community lags behind. Our findings show that only a small portion (5%) of published papers adheres to modern fairness reporting, while the overwhelming majority thereof focuses on accuracy or error metrics. In light of these findings, our work provides practical guidelines for the design and development of ubiquitous technologies that not only strive for accuracy but also for fairness.
Toward Human-Centered Responsible Artificial Intelligence: A Review of CHI Research and Industry Toolkits
Feb 26, 2023



As Artificial Intelligence (AI) continues to advance rapidly, it becomes increasingly important to consider AI's ethical and societal implications. In this paper, we present a bottom-up mapping of the current state of research in Human-Centered Responsible AI (HCR-AI) by thematically reviewing and analyzing 27 CHI research papers and 19 toolkits from industry and academia. Our results show that the current research in HCR-AI places a heavy emphasis on explainability, fairness, privacy, and security. We also found that there is space to research accountability in AI and build usable tools for non-experts to audit AI. While the CHI community has started to champion the well-being of individuals directly or indirectly impacted by AI, more research and toolkits are still required to address the long-term effects of AI on individuals, societies, and natural resources (human flourishing and sustainability).
Human-Centered Responsible Artificial Intelligence: Current & Future Trends
Feb 16, 2023In recent years, the CHI community has seen significant growth in research on Human-Centered Responsible Artificial Intelligence. While different research communities may use different terminology to discuss similar topics, all of this work is ultimately aimed at developing AI that benefits humanity while being grounded in human rights and ethics, and reducing the potential harms of AI. In this special interest group, we aim to bring together researchers from academia and industry interested in these topics to map current and future research trends to advance this important area of research by fostering collaboration and sharing ideas.