 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWEIRD ICWSM: How Western, Educated, Industrialized, Rich, and Democratic is Social Computing Research?
Paper and Code
Jun 11, 2024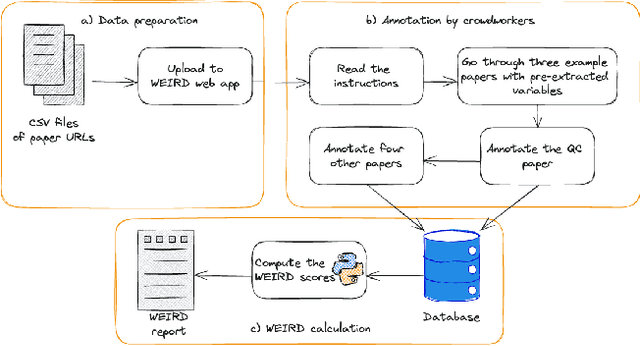


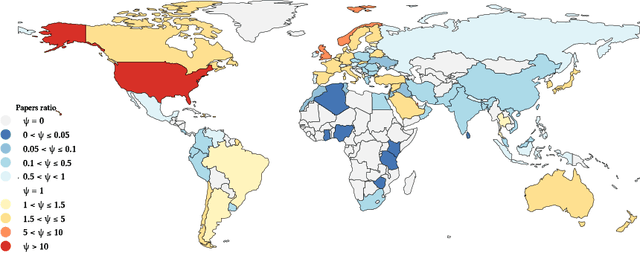
Much of the research in social computing analyzes data from social media platforms, which may inherently carry biases. An overlooked source of such bias is the over-representation of WEIRD (Western, Educated, Industrialized, Rich, and Democratic) populations, which might not accurately mirror the global demographic diversity. We evaluated the dependence on WEIRD populations in research presented at the AAAI ICWSM conference; the only venue whose proceedings are fully dedicated to social computing research. We did so by analyzing 494 papers published from 2018 to 2022, which included full research papers, dataset papers and posters. After filtering out papers that analyze synthetic datasets or those lacking clear country of origin, we were left with 420 papers from which 188 participants in a crowdsourcing study with full manual validation extracted data for the WEIRD scores computation. This data was then used to adapt existing WEIRD metrics to be applicable for social media data. We found that 37% of these papers focused solely on data from Western countries. This percentage is significantly less than the percentages observed in research from CHI (76%) and FAccT (84%) conferences, suggesting a greater diversity of dataset origins within ICWSM. However, the studies at ICWSM still predominantly examine populations from countries that are more Educated, Industrialized, and Rich in comparison to those in FAccT, with a special note on the 'Democratic' variable reflecting political freedoms and rights. This points out the utility of social media data in shedding light on findings from countries with restricted political freedoms. Based on these insights, we recommend extensions of current "paper checklists" to include considerations about the WEIRD bias and call for the community to broaden research inclusivity by encouraging the use of diverse datasets from underrepresented regions.