 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Jun 04, 2024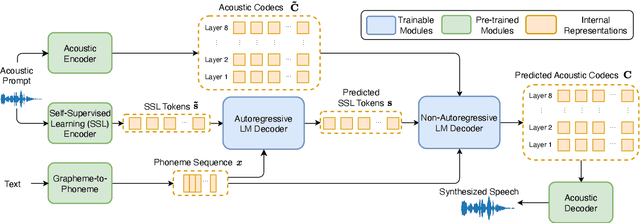
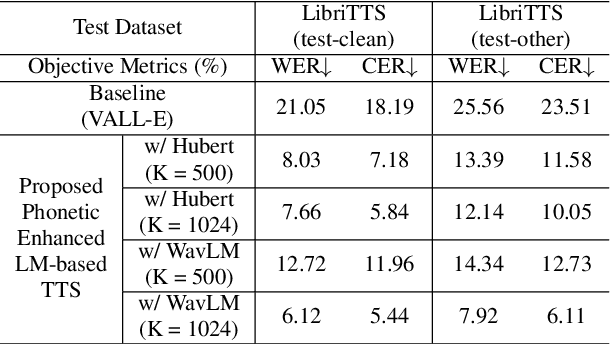
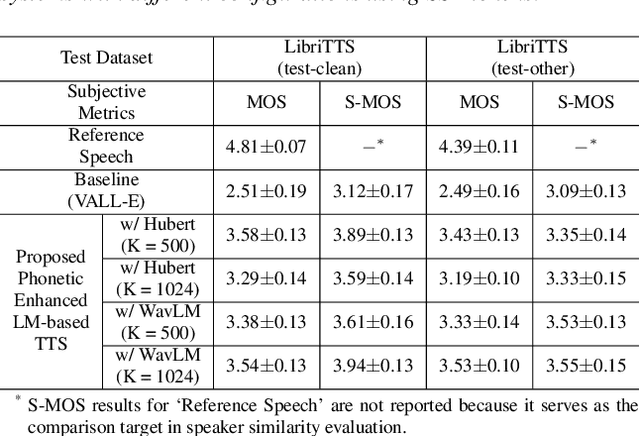
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
Semantic homophily in online communication: evidence from Twitter
Mar 20, 2017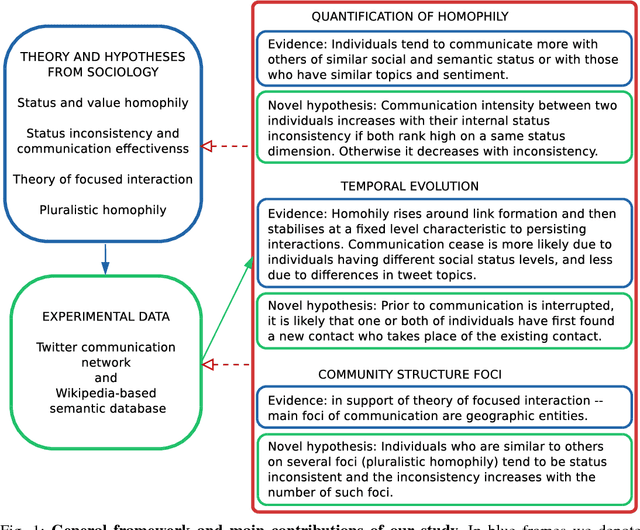

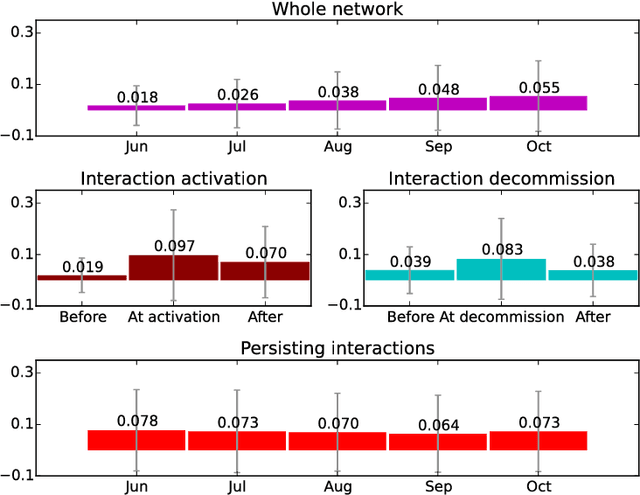
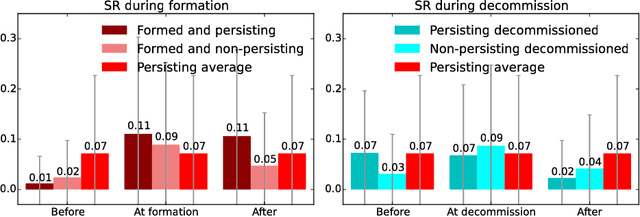
People are observed to assortatively connect on a set of traits. This phenomenon, termed assortative mixing or sometimes homophily, can be quantified through assortativity coefficient in social networks. Uncovering the exact causes of strong assortative mixing found in social networks has been a research challenge. Among the main suggested causes from sociology are the tendency of similar individuals to connect (often itself referred as homophily) and the social influence among already connected individuals. An important question to researchers and in practice can be tackled, as we present here: understanding the exact mechanisms of interplay between these tendencies and the underlying social network structure. Namely, in addition to the mentioned assortativity coefficient, there are several other static and temporal network properties and substructures that can be linked to the tendencies of homophily and social influence in the social network and we herein investigate those. Concretely, we tackle a computer-mediated \textit{communication network} (based on Twitter mentions) and a particular type of assortative mixing that can be inferred from the semantic features of communication content that we term \textit{semantic homophily}. Our work, to the best of our knowledge, is the first to offer an in-depth analysis on semantic homophily in a communication network and the interplay between them. We quantify diverse levels of semantic homophily, identify the semantic aspects that are the drivers of observed homophily, show insights in its temporal evolution and finally, we present its intricate interplay with the communication network on Twitter. By analyzing these mechanisms we increase understanding on what are the semantic aspects that shape and how they shape the human computer-mediated communication.