 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedGNN: Capturing the Links Between Urban Characteristics and Medical Prescriptions
Apr 07, 2025Understanding how urban socio-demographic and environmental factors relate with health is essential for public health and urban planning. However, traditional statistical methods struggle with nonlinear effects, while machine learning models often fail to capture geographical (nearby areas being more similar) and topological (unequal connectivity between places) effects in an interpretable way. To address this, we propose MedGNN, a spatio-topologically explicit framework that constructs a 2-hop spatial graph, integrating positional and locational node embeddings with urban characteristics in a graph neural network. Applied to MEDSAT, a comprehensive dataset covering over 150 environmental and socio-demographic factors and six prescription outcomes (depression, anxiety, diabetes, hypertension, asthma, and opioids) across 4,835 Greater London neighborhoods, MedGNN improved predictions by over 25% on average compared to baseline methods. Using depression prescriptions as a case study, we analyzed graph embeddings via geographical principal component analysis, identifying findings that: align with prior research (e.g., higher antidepressant prescriptions among older and White populations), contribute to ongoing debates (e.g., greenery linked to higher and NO2 to lower prescriptions), and warrant further study (e.g., canopy evaporation correlated with fewer prescriptions). These results demonstrate MedGNN's potential, and more broadly, of carefully applied machine learning, to advance transdisciplinary public health research.
Heart Rate Extraction from Abdominal Audio Signals
Apr 21, 2023



Abdominal sounds (ABS) have been traditionally used for assessing gastrointestinal (GI) disorders. However, the assessment requires a trained medical professional to perform multiple abdominal auscultation sessions, which is resource-intense and may fail to provide an accurate picture of patients' continuous GI wellbeing. This has generated a technological interest in developing wearables for continuous capture of ABS, which enables a fuller picture of patient's GI status to be obtained at reduced cost. This paper seeks to evaluate the feasibility of extracting heart rate (HR) from such ABS monitoring devices. The collection of HR directly from these devices would enable gathering vital signs alongside GI data without the need for additional wearable devices, providing further cost benefits and improving general usability. We utilised a dataset containing 104 hours of ABS audio, collected from the abdomen using an e-stethoscope, and electrocardiogram as ground truth. Our evaluation shows for the first time that we can successfully extract HR from audio collected from a wearable on the abdomen. As heart sounds collected from the abdomen suffer from significant noise from GI and respiratory tracts, we leverage wavelet denoising for improved heart beat detection. The mean absolute error of the algorithm for average HR is 3.4 BPM with mean directional error of -1.2 BPM over the whole dataset. A comparison to photoplethysmography-based wearable HR sensors shows that our approach exhibits comparable accuracy to consumer wrist-worn wearables for average and instantaneous heart rate.
The Healthy States of America: Creating a Health Taxonomy with Social Media
Mar 01, 2021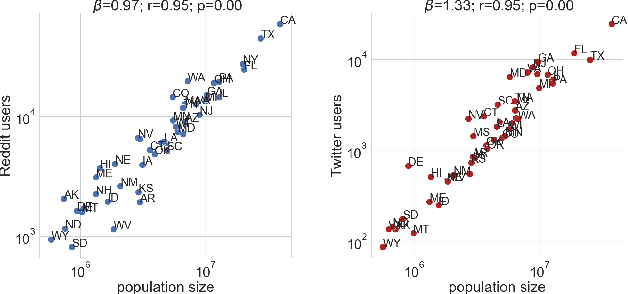
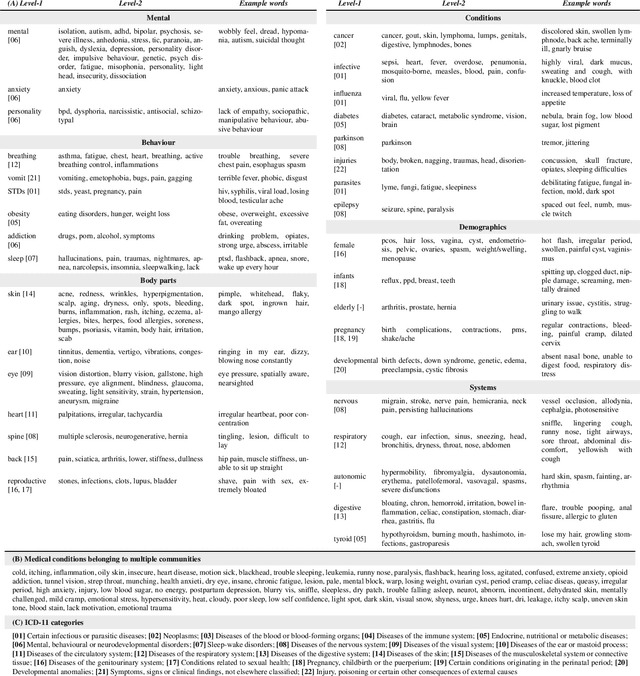
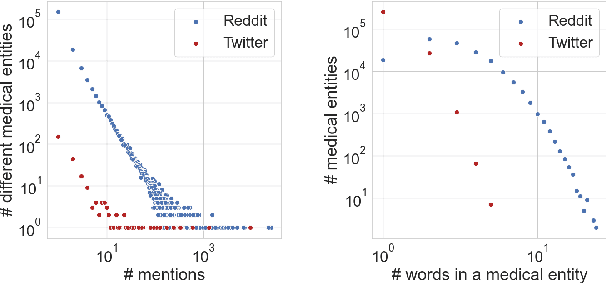
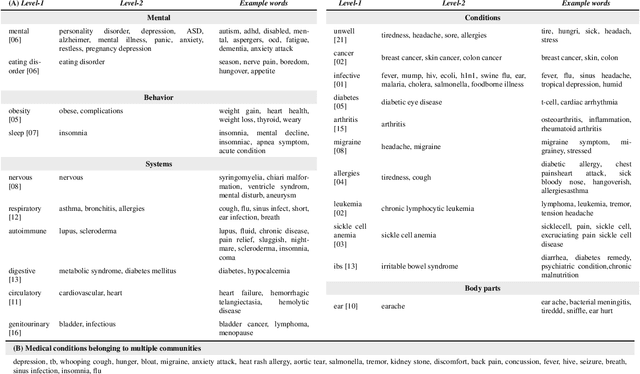
Since the uptake of social media, researchers have mined online discussions to track the outbreak and evolution of specific diseases or chronic conditions such as influenza or depression. To broaden the set of diseases under study, we developed a Deep Learning tool for Natural Language Processing that extracts mentions of virtually any medical condition or disease from unstructured social media text. With that tool at hand, we processed Reddit and Twitter posts, analyzed the clusters of the two resulting co-occurrence networks of conditions, and discovered that they correspond to well-defined categories of medical conditions. This resulted in the creation of the first comprehensive taxonomy of medical conditions automatically derived from online discussions. We validated the structure of our taxonomy against the official International Statistical Classification of Diseases and Related Health Problems (ICD-11), finding matches of our clusters with 20 official categories, out of 22. Based on the mentions of our taxonomy's sub-categories on Reddit posts geo-referenced in the U.S., we were then able to compute disease-specific health scores. As opposed to counts of disease mentions or counts with no knowledge of our taxonomy's structure, we found that our disease-specific health scores are causally linked with the officially reported prevalence of 18 conditions.