 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeart Rate Extraction from Abdominal Audio Signals
Apr 21, 2023



Abdominal sounds (ABS) have been traditionally used for assessing gastrointestinal (GI) disorders. However, the assessment requires a trained medical professional to perform multiple abdominal auscultation sessions, which is resource-intense and may fail to provide an accurate picture of patients' continuous GI wellbeing. This has generated a technological interest in developing wearables for continuous capture of ABS, which enables a fuller picture of patient's GI status to be obtained at reduced cost. This paper seeks to evaluate the feasibility of extracting heart rate (HR) from such ABS monitoring devices. The collection of HR directly from these devices would enable gathering vital signs alongside GI data without the need for additional wearable devices, providing further cost benefits and improving general usability. We utilised a dataset containing 104 hours of ABS audio, collected from the abdomen using an e-stethoscope, and electrocardiogram as ground truth. Our evaluation shows for the first time that we can successfully extract HR from audio collected from a wearable on the abdomen. As heart sounds collected from the abdomen suffer from significant noise from GI and respiratory tracts, we leverage wavelet denoising for improved heart beat detection. The mean absolute error of the algorithm for average HR is 3.4 BPM with mean directional error of -1.2 BPM over the whole dataset. A comparison to photoplethysmography-based wearable HR sensors shows that our approach exhibits comparable accuracy to consumer wrist-worn wearables for average and instantaneous heart rate.
COVID-19 Disease Progression Prediction via Audio Signals: A Longitudinal Study
Jan 04, 2022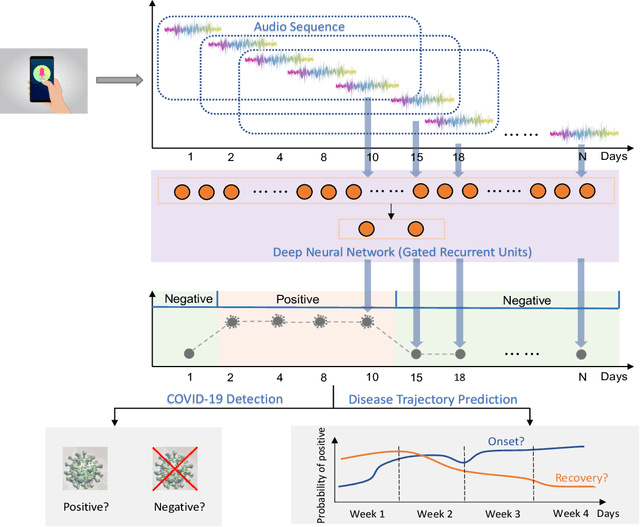
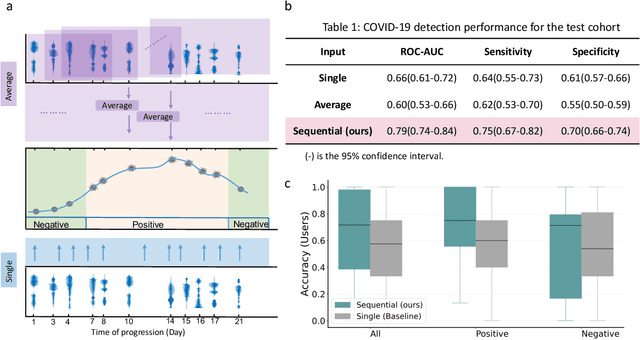
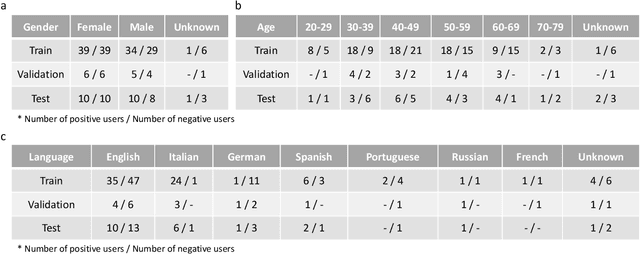
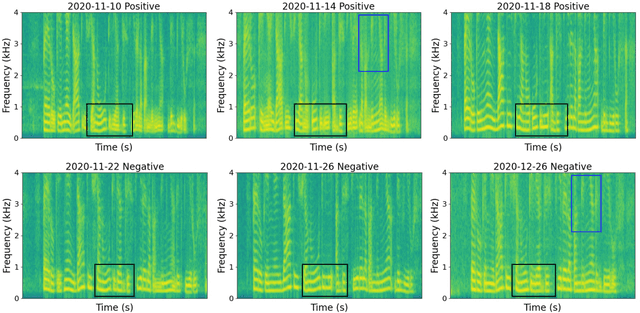
Recent work has shown the potential of the use of audio data in screening for COVID-19. However, very little exploration has been done of monitoring disease progression, especially recovery in COVID-19 through audio. Tracking disease progression characteristics and patterns of recovery could lead to tremendous insights and more timely treatment or treatment adjustment, as well as better resources management in health care systems. The primary objective of this study is to explore the potential of longitudinal audio dynamics for COVID-19 monitoring using sequential deep learning techniques, focusing on prediction of disease progression and, especially, recovery trend prediction. We analysed crowdsourced respiratory audio data from 212 individuals over 5 days to 385 days, alongside their self-reported COVID-19 test results. We first explore the benefits of capturing longitudinal dynamics of audio biomarkers for COVID-19 detection. The strong performance, yielding an AUC-ROC of 0.79, sensitivity of 0.75 and specificity of 0.70, supports the effectiveness of the approach compared to methods that do not leverage longitudinal dynamics. We further examine the predicted disease progression trajectory, which displays high consistency with the longitudinal test results with a correlation of 0.76 in the test cohort, and 0.86 in a subset of the test cohort with 12 participants who report disease recovery. Our findings suggest that monitoring COVID-19 progression via longitudinal audio data has enormous potential in the tracking of individuals' disease progression and recovery.
Earables for Detection of Bruxism: a Feasibility Study
Aug 09, 2021
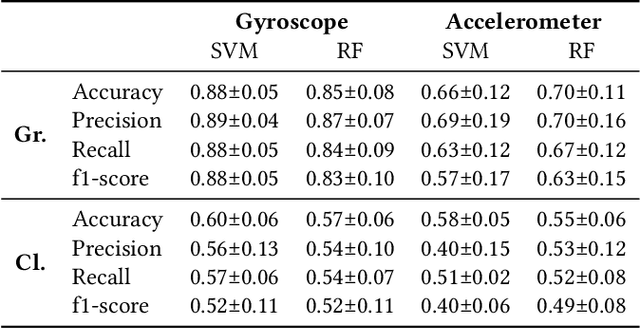
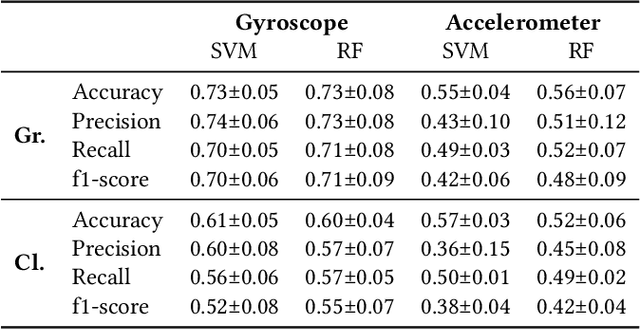

Bruxism is a disorder characterised by teeth grinding and clenching, and many bruxism sufferers are not aware of this disorder until their dental health professional notices permanent teeth wear. Stress and anxiety are often listed among contributing factors impacting bruxism exacerbation, which may explain why the COVID-19 pandemic gave rise to a bruxism epidemic. It is essential to develop tools allowing for the early diagnosis of bruxism in an unobtrusive manner. This work explores the feasibility of detecting bruxism-related events using earables in a mimicked in-the-wild setting. Using inertial measurement unit for data collection, we utilise traditional machine learning for teeth grinding and clenching detection. We observe superior performance of models based on gyroscope data, achieving an 88% and 66% accuracy on grinding and clenching activities, respectively, in a controlled environment, and 76% and 73% on grinding and clenching, respectively, in an in-the-wild environment.
Segmentation-free Heart Pathology Detection Using Deep Learning
Aug 09, 2021

Cardiovascular (CV) diseases are the leading cause of death in the world, and auscultation is typically an essential part of a cardiovascular examination. The ability to diagnose a patient based on their heart sounds is a rather difficult skill to master. Thus, many approaches for automated heart auscultation have been explored. However, most of the previously proposed methods involve a segmentation step, the performance of which drops significantly for high pulse rates or noisy signals. In this work, we propose a novel segmentation-free heart sound classification method. Specifically, we apply discrete wavelet transform to denoise the signal, followed by feature extraction and feature reduction. Then, Support Vector Machines and Deep Neural Networks are utilised for classification. On the PASCAL heart sound dataset our approach showed superior performance compared to others, achieving 81% and 96% precision on normal and murmur classes, respectively. In addition, for the first time, the data were further explored under a user-independent setting, where the proposed method achieved 92% and 86% precision on normal and murmur, demonstrating the potential of enabling automatic murmur detection for practical use.
Sounds of COVID-19: exploring realistic performance of audio-based digital testing
Jun 29, 2021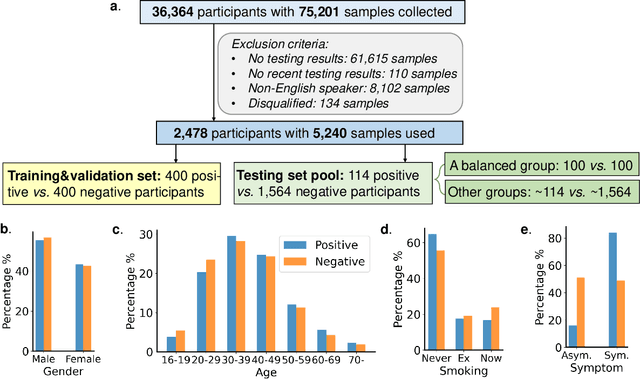



Researchers have been battling with the question of how we can identify Coronavirus disease (COVID-19) cases efficiently, affordably and at scale. Recent work has shown how audio based approaches, which collect respiratory audio data (cough, breathing and voice) can be used for testing, however there is a lack of exploration of how biases and methodological decisions impact these tools' performance in practice. In this paper, we explore the realistic performance of audio-based digital testing of COVID-19. To investigate this, we collected a large crowdsourced respiratory audio dataset through a mobile app, alongside recent COVID-19 test result and symptoms intended as a ground truth. Within the collected dataset, we selected 5,240 samples from 2,478 participants and split them into different participant-independent sets for model development and validation. Among these, we controlled for potential confounding factors (such as demographics and language). The unbiased model takes features extracted from breathing, coughs, and voice signals as predictors and yields an AUC-ROC of 0.71 (95\% CI: 0.65$-$0.77). We further explore different unbalanced distributions to show how biases and participant splits affect performance. Finally, we discuss how the realistic model presented could be integrated in clinical practice to realize continuous, ubiquitous, sustainable and affordable testing at population scale.