 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID-19 Disease Progression Prediction via Audio Signals: A Longitudinal Study
Jan 04, 2022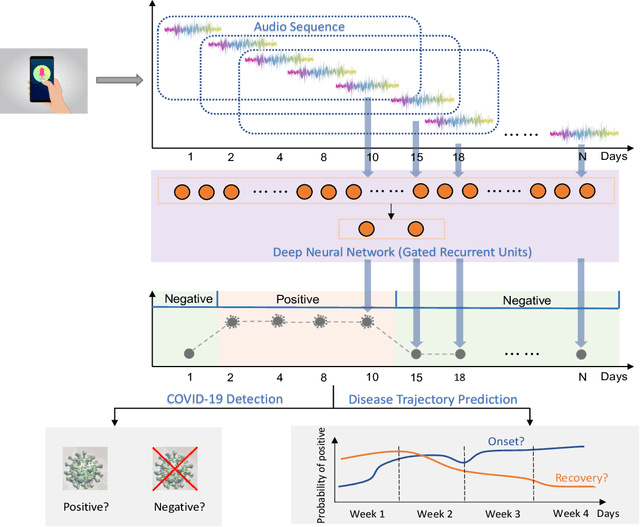
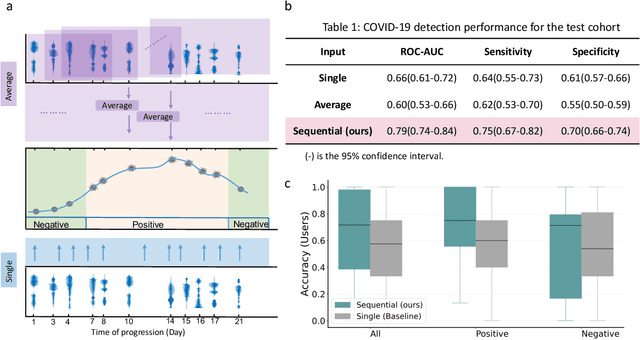
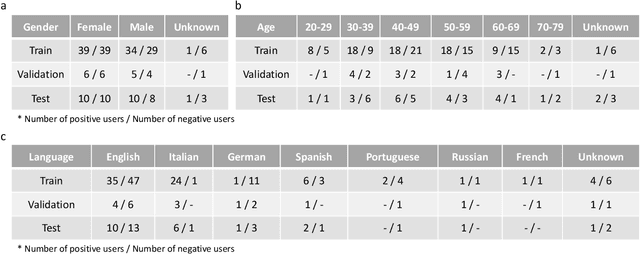
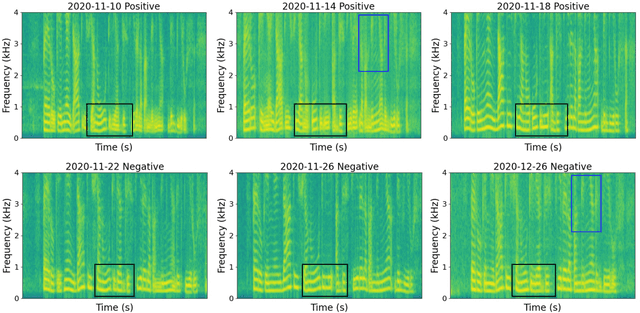
Recent work has shown the potential of the use of audio data in screening for COVID-19. However, very little exploration has been done of monitoring disease progression, especially recovery in COVID-19 through audio. Tracking disease progression characteristics and patterns of recovery could lead to tremendous insights and more timely treatment or treatment adjustment, as well as better resources management in health care systems. The primary objective of this study is to explore the potential of longitudinal audio dynamics for COVID-19 monitoring using sequential deep learning techniques, focusing on prediction of disease progression and, especially, recovery trend prediction. We analysed crowdsourced respiratory audio data from 212 individuals over 5 days to 385 days, alongside their self-reported COVID-19 test results. We first explore the benefits of capturing longitudinal dynamics of audio biomarkers for COVID-19 detection. The strong performance, yielding an AUC-ROC of 0.79, sensitivity of 0.75 and specificity of 0.70, supports the effectiveness of the approach compared to methods that do not leverage longitudinal dynamics. We further examine the predicted disease progression trajectory, which displays high consistency with the longitudinal test results with a correlation of 0.76 in the test cohort, and 0.86 in a subset of the test cohort with 12 participants who report disease recovery. Our findings suggest that monitoring COVID-19 progression via longitudinal audio data has enormous potential in the tracking of individuals' disease progression and recovery.
Sounds of COVID-19: exploring realistic performance of audio-based digital testing
Jun 29, 2021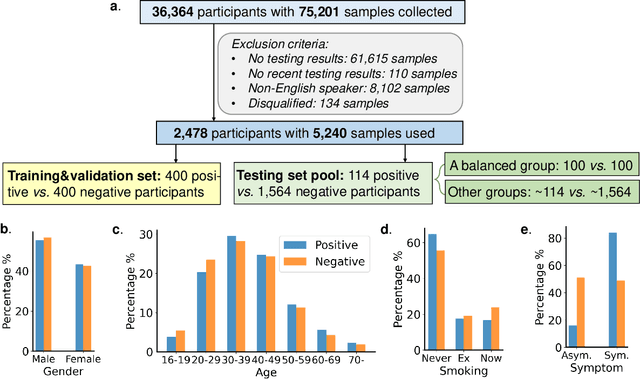



Researchers have been battling with the question of how we can identify Coronavirus disease (COVID-19) cases efficiently, affordably and at scale. Recent work has shown how audio based approaches, which collect respiratory audio data (cough, breathing and voice) can be used for testing, however there is a lack of exploration of how biases and methodological decisions impact these tools' performance in practice. In this paper, we explore the realistic performance of audio-based digital testing of COVID-19. To investigate this, we collected a large crowdsourced respiratory audio dataset through a mobile app, alongside recent COVID-19 test result and symptoms intended as a ground truth. Within the collected dataset, we selected 5,240 samples from 2,478 participants and split them into different participant-independent sets for model development and validation. Among these, we controlled for potential confounding factors (such as demographics and language). The unbiased model takes features extracted from breathing, coughs, and voice signals as predictors and yields an AUC-ROC of 0.71 (95\% CI: 0.65$-$0.77). We further explore different unbalanced distributions to show how biases and participant splits affect performance. Finally, we discuss how the realistic model presented could be integrated in clinical practice to realize continuous, ubiquitous, sustainable and affordable testing at population scale.