 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Data-Driven but Privacy-Conscious: Pedestrian Dataset De-identification via Full-Body Person Synthesis
Jun 22, 2023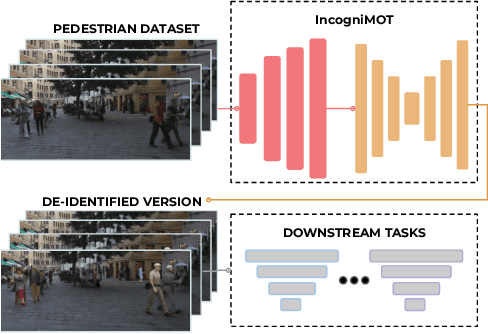

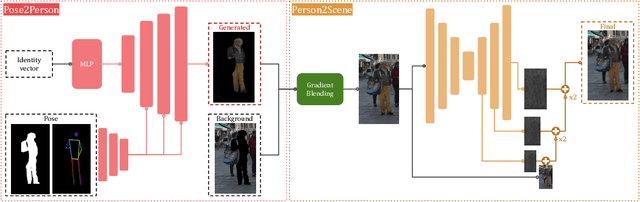

The advent of data-driven technology solutions is accompanied by an increasing concern with data privacy. This is of particular importance for human-centered image recognition tasks, such as pedestrian detection, re-identification, and tracking. To highlight the importance of privacy issues and motivate future research, we motivate and introduce the Pedestrian Dataset De-Identification (PDI) task. PDI evaluates the degree of de-identification and downstream task training performance for a given de-identification method. As a first baseline, we propose IncogniMOT, a two-stage full-body de-identification pipeline based on image synthesis via generative adversarial networks. The first stage replaces target pedestrians with synthetic identities. To improve downstream task performance, we then apply stage two, which blends and adapts the synthetic image parts into the data. To demonstrate the effectiveness of IncogniMOT, we generate a fully de-identified version of the MOT17 pedestrian tracking dataset and analyze its application as training data for pedestrian re-identification, detection, and tracking models. Furthermore, we show how our data is able to narrow the synthetic-to-real performance gap in a privacy-conscious manner.
AugLy: Data Augmentations for Robustness
Jan 17, 2022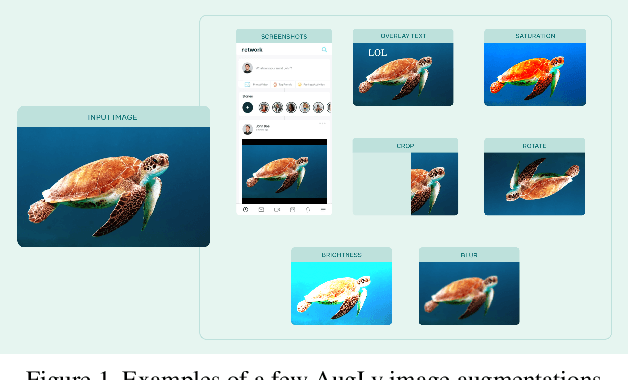
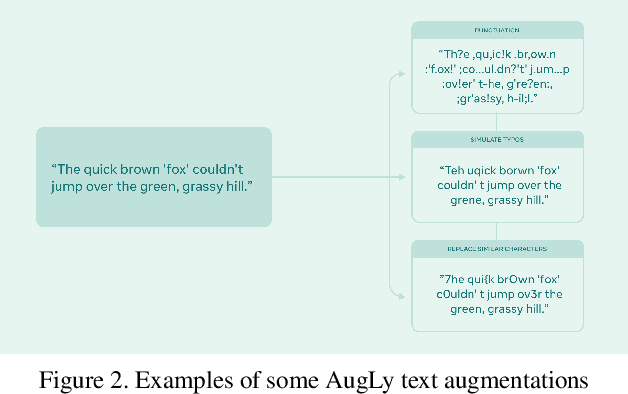
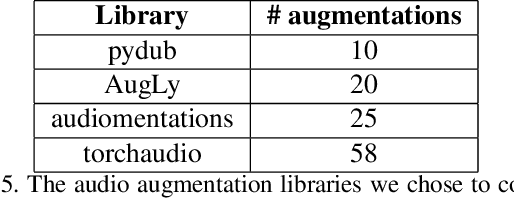
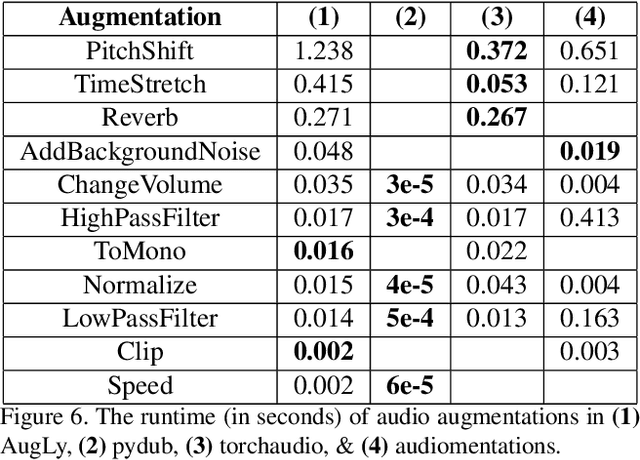
We introduce AugLy, a data augmentation library with a focus on adversarial robustness. AugLy provides a wide array of augmentations for multiple modalities (audio, image, text, & video). These augmentations were inspired by those that real users perform on social media platforms, some of which were not already supported by existing data augmentation libraries. AugLy can be used for any purpose where data augmentations are useful, but it is particularly well-suited for evaluating robustness and systematically generating adversarial attacks. In this paper we present how AugLy works, benchmark it compared against existing libraries, and use it to evaluate the robustness of various state-of-the-art models to showcase AugLy's utility. The AugLy repository can be found at https://github.com/facebookresearch/AugLy.
ReNeg and Backseat Driver: Learning from Demonstration with Continuous Human Feedback
Jan 16, 2019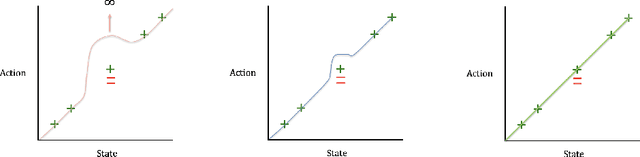
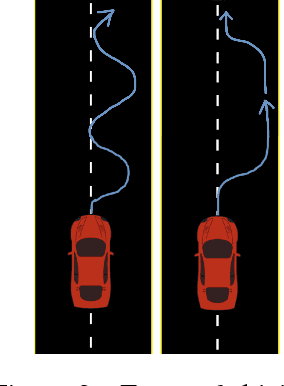
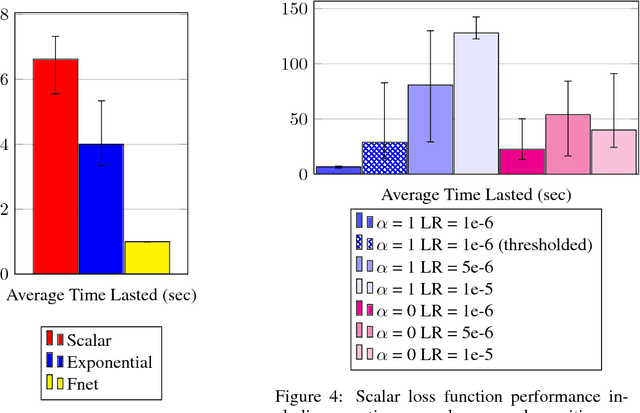
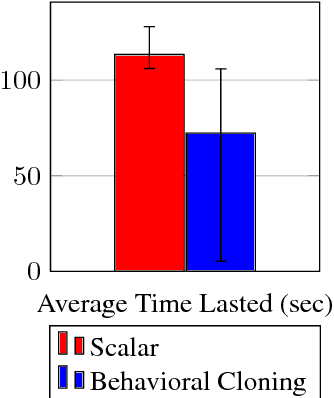
In autonomous vehicle (AV) control, allowing mistakes can be quite dangerous and costly in the real world. For this reason we investigate methods of training an AV without allowing the agent to explore and instead having a human explorer collect the data. Supervised learning has been explored for AV control, but it encounters the issue of the covariate shift. That is, training data collected from an optimal demonstration consists only of the states induced by the optimal control policy, but at runtime, the trained agent may encounter a vastly different state distribution with little relevant training data. To mitigate this issue, we have our human explorer make sub-optimal decisions. In order to have our agent not replicate these sub-optimal decisions, supervised learning requires that we either erase these actions, or replace these action with the correct action. Erasing is wasteful and replacing is difficult, since it is not easy to know the correct action without driving. We propose an alternate framework that includes continuous scalar feedback for each action, marking which actions we should replicate, which we should avoid, and how sure we are. Our framework learns continuous control from sub-optimal demonstration and evaluative feedback collected before training. We find that a human demonstrator can explore sub-optimal states in a safe manner, while still getting enough gradation to benefit learning. The collection method for data and feedback we call "Backseat Driver." We call the more general learning framework ReNeg, since it learns a regression from states to actions given negative as well as positive examples. We empirically validate several models in the ReNeg framework, testing on lane-following with limited data. We find that the best solution is a generalization of mean-squared error and outperforms supervised learning on the positive examples alone.
Neural Mesh: Introducing a Notion of Space and Conservation of Energy to Neural Networks
Jul 29, 2018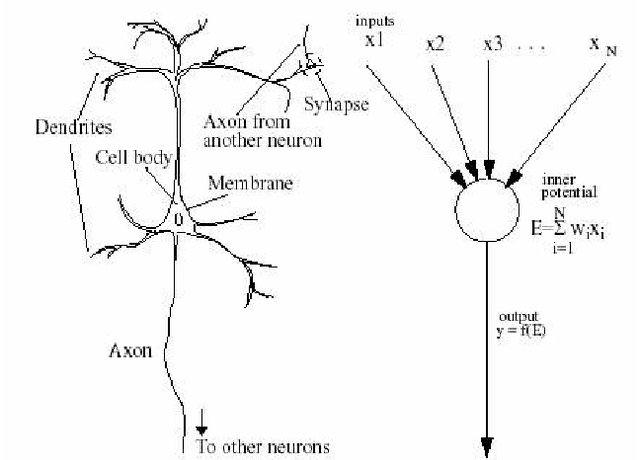

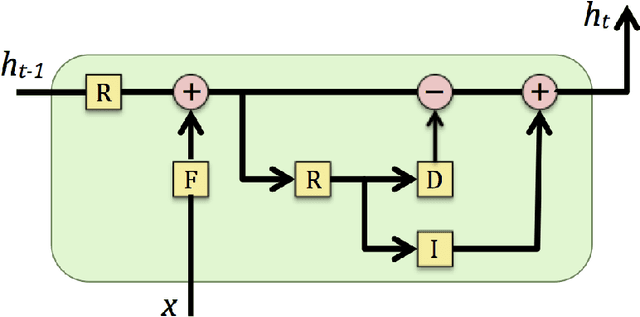
Neural networks are based on a simplified model of the brain. In this project, we wanted to relax the simplifying assumptions of a traditional neural network by making a model that more closely emulates the low level interactions of neurons. Like in an RNN, our model has a state that persists between time steps, so that the energies of neurons persist. However, unlike an RNN, our state consists of a 2 dimensional matrix, rather than a 1 dimensional vector, thereby introducing a concept of distance to other neurons within the state. In our model, neurons can only fire to adjacent neurons, as in the brain. Like in the brain, we only allow neurons to fire in a time step if they contain enough energy, or excitement. We also enforce a notion of conservation of energy, so that a neuron cannot excite its neighbors more than the excitement it already contained at that time step. Taken together, these two features allow signals in the form of activations to flow around in our network over time, making our neural mesh more closely model signals traveling through the brain the brain. Although our main goal is to design an architecture to more closely emulate the brain in the hope of having a correct internal representation of information by the time we know how to properly train a general intelligence, we did benchmark our neural mash on a specific task. We found that by increasing the runtime of the mesh, we were able to increase its accuracy without increasing the number of parameters.