 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Discriminant deterministic Uncertainty
Jul 20, 2022
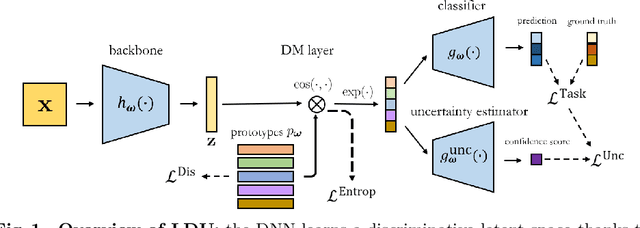
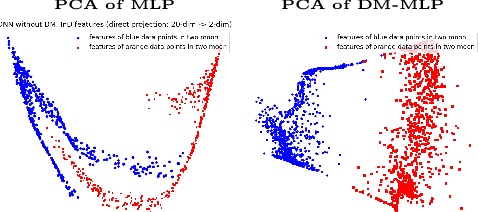
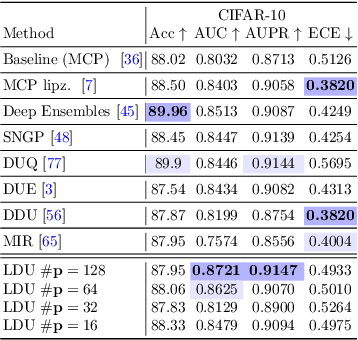
Predictive uncertainty estimation is essential for deploying Deep Neural Networks in real-world autonomous systems. However, most successful approaches are computationally intensive. In this work, we attempt to address these challenges in the context of autonomous driving perception tasks. Recently proposed Deterministic Uncertainty Methods (DUM) can only partially meet such requirements as their scalability to complex computer vision tasks is not obvious. In this work we advance a scalable and effective DUM for high-resolution semantic segmentation, that relaxes the Lipschitz constraint typically hindering practicality of such architectures. We learn a discriminant latent space by leveraging a distinction maximization layer over an arbitrarily-sized set of trainable prototypes. Our approach achieves competitive results over Deep Ensembles, the state-of-the-art for uncertainty prediction, on image classification, segmentation and monocular depth estimation tasks. Our code is available at https://github.com/ENSTA-U2IS/LDU
Encoding the latent posterior of Bayesian Neural Networks for uncertainty quantification
Dec 04, 2020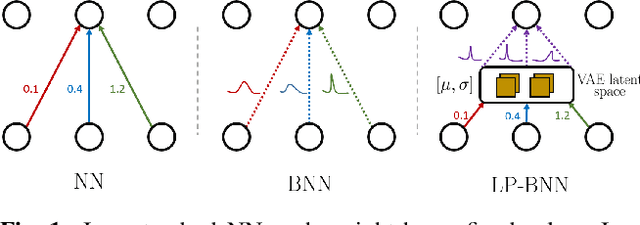
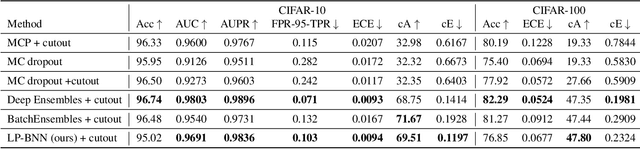
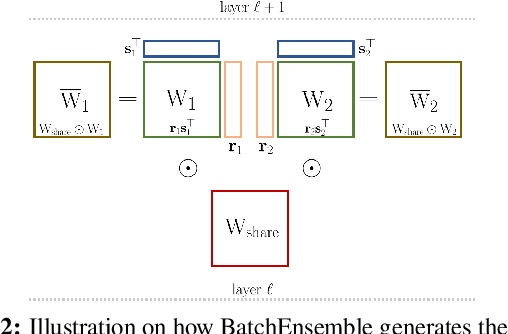
Bayesian neural networks (BNNs) have been long considered an ideal, yet unscalable solution for improving the robustness and the predictive uncertainty of deep neural networks. While they could capture more accurately the posterior distribution of the network parameters, most BNN approaches are either limited to small networks or rely on constraining assumptions such as parameter independence. These drawbacks have enabled prominence of simple, but computationally heavy approaches such as Deep Ensembles, whose training and testing costs increase linearly with the number of networks. In this work we aim for efficient deep BNNs amenable to complex computer vision architectures, e.g. ResNet50 DeepLabV3+, and tasks, e.g. semantic segmentation, with fewer assumptions on the parameters. We achieve this by leveraging variational autoencoders (VAEs) to learn the interaction and the latent distribution of the parameters at each network layer. Our approach, Latent-Posterior BNN (LP-BNN), is compatible with the recent BatchEnsemble method, leading to highly efficient ({in terms of computation and} memory during both training and testing) ensembles. LP-BNN s attain competitive results across multiple metrics in several challenging benchmarks for image classification, semantic segmentation and out-of-distribution detection.
One Versus all for deep Neural Network Incertitude quantification
Jun 01, 2020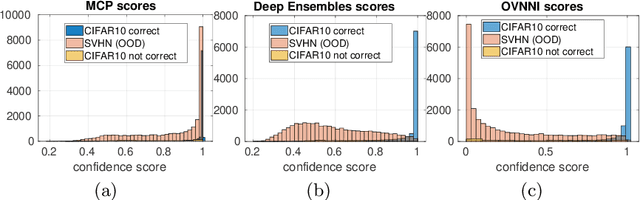
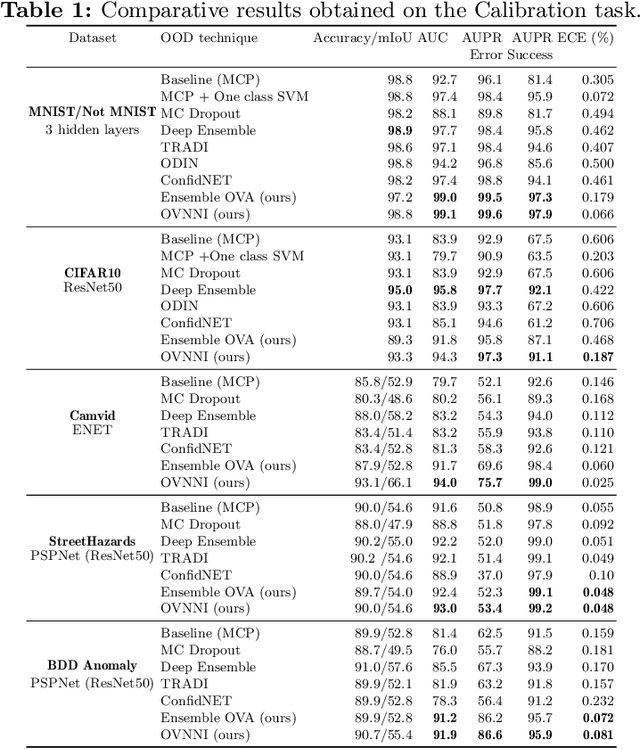
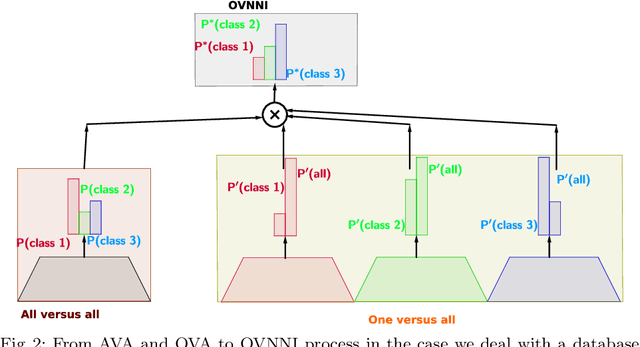
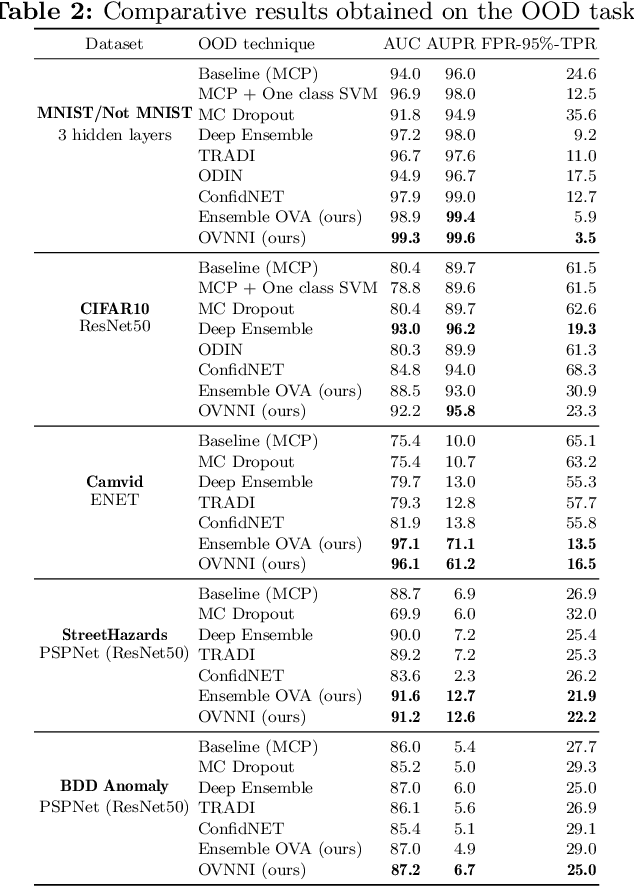
Deep neural networks (DNNs) are powerful learning models yet their results are not always reliable. This is due to the fact that modern DNNs are usually uncalibrated and we cannot characterize their epistemic uncertainty. In this work, we propose a new technique to quantify the epistemic uncertainty of data easily. This method consists in mixing the predictions of an ensemble of DNNs trained to classify One class vs All the other classes (OVA) with predictions from a standard DNN trained to perform All vs All (AVA) classification. On the one hand, the adjustment provided by the AVA DNN to the score of the base classifiers allows for a more fine-grained inter-class separation. On the other hand, the two types of classifiers enforce mutually their detection of out-of-distribution (OOD) samples, circumventing entirely the requirement of using such samples during training. Our method achieves state of the art performance in quantifying OOD data across multiple datasets and architectures while requiring little hyper-parameter tuning.
TRADI: Tracking deep neural network weight distributions
Dec 26, 2019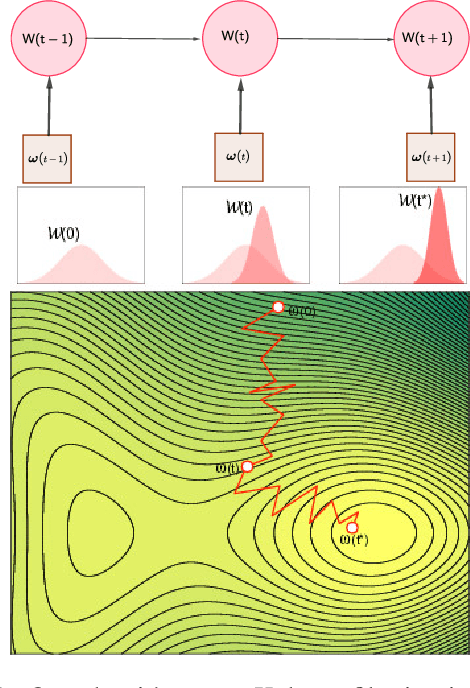
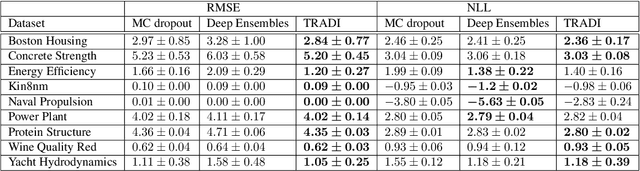
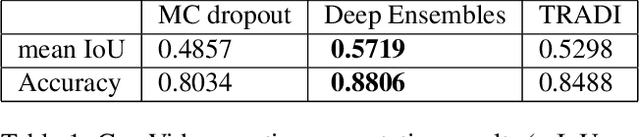

During training, the weights of a Deep Neural Network (DNN) are optimized from a random initialization towards a nearly optimum value minimizing a loss function. Only this final state of the weights is typically kept for testing, while the wealth of information on the geometry of the weight space, accumulated over the descent towards the minimum is discarded. In this work we propose to make use of this knowledge and leverage it for computing the distributions of the weights of the DNN. This can be further used for estimating the epistemic uncertainty of the DNN by sampling an ensemble of networks from these distributions. To this end we introduce a method for tracking the trajectory of the weights during optimization, that does not require any changes in the architecture nor on the training procedure. We evaluate our method on standard classification and regression benchmarks, and on out-of-distribution detection for classification and semantic segmentation. We achieve competitive results, while preserving computational efficiency in comparison to other popular approaches.
DBN-Based Combinatorial Resampling for Articulated Object Tracking
Oct 16, 2012
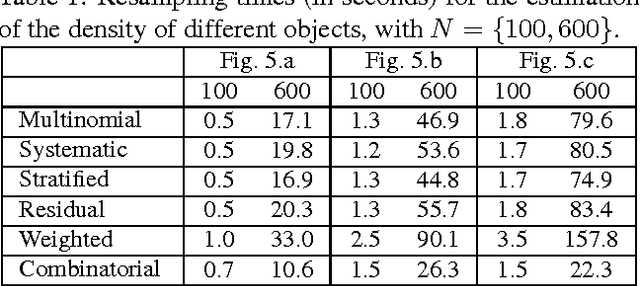
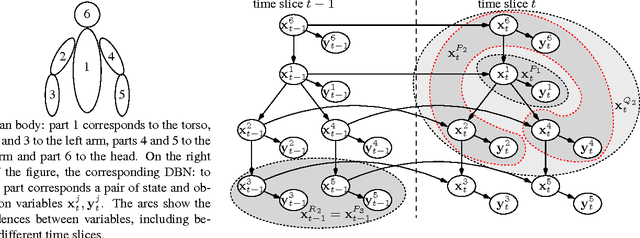
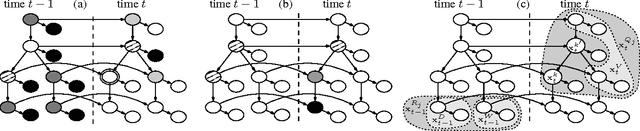
Particle Filter is an effective solution to track objects in video sequences in complex situations. Its key idea is to estimate the density over the possible states of the object using a weighted sample whose elements are called particles. One of its crucial step is a resampling step in which particles are resampled to avoid some degeneracy problem. In this paper, we introduce a new resampling method called Combinatorial Resampling that exploits some features of articulated objects to resample over an implicitly created sample of an exponential size better representing the density to estimate. We prove that it is sound and, through experimentations both on challenging synthetic and real video sequences, we show that it outperforms all classical resampling methods both in terms of the quality of its results and in terms of response times.